这个部分用来介绍Node相关知识,很遗憾没有做过一个完整的Node项目,掌握度不足,但Vue实战中的打包过程用了很多相关知识,赶紧补起来,这一块实战中由于脚手架的出现,已经相对遗忘了,要自己写一个配置,就需要好好掌握了
1. 浏览器与Node的事件循环(Event Loop)有何区别?
1.1 线程与进程
1.概念
我们经常说JS 是单线程执行的,指的是一个进程里只有一个主线程,那到底什么是线程?什么是进程?
官方的说法是:进程是 CPU资源分配的最小单位;线程是 CPU调度的最小单位。这两句话并不好理解,我们先来看张图:
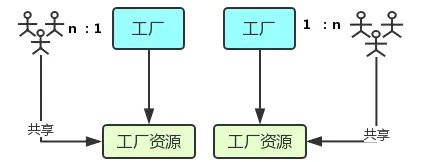
- 进程好比图中的工厂,有单独的专属自己的工厂资源。
- 线程好比图中的工人,多个工人在一个工厂中协作工作,工厂与工人是 1:n的关系。也就是说一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
- 工厂的空间是工人们共享的,这象征一个进程的内存空间是共享的,每个线程都可用这些共享内存。
- 多个工厂之间独立存在。
2.多进程与多线程
- 多进程:在同一个时间里,同一个计算机系统中如果允许两个或两个以上的进程处于运行状态。多进程带来的好处是明显的,比如你可以听歌的同时,打开编辑器敲代码,编辑器和听歌软件的进程之间丝毫不会相互干扰。
- 多线程:程序中包含多个执行流,即在一个程序中可以同时运行多个不同的线程来执行不同的任务,也就是说允许单个程序创建多个并行执行的线程来完成各自的任务。
以Chrome浏览器中为例,当你打开一个 Tab 页时,其实就是创建了一个进程,一个进程中可以有多个线程(下文会详细介绍),比如渲染线程、JS 引擎线程、HTTP 请求线程等等。当你发起一个请求时,其实就是创建了一个线程,当请求结束后,该线程可能就会被销毁。
1.2 浏览器内核
简单来说浏览器内核是通过取得页面内容、整理信息(应用CSS)、计算和组合最终输出可视化的图像结果,通常也被称为渲染引擎。
浏览器内核是多线程,在内核控制下各线程相互配合以保持同步,一个浏览器通常由以下常驻线程组成:
- GUI 渲染线程
- JavaScript引擎线程
- 定时触发器线程
- 事件触发线程
- 异步http请求线程
1.2.1 GUI渲染线程
- 主要负责页面的渲染,解析HTML、CSS,构建DOM树,布局和绘制等。
- 当界面需要重绘或者由于某种操作引发回流时,将执行该线程。
- 该线程与JS引擎线程互斥,当执行JS引擎线程时,GUI渲染会被挂起,当任务队列空闲时,主线程才会去执行GUI渲染。
1.2.2 JS引擎线程
- 该线程当然是主要负责处理 JavaScript脚本,执行代码。
- 也是主要负责执行准备好待执行的事件,即定时器计数结束,或者异步请求成功并正确返回时,将依次进入任务队列,等待 JS引擎线程的执行。
