TypeScript 由微软在 2012 年 10 月首发,经过几年的发展,已经成为国内外很多前端团队的首选编程语言。前端三大框架中的 Angular 和 Vue 3 也都改用了 TypeScript 开发。即使很多人没直接用过 TypeScript,他们也在通过 VSCode 提供的智能提示功能间接享受着 TypeScript 带来的各项便利。推荐一下电子书深入理解 TypeScript,虽然没看完,一定会抽空阅读。也有大佬们写好的总结,淡如止水 TypeScript,打算也偷偷复制一份。
很多人对 TypeScript 背后的原理很感兴趣,你可能想要:
- 更好地理解 TypeScript;
- 学习编译原理相关的知识来丰富自己(编译器和操作系统是很多程序员的梦想);
- 设计一门类似的语言;
- 定制自己的打包工具;
- 做一个 VSCode 插件。
但你上网搜索,你会发现能搜到的全是 TypeScript 如何使用的教程,即使是英文的资料,也鲜有能完全讲解清楚 TypeScript 内部原理的文章。
只有少数的几篇教程会在文末稍微附带一下原理说明,但它们只是大概阐述了一下 TypeScript 的整体架构,最核心的类型分析的具体实现几乎都是一句带过。
能真正了解 TypeScript 内部原理的人极少,多数人对 TypeScript 的想法是:“这方面的东西和我工作没啥关系,我只管能用就行!”(其实内心的想法是:这东西好烦啊!为什么大家都在用?求你别加功能了,学不动了……)
既然你读到这里了,说明你真的想学习 TypeScript 的内部原理。这篇系列文章不教你如何使用 TypeScript(那种你网上随便一搜,很多),我假设你已经熟悉了 TypeScript 的各种语法,文中不会介绍这些语法的功能,也不探讨这些语法的好坏,只重点介绍 TypeScript 是如何实现这个语法的功能的。这篇系列文章可以帮助你在没学过编译原理之类的书的前提下,真正地学会编译相关的知识。但你必须先做好两点准备:1. 检查这个页面的网址,这篇系列文章由徐林迪(xuld)原创,前三篇在博客园首发,禁随意转载、偷爬,如果需要引用文章内容,请直接链接到这篇文章的地址,不要复制内容。2. TypeScript 核心编译器截止目前一共有 8 万行以上代码,GIT 源码仓库 超过 1 G,学习 TypeScript 原理是一个漫长的过程,不是几天就可以搞定的,你需要静下心来,而且原理中包含了大量抽象的逻辑,如果你不打算用太久时间,请尽早放弃。
如果有天你问一个“高手”,TypeScript 是怎么写的,“高手”就回复你一句“你去看编译原理的书,比如某某动物书”,那我可以很肯定地告诉你,你的那位“高手”也不懂 TypeScript 的原理。要实现一个 TypeScript ,确实需要一些编译原理的知识,但并不多,TypeScript 的核心是类型分析、流程分析、ES5 语法转换,而这些东西,在传统的 C 编译器之类的领域都是不存在的。所以你去读那些教你怎么写 parser,怎么编译成机器码的传统编译原理的书,是远远不够的。
1.总览
理解 TypeScript 项目
TypeScript 的核心设计者之一也是 C#(念 C 井的请注意了——你的英文能力可能会增加你学习 TypeScript 原理的困难度),Pascal 的核心设计者,TypeScript 有很多地方都借鉴了 C# 的实现,也逐渐给 JavaScript 增加了以前只有 C# 才有的功能。
TypeScript 在微软拥抱开源的大政策下,和社区有良好的互动,我曾经给 TypeScript 提过三个 BUG,TypeScript 团队都能在当天回复,并且在下一个版本中立即修复了。
TypeScript 的目标是:
- 兼容所有 JavaScript 语法,并在此基础扩展语法;
- 静态分析代码,找出那些很有可能有 BUG 的代码;
- 生成纯净的、可读的 JavaScript 代码,并且不会对代码作任何优化、处理,甚至连源码中的错误都保留到生成的代码中;
- 不影响最后运行代码的环境。
静态分析代码是 TypeScript 的主要职责,通过静态分析,我们可以得到这些功能:
- 开发中提前知道代码中的可能错误
- IDE 中的语法高亮、智能提示、转到定义等功能
- 重命名变量、提取函数、自动添加导入等高级功能
但对于动态脚本语言来说,静态分析是无法做到 100% 准确的,TypeScript 的策略是平衡正确性和实用性。TypeScript 不会确保每处静态分析的结果都是正确的,而是多数情况都是正确的,但他们也提供了两个应对少数情况的解决方案:1. 提供语法允许用户手动修复静态分析的结果(比如用你熟悉的 any)2. 即使源码中存在错误,也可以正常编译。从使用者的角度,只要你不是故意找茬,一般也不会碰到问题。关于正确性和实用性的平衡,你在读后续教程时将会有更深的体会。
项目结构
TypeScript 的项目结构如下:
1 | ├── bin 最终给用户用的 tsc 和 tsserver 命令 |
TypeScript 编译器的核心代码在 src/compiler,其中以下文件是研究的重点(已经按阅读顺序排序):