- 当然,该线程与 GUI渲染线程互斥,当 JS引擎线程执行 JavaScript脚本时间过长,将导致页面渲染的阻塞。
1.2.3 定时器触发线程
- 负责执行异步定时器一类的函数的线程,如: setTimeout,setInterval。
- 主线程依次执行代码时,遇到定时器,会将定时器交给该线程处理,当计数完毕后,事件触发线程会将计数完毕后的事件加入到任务队列的尾部,等待JS引擎线程执行。
1.2.4事件触发线程
- 主要负责将准备好的事件交给 JS引擎线程执行。
比如 setTimeout定时器计数结束, ajax等异步请求成功并触发回调函数,或者用户触发点击事件时,该线程会将整装待发的事件依次加入到任务队列的队尾,等待 JS引擎线程的执行。
1.2.5 异步http请求线程
- 负责执行异步请求一类的函数的线程,如: Promise,axios,ajax等。
- 主线程依次执行代码时,遇到异步请求,会将函数交给该线程处理,当监听到状态码变更,如果有回调函数,事件触发线程会将回调函数加入到任务队列的尾部,等待JS引擎线程执行。
1.3 浏览器中的 Event Loop
1.3.1 Micro-Task 与 Macro-Task
浏览器端事件循环中的异步队列有两种:macro(宏任务)队列和 micro(微任务)队列。宏任务队列可以有多个,微任务队列只有一个。
- 常见的 macro-task 比如:setTimeout、setInterval、script(整体代码)、 I/O 操作、UI 渲染等。
- 常见的 micro-task 比如: new Promise().then(回调)、MutationObserver(html5新特性) 等。
1.3.2 Event Loop 过程解析
一个完整的 Event Loop 过程,可以概括为以下阶段:
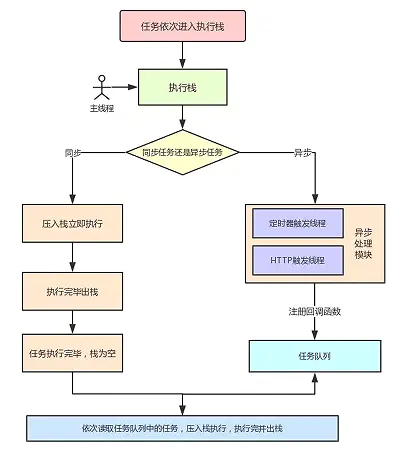
- 一开始执行栈空,我们可以把执行栈认为是一个存储函数调用的栈结构,遵循先进后出的原则。micro 队列空,macro 队列里有且只有一个 script 脚本(整体代码)。
- 全局上下文(script 标签)被推入执行栈,同步代码执行。在执行的过程中,会判断是同步任务还是异步任务,通过对一些接口的调用,可以产生新的 macro-task 与 micro-task,它们会分别被推入各自的任务队列里。同步代码执行完了,script 脚本会被移出 macro 队列,这个过程本质上是队列的 macro-task 的执行和出队的过程。
- 上一步我们出队的是一个 macro-task,这一步我们处理的是 micro-task。但需要注意的是:当 macro-task 出队时,任务是一个一个执行的;而 micro-task 出队时,任务是一队一队执行的。因此,我们处理 micro 队列这一步,会逐个执行队列中的任务并把它出队,直到队列被清空。
- 执行渲染操作,更新界面