1 | ├── core.ts |
核心部分的架构如图:

编译流程
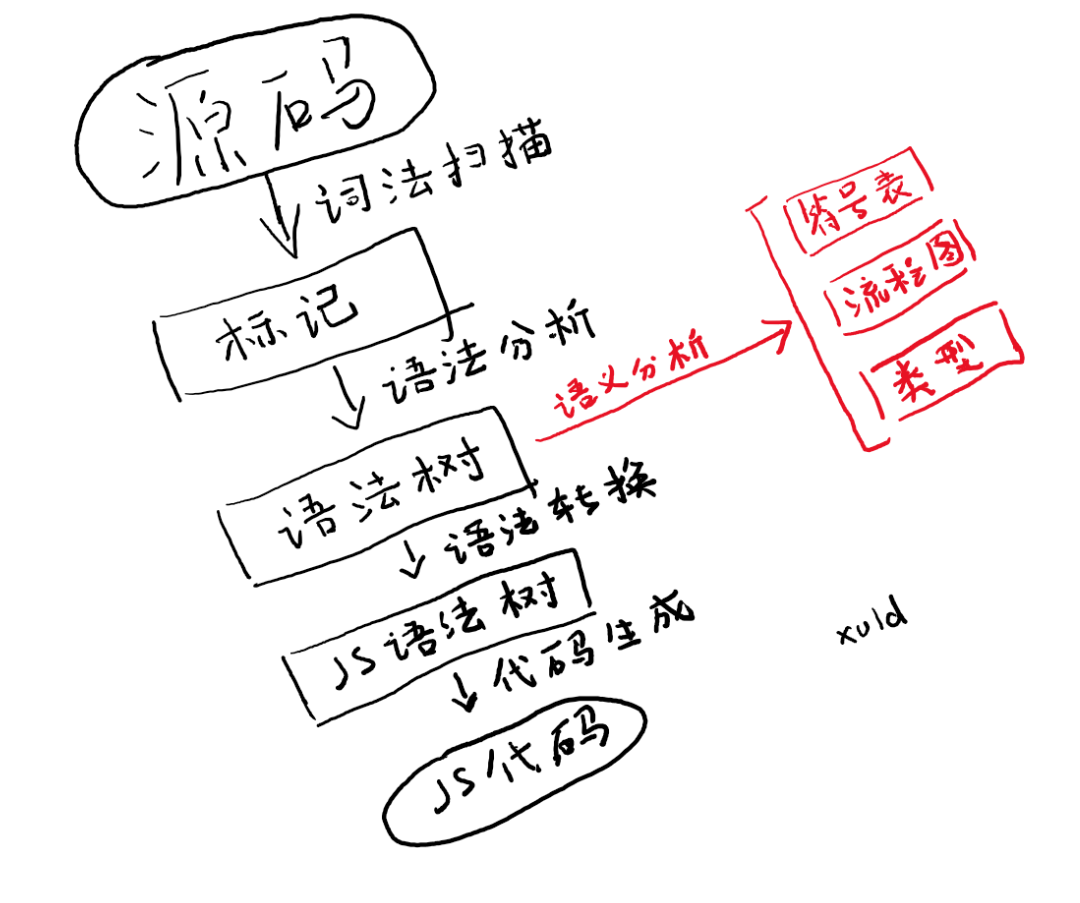
TypeScript 编译器的目标是把 TypeScript 编译成 JavaScript,这其实和把“英文”翻译成“中文”没有任何区别。
当我们在翻译一段英文到中文时,要做这些事情:
- 理解原文的意义。
- 将原文的意思用中文重新表述出来。
说的再具体一些,是这样的流程:
- 识别原文中的单词、短语;
- 将这些单词和短语组成一个句子。
- 参考这个句子所阐述的意义,将原文中的单词和短语全部换成中文的词语;
- 用中文的语法将这些词语重新组装成一个句子。
所以编译器也在做同样的事情,只不过每个步骤我们都给他一个专业的称呼。
1. 组词——词法分析
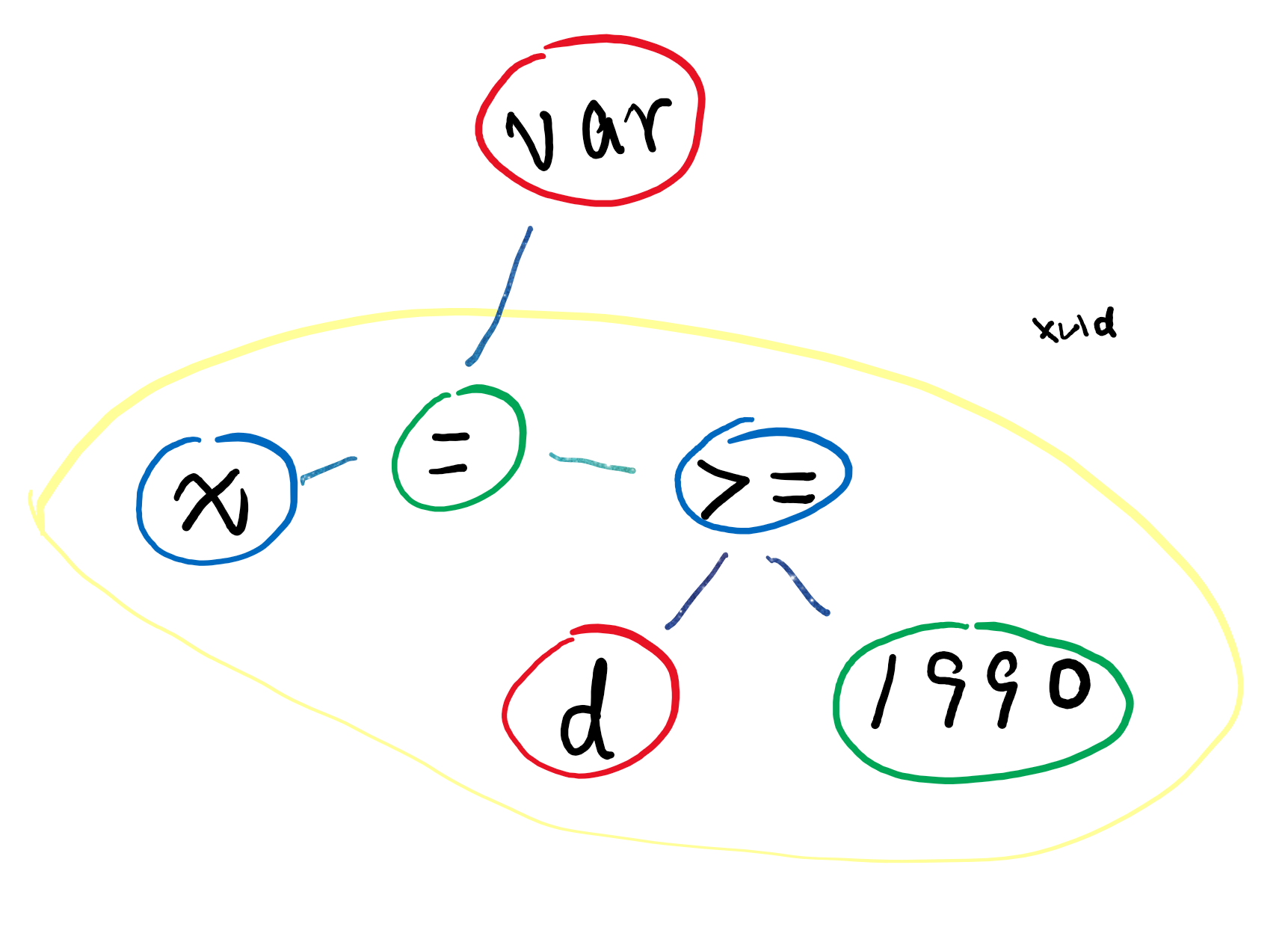
比如句子“我在2009首次创办个人网站”中的个,我们在理解时,会自然地将“个人”连在一起,而不是将“办个”连在一起。这就是一个组词的过程。这个句子组词后的结果如图:

TypeScript 是英文编程语言,编译器的组词流程,即将字母拼成单词:
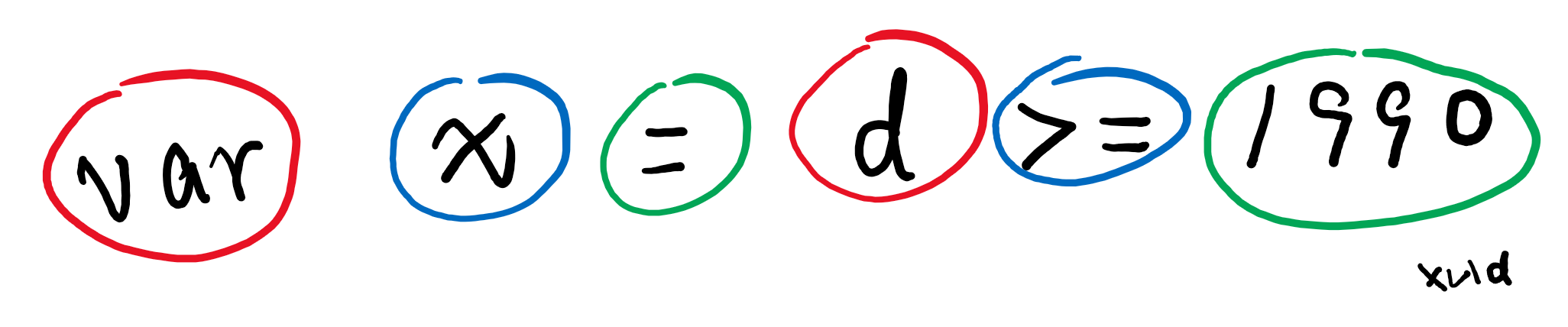
这个过程中,还会跳过代码中的注释、空格,拆出来的词有关键字、有变量名、有数字、也有符号,这些我们统称为标记(Token)。
解析标记列表的过程称为词法分析,也叫词法扫描,TypeScript 源码中 scanner.ts 负责完成词法扫描。
2. 组句——语法解析
比如句子“我在2009首次创办个人网站”,在词数有限时怎么说和原文意义最接近?结果是——“我创办网站”。你会发现,“在2009”、“首次”是用于修饰“创办”的,“个人”是用于修饰“网站”的,一个句子里面,总是先由一些词构成句子的基本结构,然后再添加其它词使得句子变得更丰富起来,每个词有不同的重要等级。“我”,“创办”,“网站”是一级词,“在2009”、“首次”和“个人”是修饰用的二级词。
如上图,一个句子是由有上下级关系的词组成的一个树结构。什么是树结构?树结构就是指先有一个根节点,然后这个节点下面有很多子节点,每个子节点下面又有很多其它子节点(就像中国有很多省,每个省下面有很多市,市下面有你的村)。
在编译器中,将最后语法解析得到的结果称为语法树,TypeScript 源码中 parser.ts 负责解析语法生成语法树。
语法树的根节点代表一份源码文件,根节点下面有很多语句,语句即代码中需要用分号隔开的部分(一般一行一个语句),每个语句下面可能还嵌套了别的语句(比如一个函数,内部包含别的语句)。
如果你之前完全没学过编译原理,你可能对语法树还不能很好的理解,没关系,等到第4节的时候,我会更详细地介绍。
如果你之前有学过编译原理相关的东西,你会觉得上面这些讲的太简单了,那准备好了,接下来的内容,是你在其它地方很难学到的东西。
3. 提取符号表——作用域分析
比如句子“我在2009首次创办个人网站,这个网站到现在都还在维护”,其中的“这个”是一个代词,指代前面出现过的词。平时我们也经常使用代词,甚至有的时候连代词都省略了(比如你的女朋友一开始会跟你说“你滚!”,后来,变成了“滚!”)。在谈话中我们需要记住一些概念的定义,才能理解后续的代词的含义(比如你先得记住前半句提到的个人网站,然后才能理解后面的“这个网站”的含义)。
在代码中,变量是非常常见的,一个变量名称可能指代了一个值、一个函数,或者一个类,这些统称为符号(Symbol)。
当用户定义一个变量、函数或类时,就同时定义了一个符号。编译器会先将所有的符号收集起来,建立符号表。当在其他地方使用一个名称时,就查表找出这个名称所代表的符号。
在同一个函数中,不能定义两个同名的变量,但可以定义一个变量和上层的变量重名。函数有一个符号表,其外层也有一个符号表,两个符号表是上下级关系。在函数内部使用一个名称,会先在函数对应的符号表搜索,如果找不到再在外层的符号表继续搜索,如果都找不到就报告:“变量未定义”。
拥有符号表的区域成为词法作用域(Lexical Scope),比如一个源文件、一个函数、一个语句块({})都是一个作用域。在同一个作用域中,不允许有同名的符号,但两个作用域可以存在同名的符号。

TypeScript 源码中 binder.ts 负责解析作用域,创建符号表。
4. 提取流程图——流程分析
在代码 fn() + gn() 对应的语法树中,fn() 和 gn() 是相邻的两个节点,在执行的时候,它们是有先后顺序的,按每行代码的执行顺序,可以绘制出一份执行流程图。为什么称为流程图而不是流程树?因为习惯上就这么叫——如果回答真这么简单,那你高考咋不考个满分?图——是数学中的专业术语,图和树类似,都是由多个节点及它们之间的关系组成的结构,树结构是一级一级层层向下的,两个节点之间的上下级关系是明确的。如果存在两个节点存在互为上下级关系(即循环引用),那就变成了图。
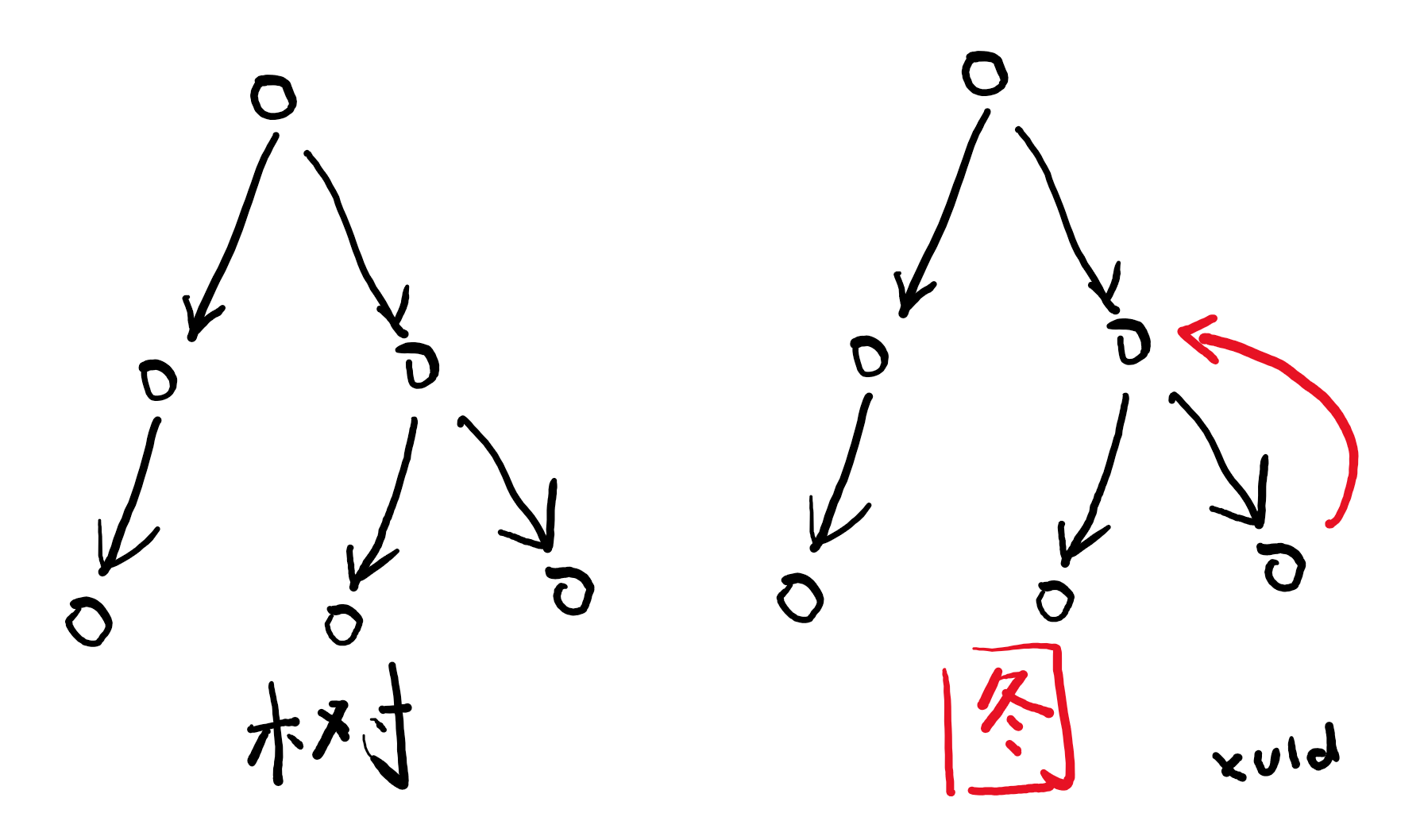
代码中存在循环,在执行的时候,可能存在回到之前执行过的节点的情况,所以称为流程图。
分析流程图有什么用?
- 检测代码中的永远不会执行的代码(比如在 return 之后或者 while(true) 死循环之后的代码)(这些代码在 VSCode 会通过减淡的方式显示)
- 通过流程分析推导变量的类型,比如出现 if (typeof x === “number”) ,就可以知道 if 内部,x 的类型是数字。

5. 检查类型错误——语义分析
比如句子“我是你爹”,从语法上是没有错的,它确实表达出了一个意思,但这个意思你可能认为是不对的,这就叫语义错误。
比如 var x = null; x.toString(); 从语法上是正确的代码,可以执行,但执行的时候会发现 x 是空,然后就报错了。
语义分析的目的就是在不执行代码的前提下找出可能在执行过程中出错的代码。
你可能会想,为什么不直接执行代码,执行一下代码错误不就出来了吗?假如你正在哈皮地码代码的时候,还没等你测试,它就已经开始工作——并且删除了你珍藏多年的电影——你会不会奔溃?因为 VSCode 需要有实时分析错误的功能,它为了分析错误,把你写到一半的代码直接拿来执行了……
语义分析的错误种类很多,比如:
- 给 const 变量赋值
- 调用函数时少了一个参数
- 一个类继承了自己
- ……
TypeScript 源码中 checker.ts 负责语义分析。checker.ts 的行数超过 3 万,也将是本篇系列文章中重点研究的对象。
6. 语法转换——代码优化
TypeScript 提供了编译成 JavaScript 的功能,而且可以编译成 ES3、ES5、ES2020 等不同版本的代码。
要实现这个功能,就必须先将 TypeScript 代码翻译为 ESNext 的语法(即删除所有类型信息),如果用户需要的是旧版本的语法,再将 ESNext 中旧不版本不支持的语法替换掉。
每次转换都是通过一个转换器(Transformer)实现的,转换器的输入是语法树,输出是新的语法树。每个转换器就像工厂里的一道加工流程,原料在流水线被不断加工并最后包装成产品。输入的原始的 TypeScript 语法树也会被不同的转换器处理,最后得到标准的 JavaScript 语法树。
TypeScript 内置了 TS→ESNext、ES7→ES6、ES6→ES5、ES5→ES3 等转换器,用户也可以开发自己的转换器,生成更实用的代码。
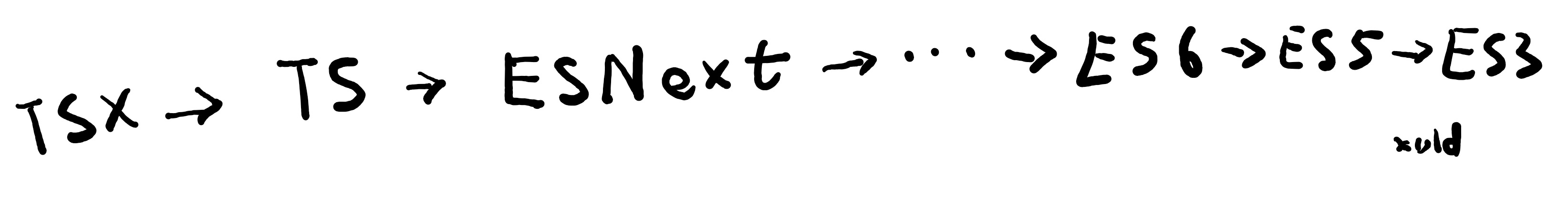
TypeScript 源码中 transformer.ts 负责语法转换,不同的转换器源码则在 transformer 文件夹。
7. 写入文件——代码生成
经过以上步骤后,现在已经得到了一个最终的语法树,接下来要做的事情很简单——将语法树重新拼装回代码,并保存到文件。
TypeScript 为了保证对代码的影响最少,生成最终代码时还会保留源代码的注释,同时对齐了缩进。
TypeScript 源码中 emitter.ts 负责生成代码。
此外,TypeScript 还会同时生成源映射(Source Map),以及类型描述文件(.d.ts),这些都将在相关章节详细介绍。
8. 小结
完整的编译流程如图:
2.词法1-字符处理
字符
任何源码都是由很多字符组成的,这些字符可以是字母、数字、空格、符号、汉字等……
每一个字符都有一个编码值,比如字符“a”的编码值是97,字符“林”的编码值是26519。
每个字符对应的编码值是多少是由编码表决定的,上面所示的编码值是全球统一的编码表 Unicode 中的编码值,如果没有特别声明,所有编码值都是以 Unicode 为准的。
一般地,字符的编码值都是有序的,比如字符“a”的编码值是97,字符“b”的编码值是98,字符“c”的编码值是99,汉字则是按照笔划顺序排序的。在给字符串排序时,也是根据每个字符的编码值大小进行排序的。
如果想要判断一个字符是不是英文字母,只需要判断这个字符的编码值是否位于字符“a”的编码值和字符“z”的编码值之间即可。
在 JavaScript 中,可以通过 “a”.charCodeAt(0) 获取字符“a”的编码值;通过 String.fromCharCode(97) 获取指定编码值对应的字符。
CharacterCodes 枚举
在代码中如果直接写 99,你可能不清楚这个数字的含义,但如果写成 CharacterCodes.c,你就可以很快明白。通过枚举给每个编码值定义一个名称,方便读者理解,同时我们也不需要去记忆每个字符的实际编码值。CharacterCodes 枚举位于 tsc/src/compiler/types.ts,源码如下:
1 | /* @internal */ |
字符判断
要判断一个字符是不是数字字符,只需确认它的字符编码是不是在“0”和“9”的编码值之间:
1 | function isDigit(ch: number): boolean { // 参数 ch 表示一个编码值 |
同理,还可以判断其它字符,比如判断是不是换行符:
1 | export function isLineBreak(ch: number): boolean { |
根据 ES 规范,换行符一共有 4 个,虽然平常我们只使用前两个,但对有些语言来说,后两个也是需要的。
判断是不是空格:
1 | export function isWhiteSpaceLike(ch: number): boolean { |
有的地方需要把换行当空格处理,有的地方不需要,所以 TypeScript 拆成两个函数,一个包括换行符,一个不包括。
判断标识符(Identifier)
标识符即俗称的变量名,我们都知道 JS 中变量名是不能随便取的,是有规则的,比如开头不能是数字。
在 ES 规范中,明确地点名了:哪些字符可以做标识符;哪些字符可以做标识符但不能以它开头。TypeScript 实现了 isUnicodeIdentifierStart 和 isUnicodeIdentifierPart 来分别判断。
哪些字符可以做标识符,其实是没有简单的规律的,这些都是在 ES 规范一个个手动指定的,规范中这个列表很长,最简单的实现就是:手动记录每个字符是否允许作标识符,然后查表。
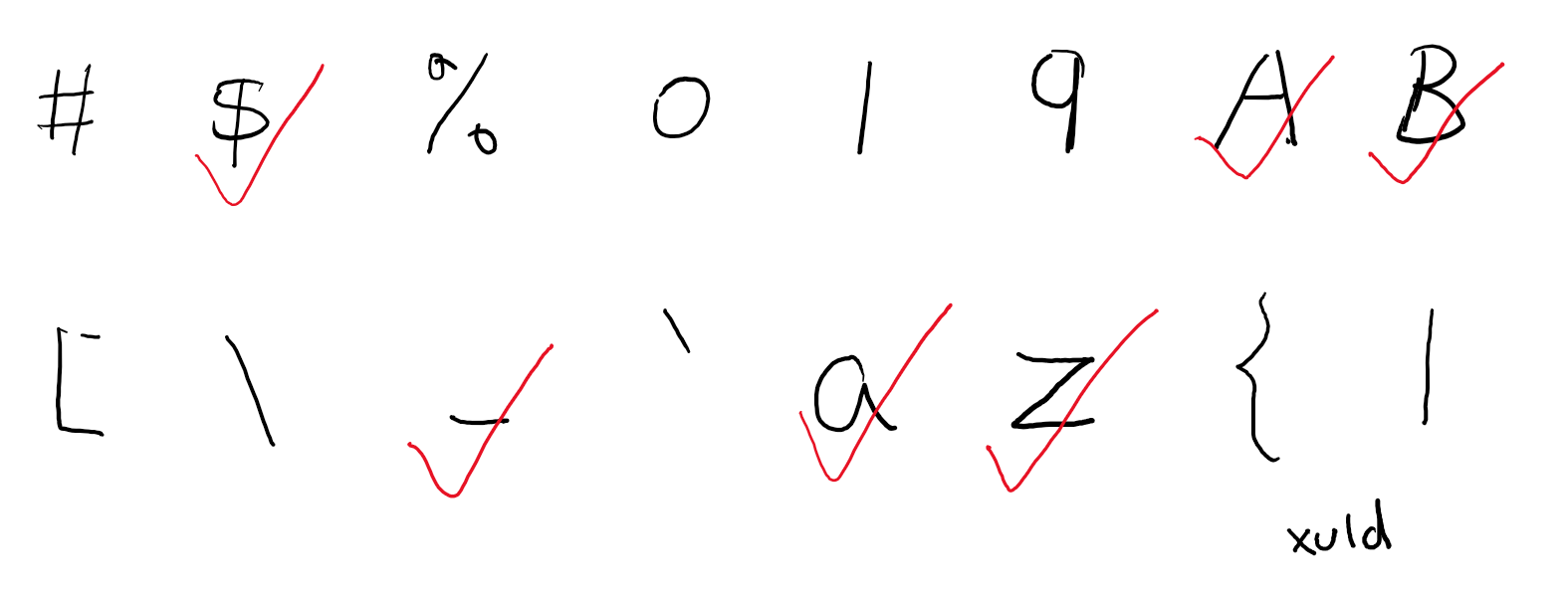
不过字符很多,每个字符单独记录要占用很大空间,所以 TypeScript 设计了一个小算法来压缩内存,算法基于这么一个事实:一般地,允许作为标识符的字符都是连续的一段(比如“a”到“z”)。
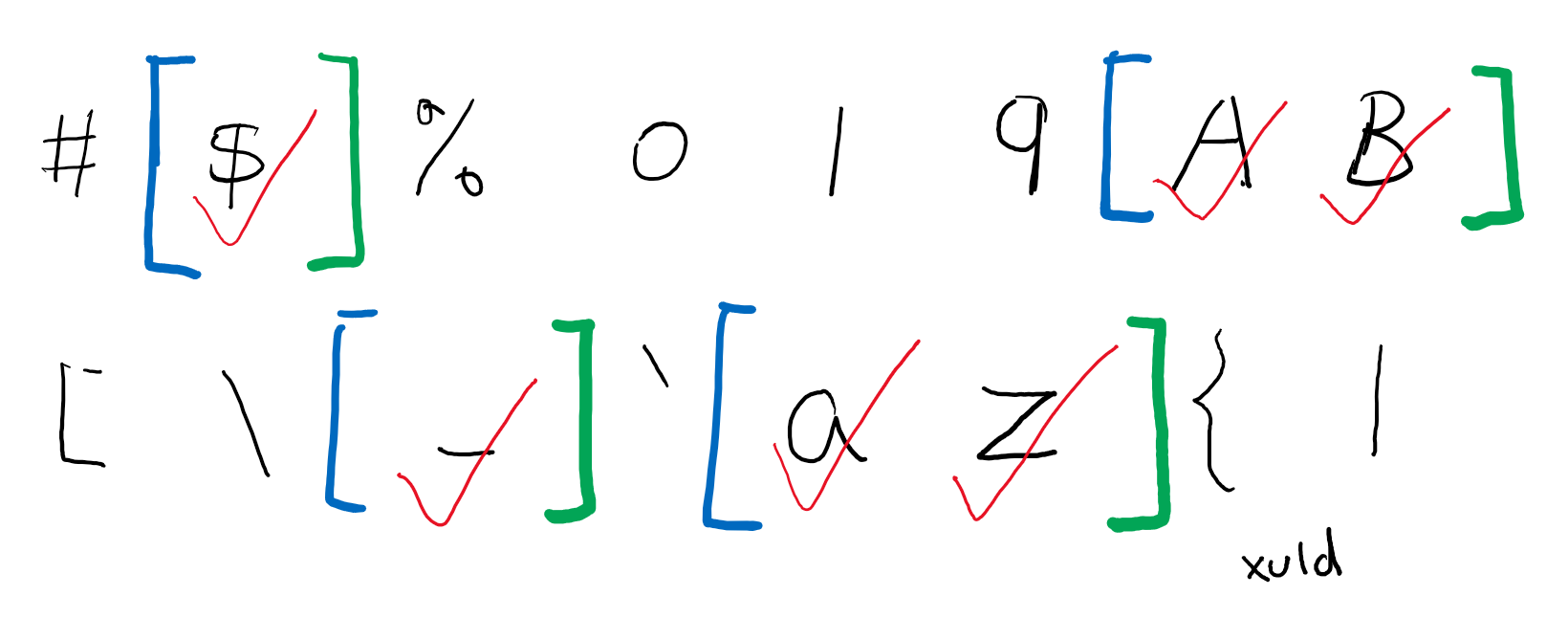
只要记录每段的开头和结尾部分,就可以比原先的记录该段的所有字符,要更节约内存。
将所有开始位置和结束位置放在同一个数组,数组的奇数位即图中的蓝色段,表示每段开头,偶数位即绿色段,表示每段结尾。
当需要查找一个字符是不是标识符时,采用二分搜索算法,快速定位确认它是否在包含的段中。
1 | const unicodeESNextIdentifierStart = [65, 90, 97, 122, 170, /*...(略) */, 194560, 195101] |
接下来就可以看明白 isUnicodeIdentifierStart 和 isUnicodeIdentifierPart 这两个函数了
1 | /* @internal */ export function isUnicodeIdentifierStart(code: number, languageVersion: ScriptTarget | undefined) { |
由于 TypeScript 支持不同版本的 ES 代码,且不同版本的 ES 规范对标识符的定义有细微查表,所以 TypeScript 内部准备了不同版本的表。
通过以上俩函数的结合,也就可以判断一个字符串是不是合法的标识符了:
1 | /* @internal */ |
行列号和索引
如果将源码看成字符串,每个字符都有一个字符串的下标索引,同时这个字符又可以理解为源码中的第几行第几列。
给定一个字符串的索引,可以通过扫描这个索引之前有几个换行符确定这个索引属于第几行第几列,反过来,通过行列号也可以确认这个位置对应的字符串索引。
在源码中如果发现一个错误,编译器需要向用户报告错误,并明确指出位置,一般地,编译器需要将错误的行列报出来(如果报的是索引那你自己慢慢数……),为了能够在报错时知道这些位置,编译器在词法扫描阶段就需要保存一切源码位置了,那编译器存的是行列号还是索引呢?