- 检查是否存在 Web worker 任务,如果有,则对其进行处理
- 上述过程循环往复,直到两个队列都清空
我们总结一下,每一次循环都是一个这样的过程:
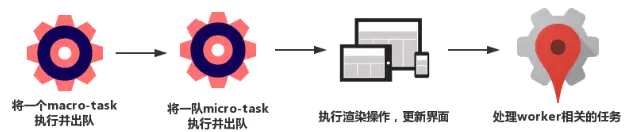
当某个宏任务执行完后,会查看是否有微任务队列。如果有,先执行微任务队列中的所有任务,如果没有,会读取宏任务队列中排在最前的任务,执行宏任务的过程中,遇到微任务,依次加入微任务队列。栈空后,再次读取微任务队列里的任务,依次类推。
接下来我们看道例子来介绍上面流程:
1 | Promise.resolve().then(()=>{ |
最后输出结果是Promise1,setTimeout1,Promise2,setTimeout2
- 一开始执行栈的同步任务(这属于宏任务)执行完毕,会去查看是否有微任务队列,上题中存在(有且只有一个),然后执行微任务队列中的所有任务输出Promise1,同时会生成一个宏任务 setTimeout2
- 然后去查看宏任务队列,宏任务 setTimeout1 在 setTimeout2 之前,先执行宏任务 setTimeout1,输出 setTimeout1
- 在执行宏任务setTimeout1时会生成微任务Promise2 ,放入微任务队列中,接着先去清空微任务队列中的所有任务,输出 Promise2
- 清空完微任务队列中的所有任务后,就又会去宏任务队列取一个,这回执行的是 setTimeout2
1.4 Node 中的 Event Loop
1.4.1 Node简介
Node 中的 Event Loop 和浏览器中的是完全不相同的东西。Node.js采用V8作为js的解析引擎,而I/O处理方面使用了自己设计的libuv,libuv是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的API,事件循环机制也是它里面的实现(下文会详细介绍)。
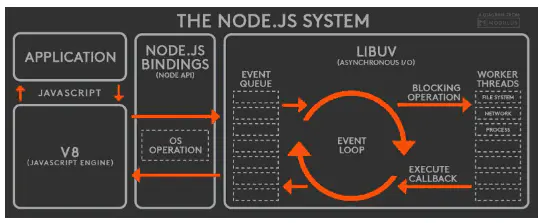
Node.js的运行机制如下:
- V8引擎解析JavaScript脚本。
- 解析后的代码,调用Node API。
- libuv库负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
- V8引擎再将结果返回给用户。
1.4.2 六个阶段
其中libuv引擎中的事件循环分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段。
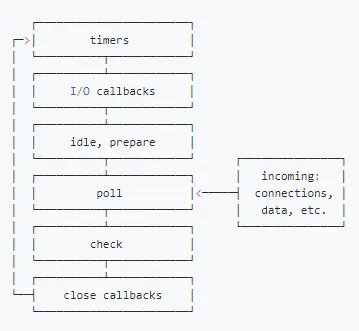
从上图中,大致看出node中的事件循环的顺序:
外部输入数据–>轮询阶段(poll)–>检查阶段(check)–>关闭事件回调阶段(close callback)–>定时器检测阶段(timer)–>I/O事件回调阶段(I/O callbacks)–>闲置阶段(idle, prepare)–>轮询阶段(按照该顺序反复运行)…
- timers 阶段:这个阶段执行timer(setTimeout、setInterval)的回调
- I/O callbacks 阶段:处理一些上一轮循环中的少数未执行的 I/O 回调
- idle, prepare 阶段:仅node内部使用
- poll 阶段:获取新的I/O事件, 适当的条件下node将阻塞在这里
- check 阶段:执行 setImmediate() 的回调
- close callbacks 阶段:执行 socket 的 close 事件回调
注意:上面六个阶段都不包括 process.nextTick()(下文会介绍)
接下去我们详细介绍timers、poll、check这3个阶段,因为日常开发中的绝大部分异步任务都是在这3个阶段处理的。
(1) timer
timers 阶段会执行 setTimeout 和 setInterval 回调,并且是由 poll 阶段控制的。 同样,在 Node 中定时器指定的时间也不是准确时间,只能是尽快执行。
(2) poll
poll 是一个至关重要的阶段,这一阶段中,系统会做两件事情
1.回到 timer 阶段执行回调
2.执行 I/O 回调
并且在进入该阶段时如果没有设定了 timer 的话,会发生以下两件事情
- 如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者达到系统限制
- 如果 poll 队列为空时,会有两件事发生
- 如果有 setImmediate 回调需要执行,poll 阶段会停止并且进入到 check 阶段执行回调
- 如果没有 setImmediate 回调需要执行,会等待回调被加入到队列中并立即执行回调,这里同样会有个超时时间设置防止一直等待下去
当然设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调。
(3) check阶段
setImmediate()的回调会被加入check队列中,从event loop的阶段图可以知道,check阶段的执行顺序在poll阶段之后。 我们先来看个例子:
1 | console.log('start') |
- 一开始执行栈的同步任务(这属于宏任务)执行完毕后(依次打印出start end,并将2个timer依次放入timer队列),会先去执行微任务(这点跟浏览器端的一样),所以打印出promise3
- 然后进入timers阶段,执行timer1的回调函数,打印timer1,并将promise.then回调放入microtask队列,同样的步骤执行timer2,打印timer2;这点跟浏览器端相差比较大,timers阶段有几个setTimeout/setInterval都会依次执行,并不像浏览器端,每执行一个宏任务后就去执行一个微任务(关于Node与浏览器的 Event Loop 差异,下文还会详细介绍)。