有的编译器选择了存行列号,因为行列号才是用户最后需要的,但行列号意味着需要两个字段存储这个信息,如果将它们分别处理,每次处理行列号的地方都需要两行代码,如果将它们合并为一个对象,这在 JavaScript 引擎中会造成大量的引用对象,影响性能。因此 TypeScript 选择:存储索引。出错的时候,再将索引换算成行列号显示出来。
TypeScript 用 Position(位置)这个术语表示索引,用 LineAndCharacter(行和字符)这个术语表示行列号。这三者都是从 0 开始计数的,即 line = 0 表示第一行。
为什么是 LineAndCharacter 而不是 LineAndColumn(行列),主要为了和 VSCode 中的 LineColumn 区分,多数情况,LineAndCharacter 和 LineAndColumn 是一样的,除非碰到制表符(TAB)缩进,一个 TAB 始终是一个字符,但它可能跨越 2 列、4 列、8列等(具体根据用户配置)。TypeScript 并不在意 TAB 这个字符,统一将它当一个字符处理可以简单许多,所以为了避免和 VSCode 的行列混淆,改用了别的称呼。
基于索引计算行列号需要遍历这个索引之前的所有字符,为了加速计算,TypeScript 作了一个小优化:缓存每行第一个字符的索引,然后通过二分搜索查找对应的行列(又是二分?)
首先计算每行第一个字符的索引表:
1 | /* @internal */ |
然后检索索引表查询行列号:
1 | /* @internal */ |
同时使用索引表也可以实现从行列号查询索引:
1 | /* @internal */ |
小结
本节介绍了 scanner 中的一些独立函数,这些函数都将被词法扫描程序中调用。先独立理解了这些概念,对完全理解词法扫描会有重大帮助。
3.词法2-标记解析
上一节主要介绍了单个字符的处理,现在我们已经有了对单个字符分析的能力,比如:
- 判断字符是否是换行符:isLineBreak
- 判断字符是否是空格:isWhiteSpaceSingleLine
- 判断字符是否是数字:isDigit
- 判断字符是否是标识符(变量名):
- 标识符开头部分:isIdentifierStart
- 标识符主体部分:isIdentifierPart
- 同时还可以通过 char === CharacterCodes.hash 方式判断其它字符
接下来,需要利用字符组装标记。
标记(Token)
标记可以是一个变量名、一个符号或一个关键字。
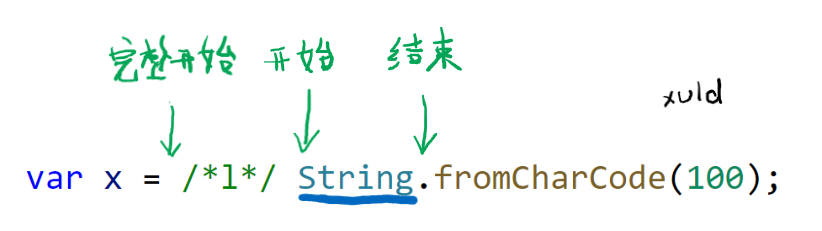
比如代码 var x = String.fromCharCode(100); 中,一共可解析出以下标记:
- var 关键字标记
- 标识符标记(内容是 x)
- 等号标记(=)
- 标识符标记(内容是 String)
- 点标记(.)
- 标识符标记(内容是 fromCharCode)
- 左括号标记(()
- 数字标记(内容是 100)
- 右括号标记())
- 分号标记(;)

为什么有些字符会组成一个标记,而有些字符又不行呢?
可以这么理解:标记里的字符一定是不能拆开的,就像“东西”这个词是一个最小的整体,如果拆成两个字,就不能表达原来的意思了。
比如代码 0.1.toString 中,包含以下标记:
- 数字标记(0.1)
- 点标记(.)
- 标识符标记(内容是 toString)
前面的点紧跟数字,是小数的一部分,所以和数字一起作为一个标记。当点不紧跟数字时,也可以作独立标记使用。
代码中的字符串,不管内容有多长,都将被解析为一个字符串标记。
++ 是一个独立的加加标记,而 + + (中间差一个空格)是两个加标记。
为什么标记需要按这个规则解析?因为 ES 规范就这么规定的。在英文编程语言中,一般都是用空格来分割标记的,两个标记如果缺少空格,它们可能被组成新的标记。当然并不是随便两个字符就可以组成新标记,比如 !! 和 ! ! 都被解析成两个感叹号标记,因为根本不存在双感叹号标记。
关键字和普通的标识符都是一个单词,为什么关键字有特殊的标记类型,而其它单词统称为标识符呢?
主要为了方便后续解析,之后判断单词是否是关键字时,只需判断标记类型,而不是很麻烦地先判断是否是标识符再判断标识符的内容。
每个标记在源码中都有固定的位置,如果将源码看成字符串,那么这个标记第一个字符在字符串中的索引就是标记的开始位置,最后一个字符对应的就是结束位置。
在解析每个标记时,会跳过标记之间的空格、注释。如果把每个标记之前、上一个标记之后的空格、注释包括进来,这个标记的位置即标记的完整开始位置。一个标记的完整开始位置等同于上一个标记的结束位置
综上,任何源码都可以被解析成一串标记组成的数组,每个标记都有这些属性:
- 标记的类型(区分这是关键字、还是标识符、还是其它的符号)
- 标记的内容(针对标识符、字符串、数字等标记类型,获取其真实的内容
- 标记的开始位置
- 标记的结束位置
- 标记的完整开始位置
在 TS 源码中,用 SyntaxKind 枚举列出了所有标记类型:
1 | export const enum SyntaxKind { |
同时,这些标记类型的值也有一个约定,即关键字标记都被放在一起,这样就可以很轻松地通过标记类型判断是否是关键字:
1 | export function isKeyword(token: SyntaxKind): boolean { |
同理还有很多的类似判断,它们被放在了 tsc/src/compiler/utilities.ts 中。
TS 内部统一使用 SyntaxKind 存储标记类型(SyntaxKind 本质是数字,这样比较起来性能最高),为了方便报错时显示,TS 还内置了从文本内容获取标记类型和还原标记类型为文本内容的工具函数:
1 | const textToToken = createMapFromTemplate<SyntaxKind>({ |
扫描器(Scanner)
一份代码中,一般会解析出上千个标记。如果将每个标记都存下来就会消耗大量的内存,而就像你读文章时,你只要盯着当前正在读的这几行字,而不需要将全文的字都记下来一样,解析代码时,也只需要知道当前正在读的标记,之前已经理解过的标记不需要再记下来。所以实践上出于性能考虑,采用扫描的方式逐个读取标记,而不是一口气将所有标记先读出来放在数组里。
什么是扫描的方式?即有一个全局变量,每调用一次扫描函数(scan()),这个变量的值就会被更新为下一个标记的信息。你可以从这个变量获取当前标记的信息,然后调用一次 scan() ,再重新从这个变量获取下一个标记的信息(当然这时候不能再读取之前的标记信息了)。
Scanner 类提供了以上所说的所有功能:
1 | export interface Scanner { |
如果你已经理解了 Scanner 的设计原理,那就可以回答这个问题:如何使用 Scanner 打印一个代码里的所有标记?
你可以先思考几分钟,然后看答案:
以下是可以直接在 Node 运行的代码,你可以直接断点调试看 TS 是如何完成标记解析的任务的。
1 | const ts = require("typescript") |
扫描器实现
TS 早期是使用面向对象的类开发的,从 1.0 开始,为了适配 JS 引擎的性能,所有源码已经没有类了,全部改用函数闭包。
1 | export function createScanner(languageVersion: ScriptTarget, skipTrivia: boolean, /**...(略) */): Scanner { |
核心的扫描函数如下:
1 | function scan(): SyntaxKind { |
扫描的步骤很简单:先判断是什么字符,然后尝试组成标记。
标记的种类繁多,所以这部分源码也很长,但都是大同小异的判断,这里不再赘述(相信即使写了你也会快速跳过),有兴趣的自行读源码。
这里列出一些需要注意的点:
并不是所有字符都是源码的一部分,所以,可能在扫描时对有些字符报错。
最开头的 #! (Shebang)会被忽略(这部分虽然暂时没入ES 标准(发文时属于 Stage 2),但多数引擎都会忽略它)
为了支持自动插入分号,扫描时还同时记录了当前标记之前有没有换行的信息。
TS 很贴心地考虑 GIT 合并冲突问题。
如果一个文件出现 GIT 合并冲突,GIT 会自动在该文件插入一些冲突标记,如:
1 | <<<<<<< HEAD |
TS 在扫描到 <<<<<<< 后(正常的代码不太可能出现),会将这段代码识别为冲突标记,并在词法扫描时自动忽略冲突的第二段,相当于屏蔽了冲突代码,而不是将冲突标记看成代码的一部分然后报很多错。这样,即使代码存在冲突,当你在修改第一段代码时,不会受任何影响(包括智能提示等),但因为第二段被直接忽略,所以修改第二段代码不会有智能提示,只有语法高亮。
重新扫描问题
正则表达式和字符串一样,是不可拆分的一种标记,当碰到 / 后,它可能是除号,也可能是正则表达式的开头。在扫描阶段还无法确定它的真正意义。
有的人可能会说除号也可以通过扫描后面有没有新的除号(因为正则表达式肯定是一对除号)判断它是不是正则,这是不对的:
1 | var a = 1 / 2 / 3 // 虽然出现了两个除号,但不是正则 |
实际上需要区分除号是不是正则,是看除号之前有没有存在表达式,这是在语法解析阶段才能知道的事情。因此在词法扫描阶段,直接不考虑正则,除号可能是除号(/)、除号等于(/=)、注释(//)。
当在语法扫描时,发现此处需要的是一个独立的表达式,而不可能是除号时,调用 scanner.reScanSlashToken(),将当前除号标记重新按正则扫描。
类似地、< 可能是小于号,也可能是 JSX 的开头。模板 x${...} 中的 } 可能是右半括号,也可能是模板字面量的最后一部分,这些都需要在语法分析阶段区分,需要提供重新扫描的方法。
预览标记
TS 引入了很多关键字,但为了兼容 JS,这些关键字只有在特定场合才能作关键字,比如 public 后跟 class,才把 public 作关键字(这样不影响本来是正确的 JS 代码:var public = 0)。
这时,在语法分析时,就要先预览下一个标记是什么,才能决定如何处理当前的标记。
scanner 提供了 lookAhead 和 tryScan 两个预览用的函数。
函数的主要原理是:先记住当前标记和扫描的位置,然后执行新的扫描,读取到后续标记内容后,再还原成之前保存的状态。
1 | function lookAhead<T>(callback: () => T): T { |
lookAhead 和 tryScan 的唯一区别是:lookAhead 会始终还原到原始状态,而 tryScan 则允许不还原。
小结
本节主要介绍了扫描器的具体实现。扫描器提供了以下接口:
- scan() 扫描下一个标记
- getXXX() 获取当前标记信息
- reScanXXX() 重新扫描标记
- lookAhead() 预览标记
如果你觉得理解起来比较吃力,那告诉你个不幸的消息——词法扫描是所有流程中最简单的。
有些人可能想要开发自己的编译器,这里给个提示,如果你设计的语言采用缩进式语法,你在实现词法扫描步骤中,需要记录每个标记之前的缩进数(TAB 按一个缩进处理)。如果这个标记不在行首,缩进数记位 -1。在语法解析阶段,如果发现下一个标记的缩进比当前存储的缩进大,说明增加了缩进,更新当前存储的缩进。
TS 源码中的词法扫描是比较复杂但完整的一种实现,如果仅仅为了语法高亮,这点复杂的没必要的,对语法高亮来说,使用正则匹配已经足够了,这是另一种词法扫描方案。
TS 这部分源码有 2000 行多,相信领悟文中介绍的方法、概念之后,你可以自己读完这些源码。
4.语法1-语法树
上一节介绍了标记的解析,就相当于识别了一句话里有哪些词语,接下来就是把这些词语组成完整的句子,即拼装标记为语法树。
树(tree)
树是计算机数据结构里的专业术语。就像一个学校有很多年级,每个年级下面有很多班,每个班级下面有很多学生,这种组织结构就叫树。
- 组成树的每个部分称为节点(Node);
- 最顶层的节点(即例子中的学校)称为根节点(Root Node);
- 和每个节点的下级节点称为这个节点的子节点(Child Node,注意不叫 Subnode)(班级是年级的子节点);
- 反过来,每个节点的上级节点称为这个节点的父节点(Parent node)(年级是班级的父节点);
- 一个节点的子节点以及子节点的子节点统称为这个节点的后代节点(Descendant node);