1.4.3 Micro-Task 与 Macro-Task
Node端事件循环中的异步队列也是这两种:macro(宏任务)队列和 micro(微任务)队列。
- 常见的 macro-task 比如:setTimeout、setInterval、 setImmediate、script(整体代码)、 I/O 操作等。
- 常见的 micro-task 比如: process.nextTick、new Promise().then(回调)等。
1.4.4 注意点
(1) setTimeout 和 setImmediate
二者非常相似,区别主要在于调用时机不同。
- setImmediate 设计在poll阶段完成时执行,即check阶段;
- setTimeout 设计在poll阶段为空闲时,且设定时间到达后执行,但它在timer阶段执行
1 | setTimeout(function timeout () { |
- 对于以上代码来说,setTimeout 可能执行在前,也可能执行在后。
- 首先 setTimeout(fn, 0) === setTimeout(fn, 1),这是由源码决定的 进入事件循环也是需要成本的,如果在准备时候花费了大于 1ms 的时间,那么在 timer 阶段就会直接执行 setTimeout 回调
- 如果准备时间花费小于 1ms,那么就是 setImmediate 回调先执行了
但当二者在异步i/o callback内部调用时,总是先执行setImmediate,再执行setTimeout
1 | const fs = require('fs') |
在上述代码中,setImmediate 永远先执行。因为两个代码写在 IO 回调中,IO 回调是在 poll 阶段执行,当回调执行完毕后队列为空,发现存在 setImmediate 回调,所以就直接跳转到 check 阶段去执行回调了。
(2) process.nextTick
这个函数其实是独立于 Event Loop 之外的,它有一个自己的队列,当每个阶段完成后,如果存在 nextTick 队列,就会清空队列中的所有回调函数,并且优先于其他 microtask 执行。
1 | setTimeout(() => { |
1.5 Node与浏览器的 Event Loop 差异
浏览器环境下,microtask的任务队列是每个macrotask执行完之后执行。而在Node.js中,microtask会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行microtask队列的任务。
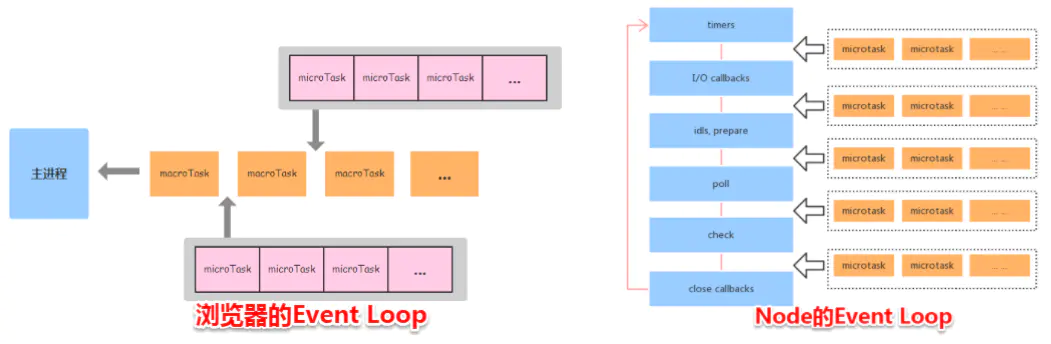
接下我们通过一个例子来说明两者区别:
1 | setTimeout(()=>{ |