- 一个节点的父节点以及父节点的父节点统称为这个节点的祖父节点(Ancestor node)。
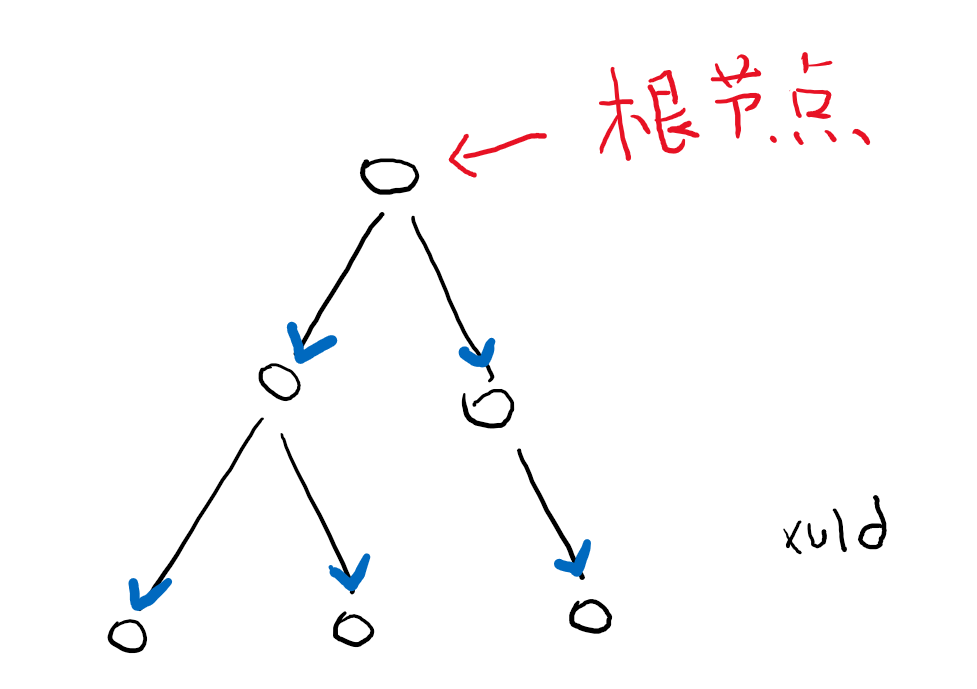
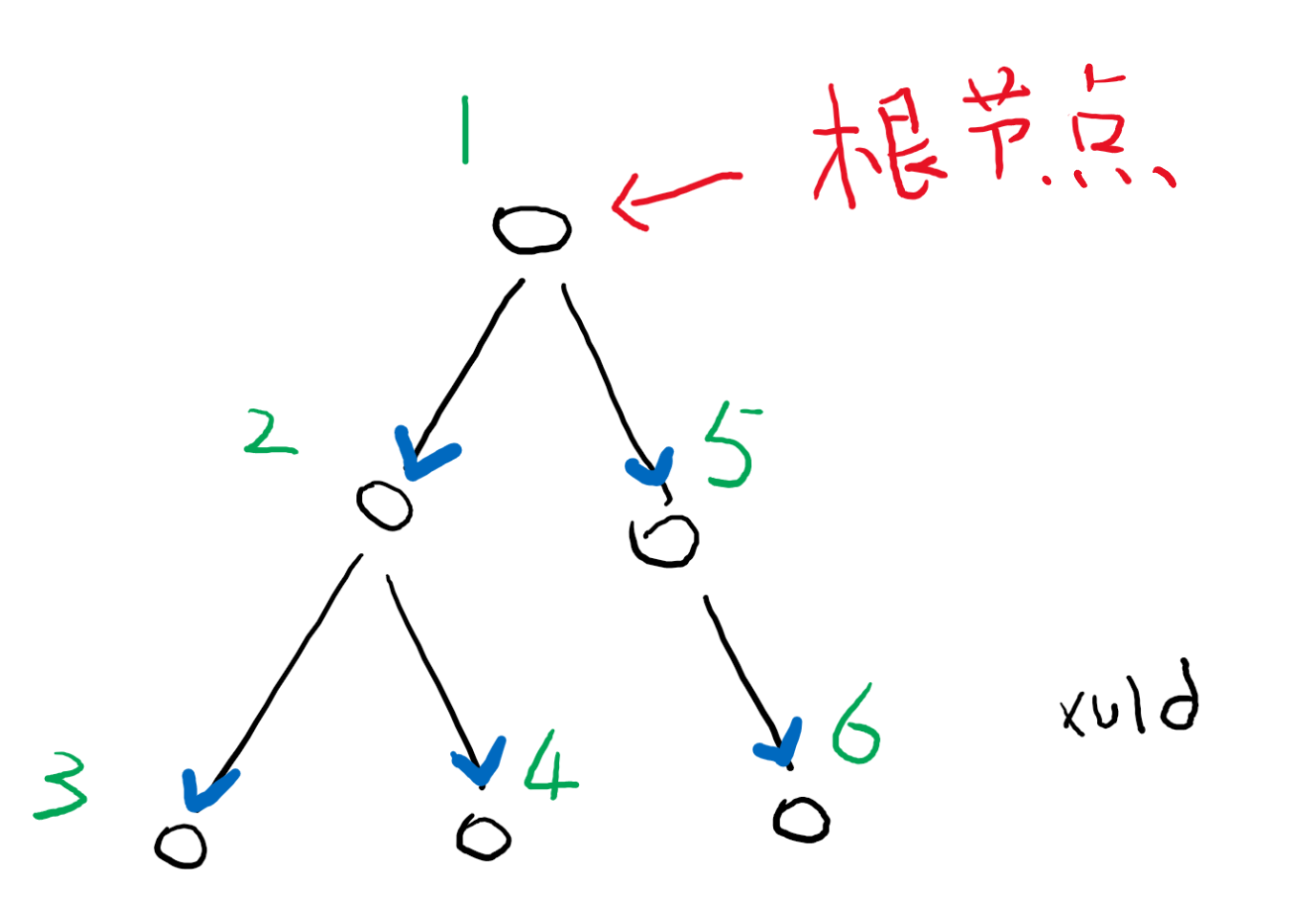
很多人一提到树就想起二叉树,说明你压根不懂什么是树。二叉树只是树的一种。二叉树被用的最多的地方在试卷,请忘掉这个词。
从树中的任一个节点开始,都可以遍历这个节点的所有后代节点。因为节点不会出现循环关系,所以遍历树也不会出现死循环。
遍历节点的顺序有有很多,没特别说明的话,是按照先父节点、再子节点,同级节点则从左到右的顺序(图中编号顺序)。
语法树(Syntax Tree)
语法树用于表示解析之后的代码结构的一种树。
比如以下代码解析后的语法树如图:
1 | var x = ['l', [100]] |
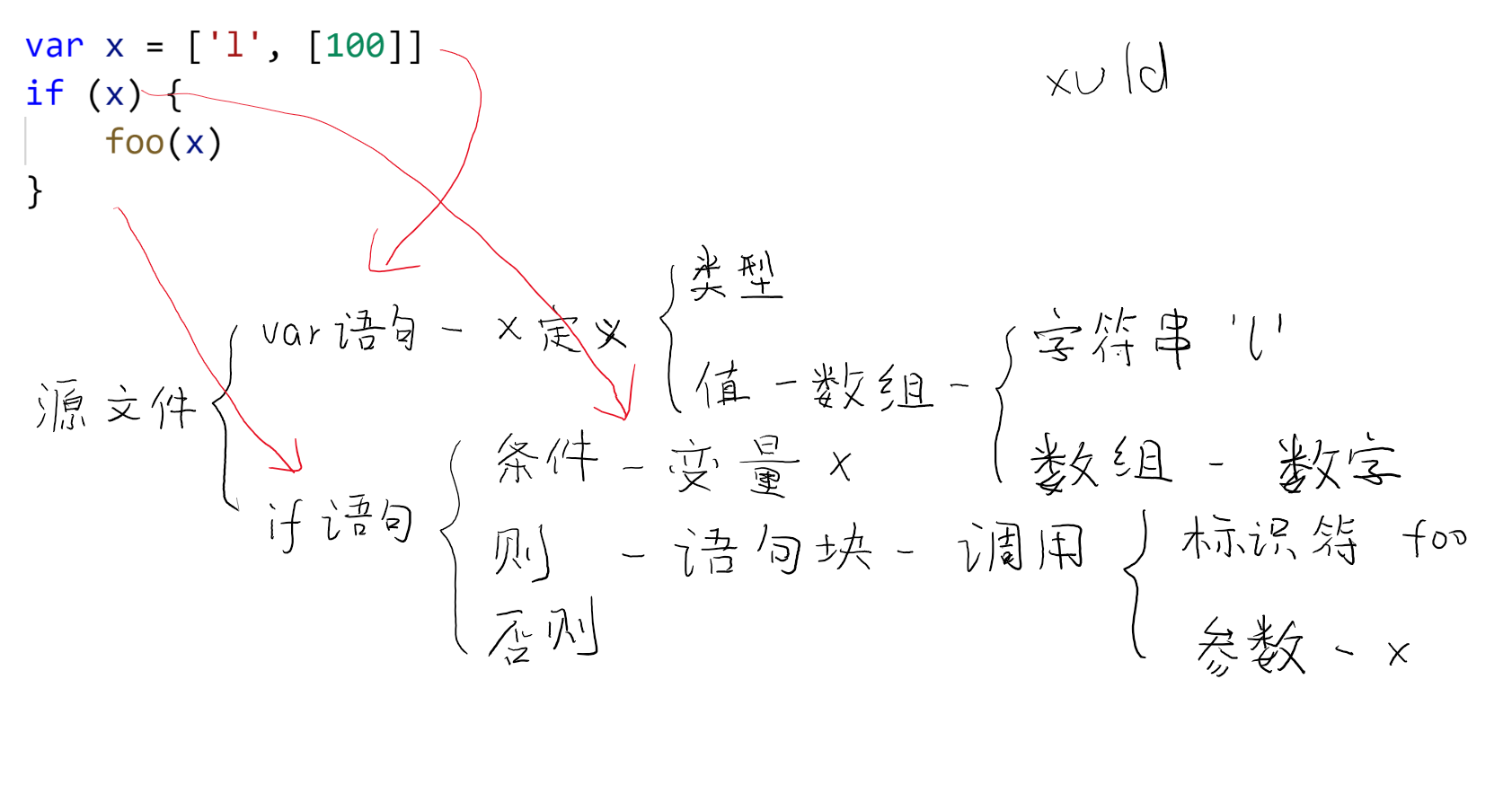
其中,源文件(Source File)是语法树的根节点。
语法树中有很多种类的节点,根据种类的不同,这些节点的子节点种类也会变化。比如:
- “if 语句”节点,只有“条件表达式”、“则部分”和“否则部分”(可能为空)三个子节点。
- “双目表达式(x + y)”节点,只有“左值表达式”和“右值表达式”两个子节点。
TypeScript 中,节点有约 100 种,它们都继承 “Node” 接口:
1 | export interface Node extends TextRange { |
Node 接口中 kind 枚举用于标记这个节点的种类。
TypeScript 将表示标记种类的枚举和表示节点种类的枚举合并成一个了(这可能也是导致很多人读不懂代码的原因之一):
1 | export const enum SyntaxKind { |
如果你深知“学而不思则罔”的道理,现在应该会思考这样一个问题:那到底有哪 100 种语法节点呢?
这里先推荐一个工具:https://astexplorer.net/
这个工具可以在左侧输入代码,右侧查看实时生成的语法树(以 JSON 方式展示)。读者可以在这个工具顶部选择“JavaScript”语言和“typescript”编译器,查看 TypeScript 生成的语法树结构。
为了帮助英文文盲们更好地理解语法类型,读者可参考:https://github.com/meriyah/meriyah/wiki/ESTree-Node-Types-Table
语法节点分类
虽然语法节点种类很多,但其实只有四类:
- 类型节点(Type Node):一般出现在“:”后面(var a: 类型节点),可以解析为一个类型。
- 表达式节点(Expression):可以计算得到一个值的节点,表达式节点只能依附于一个语句节点,不能独立使用。
- 语句节点(Statement):可以直接在最外层使用的节点,俗称的几行代码就是指几个语句节点。
- 其它节点:其它内嵌在表达式或语句节点的特定节点,比如 case 节点。
在 TypeScript 中,节点命名比较规范,一般类型节点以 TypeNode 结尾;表达式节点以 Expression 结尾;语句节点以 Statement 结尾。
比如 if 语句节点:
1 | export interface IfStatement extends Statement { |
鉴于有些读者对部分语法比较陌生,这里可以说明一些可能未正确理解的节点类型
表达式语句(ExpressionStatement)
1 | export interface ExpressionStatement extends Statement, JSDocContainer { |
表达式是不能直接出现在最外层的,但以下代码是允许的:
1 | var x = 1; |
因为 1 + 1 是表达式,它们同时又是一个表达式语句。所以以上代码的语法树如图:

常见的赋值、函数调用语句都其实是一个表达式语句。
块语句(BlockStatement)
一对“{}”本身也是一个语句,称为块语句。一个块语句可以包含若干个语句。
1 | export interface Block extends Statement { |
比如 while 语句的主体只能是一条语句:
1 | export interface IterationStatement extends Statement { |
但 while 里面明明是可以写很多语句的:
1 | while(x_d) { |
本质上,当我们使用 {} 时,就已经使用了一个块语句,while 的主体仍然是一个语句:块语句。其它语句都是块语句的子节点。
标签语句(LabeledStatement)
1 | export interface LabeledStatement extends Statement, JSDocContainer { |
通过标签语句可以为语句命名,比如:
1 | label: var x = 120; |
命名后有啥用?可以在 break 或 continue 中引用该名称,以此实现跨级 break 和 continue 的效果:
1 | export interface BreakStatement extends Statement { |
运算符的优先级
比如 x + y * z 中,需要先算乘号。生成的语法树节点如下:
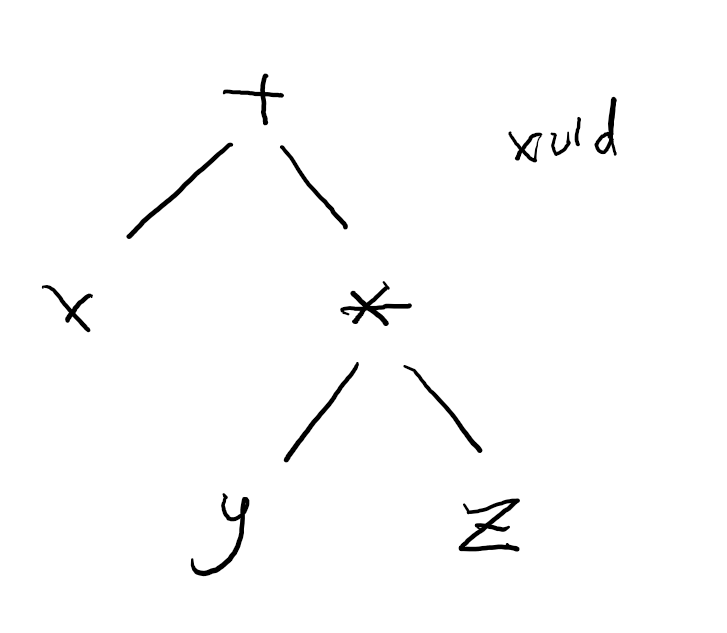
通过节点的层次关系,实现了这种优先级的效果(因为永远不会把图里的 x 和 y 先处理)。
因此创建语法树的同时,也就处理了优先级的问题,括号完全可以从语法树中删除。
类
一个复杂的类,也能用语法树表示?