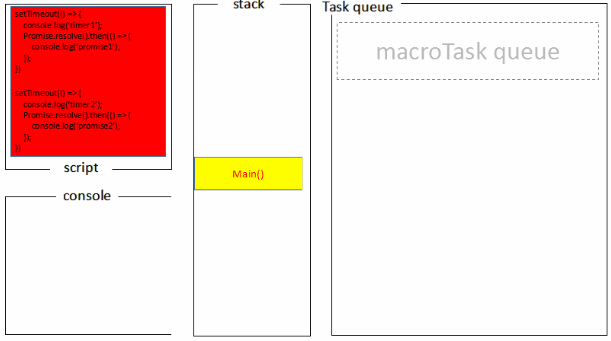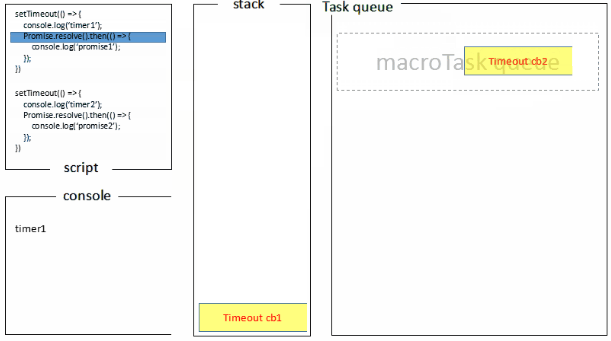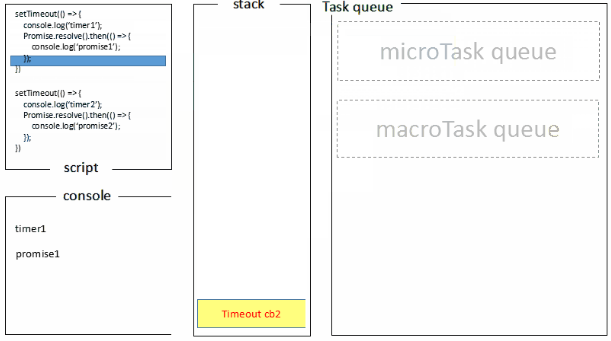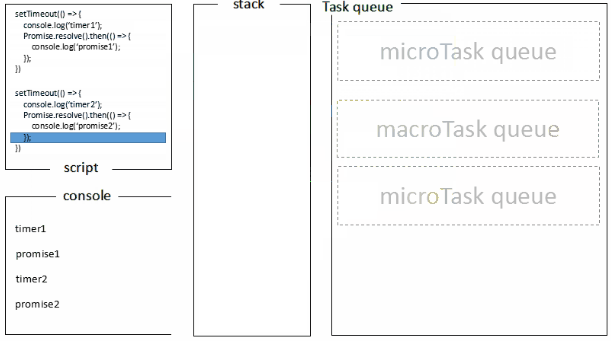
浏览器端运行结果:timer1=>promise1=>timer2=>promise2
浏览器端的处理过程如下:
Node端运行结果分两种情况:
- 如果是node11版本一旦执行一个阶段里的一个宏任务(setTimeout,setInterval和setImmediate)就立刻执行微任务队列,这就跟浏览器端运行一致,最后的结果为
timer1=>promise1=>timer2=>promise2 - 如果是node10及其之前版本:要看第一个定时器执行完,第二个定时器是否在完成队列中。
- 如果是第二个定时器还未在完成队列中,最后的结果为
timer1=>promise1=>timer2=>promise2 - 如果是第二个定时器已经在完成队列中,则最后的结果为
timer1=>timer2=>promise1=>promise2(下文过程解释基于这种情况下)
- 如果是第二个定时器还未在完成队列中,最后的结果为
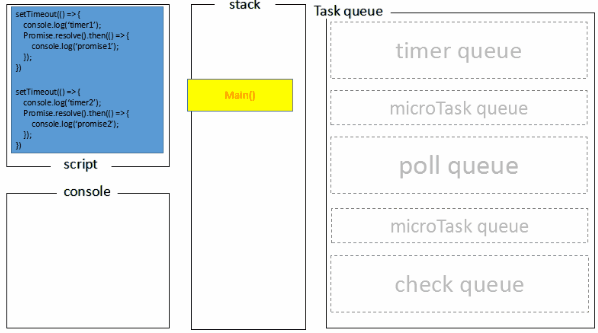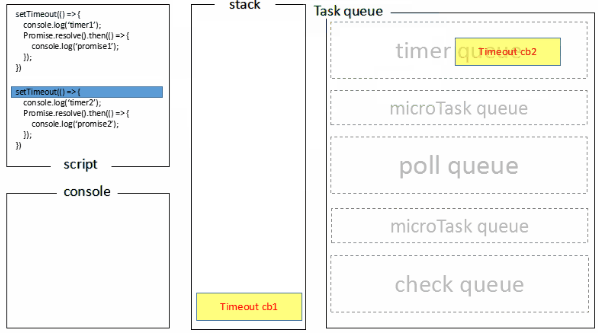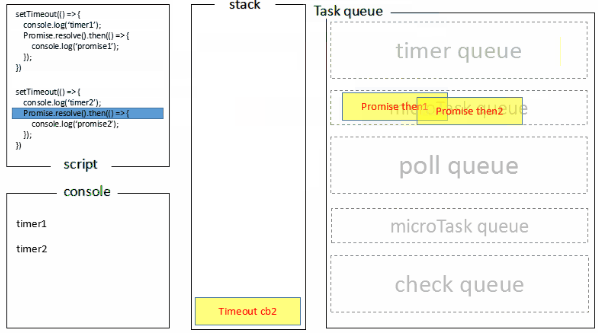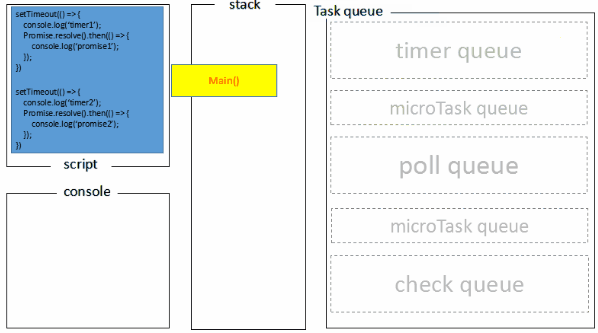
1.全局脚本(main())执行,将2个timer依次放入timer队列,main()执行完毕,调用栈空闲,任务队列开始执行;
2.首先进入timers阶段,执行timer1的回调函数,打印timer1,并将promise1.then回调放入microtask队列,同样的步骤执行timer2,打印timer2;
3.至此,timer阶段执行结束,event loop进入下一个阶段之前,执行microtask队列的所有任务,依次打印promise1、promise2
Node端的处理过程如下:
1.6 总结
浏览器和Node 环境下,microtask 任务队列的执行时机不同
- Node端,microtask 在事件循环的各个阶段之间执行
- 浏览器端,microtask 在事件循环的 macrotask 执行完之后执行
后记
文章于2019.1.16晚,对最后一个例子在node运行结果,重新修改!再次特别感谢zy445566的精彩点评,由于node版本更新到11,Event Loop运行原理发生了变化,一旦执行一个阶段里的一个宏任务(setTimeout,setInterval和setImmediate)就立刻执行微任务队列,这点就跟浏览器端一致。
参考文章
- 浏览器进程?线程?傻傻分不清楚!