当然,任何语法最后都是用语法树表达的,只不过类确实复杂一些:
1 | export interface Declaration extends Node { |
类、函数、变量、导入声明严格意义上是独立的一种语法分类,但鉴于它和其它语句用法一致,为了便于理解,这里把声明作语句的一种看待。
节点位置
当源代码被解析成语法树后,源代码就不再需要了。如果后续流程发现一个错误,编译器需要向用户报告,并指出错误位置。
为了可以得到这个位置,需要将节点在源文件种的位置保存下来:
1 | export interface TextRange { |
通过节点的 parent 可以找到节点的根节点,即所在的文件;通过节点的 pos 和 end 可以确定节点在源文件的行列号(具体已经在第二节:标记位置 中介绍)。
遍历节点
为了方便程序中遍历任意节点,TypeScript 提供了一个工具函数:
1 | /** |
forEachChild 函数只会遍历节点的直接子节点,如果用户需要递归遍历所有子节点,需要递归调用 forEachChild。forEachChild 接收一个函数用于遍历,并允许用户返回一个 true 型的值并终止循环。
小结
掌握语法树是掌握整个编译系统的基础。你应该可以深刻地知道语法树的大概样子,并清楚每种语法的语法树结构。如果还没有彻底掌握,可以使用上文推荐的工具
5.语法2-语法解析
上一节]介绍了语法树的结构,本节则介绍如何解析标记组成语法树。
对应的源码位于 src/compiler/parser.ts。
入口函数
要解析一份源码,输入当然是源码内容(字符串),同时还提供路径(用于报错)、语言版本(比如ES3 和 ES5 在有些细节不同)。
createSourceFile 是负责将源码解析为语法树的入口函数,用户可以直接调用:比如 ts.createSourceFile(‘<stdio>’, ‘var xld;’)。
1 | export function createSourceFile(fileName: string, sourceText: string, languageVersion: ScriptTarget, setParentNodes = false, scriptKind?: ScriptKind): SourceFile { |
入口函数内部除了某些性能测试代码,主要是调用 Parser.parseSourceFile 完成解析。
解析源文件对象
1 | export function parseSourceFile(fileName: string, sourceText: string, languageVersion: ScriptTarget, syntaxCursor: IncrementalParser.SyntaxCursor | undefined, setParentNodes = false, scriptKind?: ScriptKind): SourceFile { |
如果你仔细读了这段代码,你可能会有这些疑问:
1. NodeConstructor 等是什么
你可以直接将它看成 Node 类的构造函数,new NodeConstructor 和 new Node 是一回事。那为什么不直接用 new Node? 这是一种性能优化手段。TS 设计的目的是用于任何 JS 引擎,包括浏览器、Node.js、微软自己的 JS 引擎,而 Node 代表语法树节点,数目会非常多,TS 允许针对不同的环境使用不同的 Node 类型,以达到最节约内存的效果。
2. syntaxCursor 是什么
这是用于增量解析的对象,如果不执行增量解析,它是空的。增量解析是指如果之前已解析过一次源码,第二次解析时可以复用上次解析的结果,主要在编译器场景使用:编辑完源码后,源码要重新解析为语法树,如果通过增量解析,可以大幅减少解析次数。增量解析将在下一节中详细介绍。
3. identifiers 是什么
一般地,我们认为:源码中的单词都会用两次以上(变量名总会有定义和使用的时候,这里就有两次),如果将相同内容的字符串共用相同的引用,可以节约内存。identifiers 就保存了每个字符串内存的唯一引用。
4. parsingContext 是什么
用于指代当前解析所在的标记位,比如当前函数是否有 async,这样可以判断 await 是否合法。
5. parseErrorBeforeNextFinishedNode 是什么
每个语法树节点,都通过 createNode 创建,然后结束时会调用 finishNode,如果在解析一个语法树节点时出现错误(可能是词法扫描错误、也可能是语法错误),都会把 parseErrorBeforeNextFinishedNode 改成 true,在 finishNode 中会判断这个变量,然后标记这个语法树节点存在语法错误。TypeScript 比其它语法解析器强大的地方在于碰到语法错误后并不会终止解析,而是尝试修复源码。(因为在编辑器环境,不可能因为存在错误就停止自动补全)。这里标记节点语法错误,是为了下次增量解析时禁止重用此节点。
解析过程
虽然这篇文章叫 TypeScript 源码解读,但其实主要是介绍编译器的实现原理,知道了这些原理,无论什么语言的编译器你都能弄明白,反过来如果你之前没有什么基础想要自己读懂 TypeScript,那是很难的。源码就像水果,你需要自己剥;这篇文章就像果汁,营养吸收地更快。插图是展示原理的最好方式,因此文中会包含大量的插图,如果你现在读的这个网页是纯文字,一张插图都没有,那么这个网站就是盗版侵权的,请重新百度。原版都是有插图的,插图可以让你快速理解原理!这类文章目前不止中文版的稀缺,英文版的同样稀缺,毕竟了解编译原理、且真正能开发出语言的人是非常少的。有兴趣读这些文章的也绝不是只知道搬砖赚钱的菜鸟,请支持原版!
解析器每次读取一个标记,并根据这个标记判断接下来是什么语法,比如碰到 if 就知道是 if 语句,碰到 var 知道是变量声明。
当发现 if 之后,根据 if 语句的定义,接下来会强制读取一个 “(” 标记,如果读不到就报错:语法错误,缺少“(”。读完 “(” 后解析一个表达式,然后再解析一个“)”,然后再解析一个语句,如果这时接下来发现一个 else,就继续读一个语句,否则直接终止,然后重新判断下一个标记的语法。

if 语句的语法定义是这样的:
1 | IfStatement: |
这个定义的意思是:if 语句(IfStatement)有两种语法,当然无论哪种,开头都是 if ( Expression ) Statement
为什么是这样定义的呢,这是因为JS是遵守ECMA-262规范的,而ECMA-262规范就像一种协议,规定了 if 语句要怎么定义。
ECMA-262 规范也有很多版本,熟悉的ES3,ES5,ES6 这些其实就是这个规范的版本。ES10的版本可以在这里查看:http://www.ecma-international.org/ecma-262/10.0/index.html#sec-grammar-summary
代码实现
源文件由语句组成,首先读取下一个标记(nextToken);然后解析语句列表(parseList, parseStatement)
1 | function parseSourceFileWorker(fileName: string, languageVersion: ScriptTarget, setParentNodes: boolean, scriptKind: ScriptKind): SourceFile { |
解析一个语句:
1 | function parseStatement(): Statement { |
规则很简单:
先看现在标记是什么,比如是 var,说明是一个 var 语句,那就继续解析 var 语句:
1 | function parseVariableStatement(node: VariableStatement): VariableStatement { |
var 语句的解析过程为先解析一个声明列表,然后解析分号(parseSemicolon)
再看一个 while 语句的解析:
1 | function parseWhileStatement(): WhileStatement { |
所谓语法解析,就是把每个不同的语法都这样解析一次,然后得到语法树。
其中,最复杂的应该是解析列表(parseList):
1 | // Parses a list of elements |
parseList 的核心就是一个循环,只要列表没有结束,就一直解析同一种语法。
比如解析参数列表,碰到“)”表示列表结束,否则一直解析“参数”;比如解析数组表达式,碰到“]”结束。
如果理论接下来应该解析参数时,但下一个标记又不是参数,则会出现语法错误,但接下来应该解析解析参数,还是不再继续参数列表,这时候用 abortParsingListOrMoveToNextToken 判断。
其中,kind: ParsingContext 用于区分不同的列表(是参数,还是数组?或者别的?)
列表结束
1 | // True if positioned at a list terminator |
总结:对于有括号的标记,只有碰到右半括号,才能停止解析,其它的比如继承列表(extends A, B, C) 碰到 “{” 就结束。
解析元素
1 | function parseListElement<T extends Node>(parsingContext: ParsingContext, parseElement: () => T): T { |
这里本质是使用了 parseElement,其它代码是为了增量解析(后面详解)
继续列表
1 | function abortParsingListOrMoveToNextToken(kind: ParsingContext) { |
总结:如果接下来的标记是合法的元素,就继续解析,此时解析器认为用户只是忘打逗号之类的分隔符。如果不是说明这个列表根本就是有问题的,不再继续犯错。
上面重点介绍了 if 的语法,其它都大同小异,就不再介绍。
现在你应该知道语法树产生的大致过程了,如果仍不懂的,可在此处停顿往回复习,并对照源码,加以理解。
语法上下文
有些语法的使用是有要求的,比如 await 只在 async 函数内部才作关键字。
源码中用闭包内全局的变量存储这些信息。思路是:先设置允许 await 标记位,然后解析表达式(这时标记位已设置成允许 await),解析完成则清除标记位。
1 | function doInAwaitContext<T>(func: () => T): T { |
这也是为什么规范中每个语法名称后面都带了一个小括号的原因:表示此处的表达式是否包括 await 这样的意义。
1 | IfStatement[Yield, Await, Return]: |
其中,+In 表示允许 in 标记,?yield 表示 yield 标记保持不变,- in 表示禁止 in 标记。
通过上下文语法,下面这样的代码是不允许的:
1 | for(var x = key in item; x; ) { |
(虽然 in 是本身也是可以直接使用的运算符,但不能用于 for 的初始值,否则按 for..in 解析。)
后瞻(lookahead)
上面举的例子,都是可以通过第一个标记就可以确定后面的语法(比如碰到 if 就按 if 语句处理)。那有没可能只看第一个标记无法确定之后的语法呢?
早期的 JS 版本是没有的(毕竟这样编译器做起来简单),但随着 JS 功能不断增加,就出现了这样的情况。
比如直接 x 是变量,如果后面有箭头, x =>,就成了参数。
这时需要用到语法后瞻,所谓的后瞻就是提前看一下后面的标记,然后决定。
1 | /** Invokes the provided callback then unconditionally restores the parser to the state it |
说的比较简单,具体实现稍微麻烦:如果预览的时候发现标记错误咋办?所以需要先记住当前的错误信息,然后使用扫描器的预览功能读取之后的标记,之后完全恢复到之前的状态。
TypeScript 中有哪些语法要后瞻呢?
- <T> 可能是类型转换(<any>x)、箭头函数( <T> x => {})或 JSX (<T>X</T>)
- public 可能是修饰符(public class A {}),或变量(public++)
- type 在后面跟标识符时才是别名类型,否则作变量
- let 只有在后面跟标识符时才是变量声明,否则是变量,但 let let = 1 是不对的。
可以看到语法后瞻增加了编译器的复杂度,也浪费了一些性能。
虽然语法设计者尽量避免出现这样的后瞻,但还是有一些地方,因为兼容问题不得不采用这个方案。
语法歧义
/ 的歧义
之前提到的 / 可能是除号或正则表达式,在词法阶段还无法分析,但在语法解析阶段,因为已知道现在需要什么语法,可以正确地处理这个符号。
比如需要表达式的时候,碰到 /,因为 / 不能是表达式的开头,只能把 / 重新按正则表达式标记解析。如果在表达式后面碰到 /,那就作除号。
但也有些歧义是语法解析阶段都很难处理的。
< 的歧义
比如 call<number, any>(x),你可能觉得是调用 call 泛型函数(参数 x),但它也可以理解成: (call < number) , (any > (x))
所有支持泛型的C风格语言都有类似的问题,多数编译器的做法是:和你想的一样,按泛型看,毕竟一般人很少在 > 后面写括号。
在 TS 设计之初,<T>x 是表示类型转换的,这个设计源于 C。但后来为了支持 JSX,这个语法就和 JSX 彻底冲突了。
因此 TS 选择的方案是:引入 as 语法,<T>x 和 x as T 完全相同。同时引入 tsx 扩展名,在 tsx 中,<T> 当 JSX,在普通 ts,<T> 依然是类型转换(为兼容)。
插入分号
JS 一向允许省略分号,在需要解析分号的地方判断后面的标记是否是“}”,或包含空行。
1 | function canParseSemicolon() { |
JSDoc
TS 为了尽可能兼容 JS,允许用户直接使用 JS + JSDoc 的方式备注类型,所以 JS 里的 JSDoc 注释也按源码的一部分解析。
1 | /** @type {string} */ |
1 | export function parseIsolatedJSDocComment(content: string, start: number | undefined, length: number | undefined): { jsDoc: JSDoc, diagnostics: Diagnostic[] } | undefined { |
小结
本节介绍了语法解析,并提到了 TS 如何在碰到错误后继续解析。
6.绑定-符号
在上一节主要介绍了语法树的解析生成。就好比电脑已经听到了“你真聪明”这句话,现在要让电脑开始思考这句话的含义——是真聪明还是假聪明。
这是一个非常的复杂的过程,接下来将有连续几节内容介绍实现原理,本节则主要提前介绍一些相关的概念。
符号
在代码里面,可以定义一个变量、一个函数、或者一个类,这些定义都有一个名字,然后在其它地方可以通过名字引用这个定义。
这些定义统称为符号(Symbol)(注意和 ES6 里的 Symbol 不相干)。
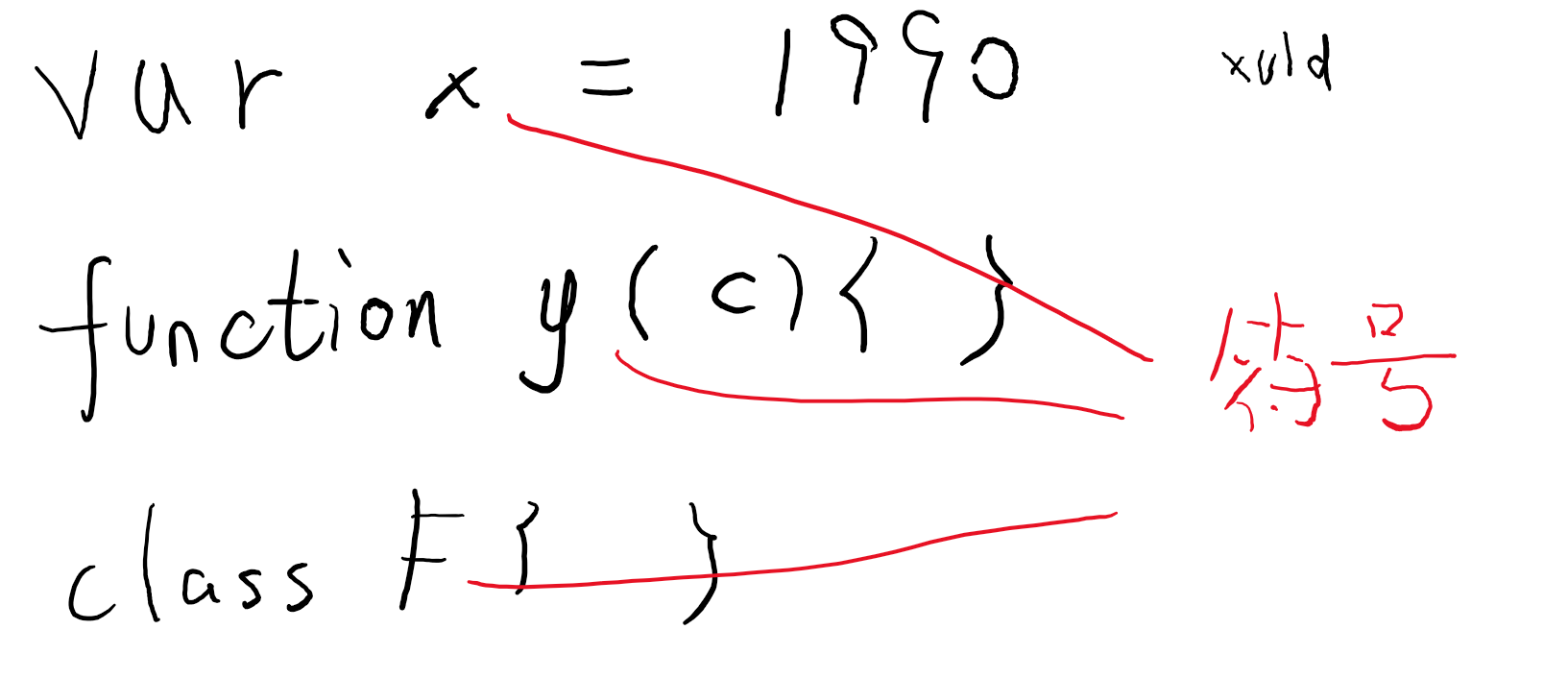
当在代码里写了一个标识符名称(变量名),这个名称一定可以解析为某个符号(可能是变量、参数、函数或其它的,可能是用户自己写的,也可能系统自带),如果无法解析,那一定是一个错误。
一个符号一般和一个声明节点对应,比如一个变量符号就对应一个 var 声明节点或 let/const 声明节点。
可能存在一个符号对应多个声明节点的情况,比如:
1 | class A{} |
同名的类和接口只产生一个符号 A,但这个符号拥有两个声明。
可能存在一个符号没有源声明节点的情况,比如:
1 | type T = {[key: string]: any} |
T 有无限个成员,每个成员都是没有源声明节点的。
TS 中符号的定义:
1 | export interface Symbol { |
其中,declarations 表示关联的源节点。valueDeclaration 则表示第一个具有值的源节点。
注意两者都可能为 undefined,源码中之所以没将它们标上 ?,主要是因为作者懒(不然代码需要经常判断空)。
其中,escapedName 表示符号的名称,名称本质是字符串,TS 在源码中有一些内部的特殊符号名称,这些名称都以“__”前缀,如果用户本身就定义了名字带__的,会被转义成其它名字,所以 TS 内部将转义后的名字标记成 __String 类型,运行期间它本质还是字符串,所以不影响性能。
作用域
允许定义符号的节点叫作用域(Scope),比如全局范围(源文件),函数,大括号。
在同一个作用域中,不能定义同名的符号。
作用域是一个树结构,查找变量时,先在就近的作用域查找,找不到就向外层查找。
如图共四个作用域:
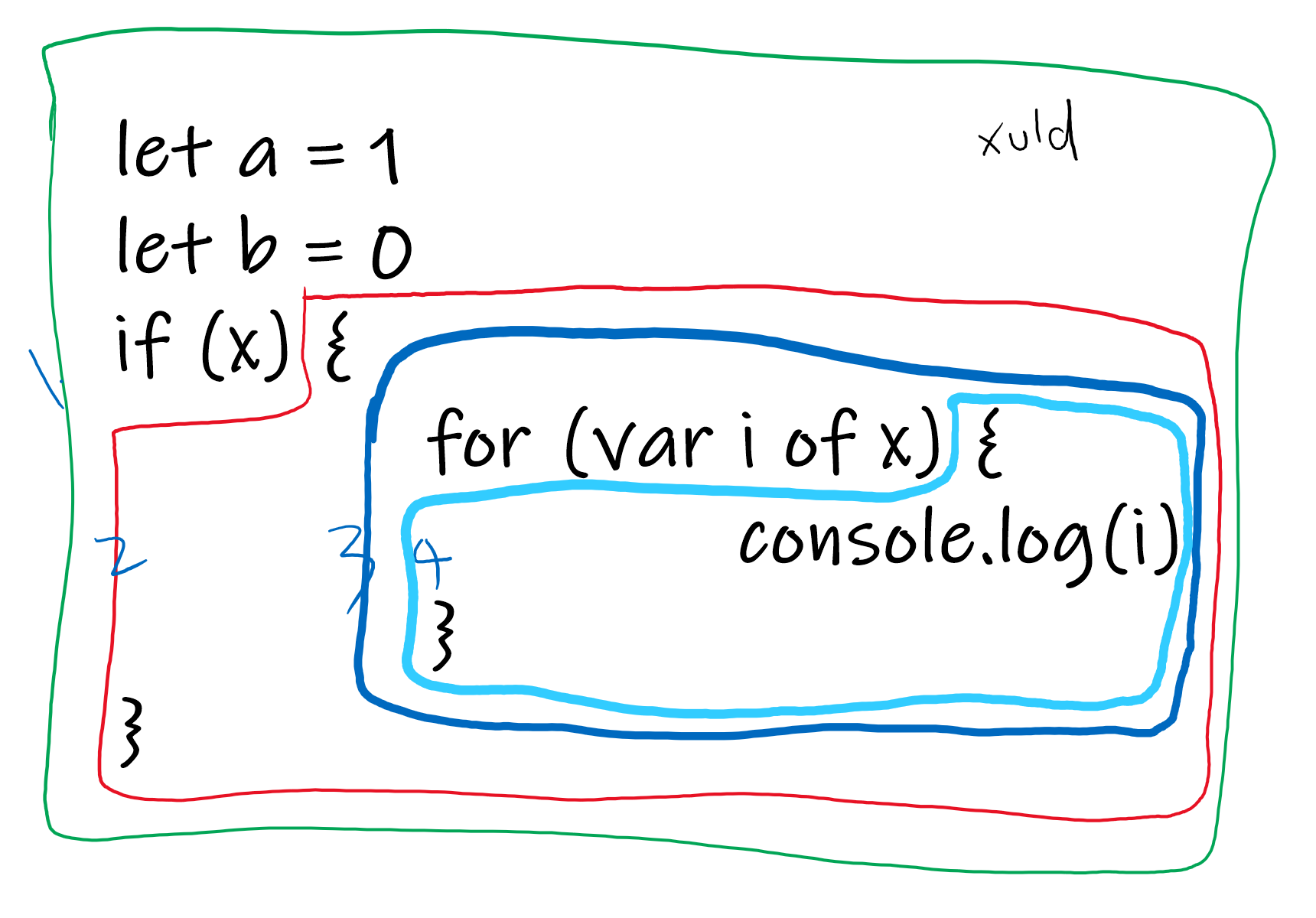
仔细观察会发现,if 语句不是一个作用域,但 for 语句却是。
语言本身就是这么设计的,因为在 for 里面可以声明变量。
流程节点
流程节点是执行流程图的组成部分。
比如 a = b > c && d == 3 ? e : f 的执行顺序:

由于 JS 是动态语言,变量的类型可能随执行的流程发生变化,因此在分析时需要知道整个代码的执行顺序。
流程节点就是拥有记录这个顺序的对象。
开始流程
开始流程是整个流程图的根节点。
1 | // FlowStart represents the start of a control flow. For a function expression or arrow |
代码总是从一个函数开始执行的,所以开始流程也会记录关联的函数声明。
标签流程
如果执行的时候出现判断,则可能从一个流程进入两个子流程,即流程跳转,跳转的目标叫标签流程:
1 | // FlowLabel represents a junction with multiple possible preceding control flows. |
antecedents 中文意思是祖先,其实是代表执行这个流程节点的上一个父流程节点。
比如上图例子中,编号 5 就是一个标签流程,其父流程分别是 e 和 f 所属流程。
代码中的循环也是以标签流程的方式出现的。
缩小类型范围的流程
理论上,每行节点都可能对变量的类型有影响,比如上图例子中,e 所在的位置在流程上可以确认 d == 3。
那么 d == 3 就是一种缩小类型范围的流程,在这个流程节点后面,统一认为 d 就是 3。
TS 目前并不支持将所有的表达式都按缩小类型范围的流程处理,只支持特定的几种表达式,甚至有些表达式如果加了括号就不认识。
这主要是基于性能考虑,这样可以更少创建流程节点。
TS 目前支持的流程有:
1 | // FlowAssignment represents a node that assigns a value to a narrowable reference, |
finally 流程
try finally 流程稍微有些麻烦。
1 | try { |
对于位置 5,其父流程是 1/2/3/4 (假设 try 中任何一行代码都可能报错)
对于位置 6,其父流程只能是 5,且此时的 5 的父流程只能是 2/4,
所以位置 6 的父流程节点是 finally 结束位置的节点 5,而节点 5 的父流程有两种可能:1/2/3/4 或只有 2/4
所以 TS 在 5 的前后插入了两个特殊的流程节点:StartFinally 和 EndFinally,
当遍历到 EndFinally 时,则给 StartFinally 加锁,说明此时需要的是 finally 之后的流程节点,否则说明需要的是 finally 本身的父节点
1 | export interface AfterFinallyFlow extends FlowNodeBase, FlowLock { |
综合
以上所有类型的流程节点,通过父节点的方式组成一个图
1 | export type FlowNode = |
如果将流程节点可视化,将类似地铁图,每个节点就是一个站点,站点之间的线路存在分叉,也存在合并,也存在循环。
自测题
为了帮助验证到此为止的知识点是否都已掌握,这里准备了一些题目:
- 解释以下术语:
- Token
- Node
- SyntaxKind
- Symbol
- Declaration
- TypeNode
- FlowNode
- Increamentable
- fullStart
- Trivial
阐述编译器从源文件到符号的流程步骤
猜测编译器在生成符号后的操作内容