- 事件循环机制的那些事
- 前端性能优化原理与实践
- 前端面试之道
- 深入理解js事件循环机制(Node.js篇)
- 详解JavaScript中的Event Loop(事件循环)机制
- event-loop-timers-and-nexttick
- timers: run nextTicks after each immediate and timer
2.前端模块化
前言
在JavaScript发展初期就是为了实现简单的页面交互逻辑,寥寥数语即可;如今CPU、浏览器性能得到了极大的提升,很多页面逻辑迁移到了客户端(表单验证等),随着web2.0时代的到来,Ajax技术得到广泛应用,jQuery等前端库层出不穷,前端代码日益膨胀,此时在JS方面就会考虑使用模块化规范去管理。
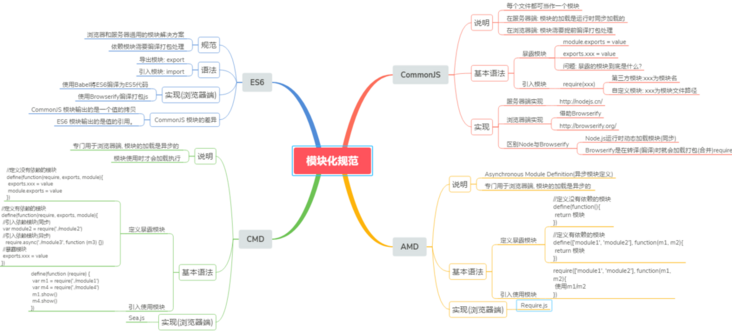
本文内容主要有理解模块化,为什么要模块化,模块化的优缺点以及模块化规范,并且介绍下开发中最流行的CommonJS, AMD, ES6、CMD规范。本文试图站在小白的角度,用通俗易懂的笔调介绍这些枯燥无味的概念,希望诸君阅读后,对模块化编程有个全新的认识和理解!
建议下载本文源代码,自己动手敲一遍,请猛戳GitHub个人博客
2.1 模块化的理解
2.1.1 什么是模块?
- 将一个复杂的程序依据一定的规则(规范)封装成几个块(文件), 并进行组合在一起
- 块的内部数据与实现是私有的, 只是向外部暴露一些接口(方法)与外部其它模块通信
2.2.2 模块化的进化过程
- 全局function模式 : 将不同的功能封装成不同的全局函数
- 编码: 将不同的功能封装成不同的全局函数
- 问题: 污染全局命名空间, 容易引起命名冲突或数据不安全,而且模块成员之间看不出直接关系
1 | function m1(){ |
- namespace模式 : 简单对象封装
- 作用: 减少了全局变量,解决命名冲突
- 问题: 数据不安全(外部可以直接修改模块内部的数据)
1 | let myModule = { |
这样的写法会暴露所有模块成员,内部状态可以被外部改写。
- IIFE模式:匿名函数自调用(闭包)
- 作用: 数据是私有的, 外部只能通过暴露的方法操作
- 编码: 将数据和行为封装到一个函数内部, 通过给window添加属性来向外暴露接口
- 问题: 如果当前这个模块依赖另一个模块怎么办?
1 | // index.html文件 |
最后得到的结果:

- IIFE模式增强 : 引入依赖
这就是现代模块实现的基石
1 | // module.js文件 |
上例子通过jquery方法将页面的背景颜色改成红色,所以必须先引入jQuery库,就把这个库当作参数传入。这样做除了保证模块的独立性,还使得模块之间的依赖关系变得明显。
2.2.3 模块化的好处
- 避免命名冲突(减少命名空间污染)
- 更好的分离, 按需加载
- 更高复用性
- 高可维护性
2.2.4 引入多个<script>后出现出现问题
- 请求过多
首先我们要依赖多个模块,那样就会发送多个请求,导致请求过多
- 依赖模糊
我们不知道他们的具体依赖关系是什么,也就是说很容易因为不了解他们之间的依赖关系导致加载先后顺序出错。
- 难以维护
以上两种原因就导致了很难维护,很可能出现牵一发而动全身的情况导致项目出现严重的问题。
模块化固然有多个好处,然而一个页面需要引入多个js文件,就会出现以上这些问题。而这些问题可以通过模块化规范来解决,下面介绍开发中最流行的commonjs, AMD, ES6, CMD规范。
2.2 模块化规范
2.2.1 CommonJS
(1)概述
Node 应用由模块组成,采用 CommonJS 模块规范。每个文件就是一个模块,有自己的作用域。在一个文件里面定义的变量、函数、类,都是私有的,对其他文件不可见。在服务器端,模块的加载是运行时同步加载的;在浏览器端,模块需要提前编译打包处理。
(2)特点
- 所有代码都运行在模块作用域,不会污染全局作用域。
- 模块可以多次加载,但是只会在第一次加载时运行一次,然后运行结果就被缓存了,以后再加载,就直接读取缓存结果。要想让模块再次运行,必须清除缓存。
- 模块加载的顺序,按照其在代码中出现的顺序。
(3)基本语法
- 暴露模块:
module.exports = value或exports.xxx = value - 引入模块:
require(xxx),如果是第三方模块,xxx为模块名;如果是自定义模块,xxx为模块文件路径
此处我们有个疑问:CommonJS暴露的模块到底是什么? CommonJS规范规定,每个模块内部,module变量代表当前模块。这个变量是一个对象,它的exports属性(即module.exports)是对外的接口。加载某个模块,其实是加载该模块的module.exports属性。
1 | // example.js |
上面代码通过module.exports输出变量x和函数addX。
1 | var example = require('./example.js');//如果参数字符串以“./”开头,则表示加载的是一个位于相对路径 |
require命令用于加载模块文件。require命令的基本功能是,读入并执行一个JavaScript文件,然后返回该模块的exports对象。如果没有发现指定模块,会报错。
(4)模块的加载机制
CommonJS模块的加载机制是,输入的是被输出的值的拷贝。也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。这点与ES6模块化有重大差异(下文会介绍),请看下面这个例子:
1 | // lib.js |
上面代码输出内部变量counter和改写这个变量的内部方法incCounter。
1 | // main.js |
上面代码说明,counter输出以后,lib.js模块内部的变化就影响不到counter了。这是因为counter是一个原始类型的值,会被缓存。除非写成一个函数,才能得到内部变动后的值。
(5)服务器端实现
①下载安装node.js
②创建项目结构
注意:用npm init 自动生成package.json时,package name(包名)不能有中文和大写
1 | |-modules |
③下载第三方模块
1 | npm install uniq --save // 用于数组去重 |
④定义模块代码
1 | //module1.js |
⑤通过node运行app.js
命令行输入node app.js,运行JS文件
(6)浏览器端实现(借助Browserify)
①创建项目结构
1 | |-js |
②下载browserify
- 全局: npm install browserify -g
- 局部: npm install browserify –save-dev
③定义模块代码(同服务器端)
注意:index.html文件要运行在浏览器上,需要借助browserify将app.js文件打包编译,如果直接在index.html引入app.js就会报错!
④打包处理js
根目录下运行browserify js/src/app.js -o js/dist/bundle.js
⑤页面使用引入
在index.html文件中引入<script type="text/javascript" src="js/dist/bundle.js"></script>
2.2.2 AMD
CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。AMD规范则是非同步加载模块,允许指定回调函数。由于Node.js主要用于服务器编程,模块文件一般都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,所以CommonJS规范比较适用。但是,如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用AMD规范。此外AMD规范比CommonJS规范在浏览器端实现要来着早。
(1)AMD规范基本语法
定义暴露模块:
1 | //定义没有依赖的模块 |
引入使用模块:
1 | require(['module1', 'module2'], function(m1, m2){ |
(2)未使用AMD规范与使用require.js
通过比较两者的实现方法,来说明使用AMD规范的好处。
- 未使用AMD规范
1 | // dataService.js文件 |
最后得到如下结果: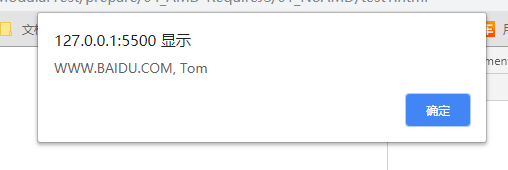
这种方式缺点很明显:首先会发送多个请求,其次引入的js文件顺序不能搞错,否则会报错!
- 使用require.js
RequireJS是一个工具库,主要用于客户端的模块管理。它的模块管理遵守AMD规范,RequireJS的基本思想是,通过define方法,将代码定义为模块;通过require方法,实现代码的模块加载。
接下来介绍AMD规范在浏览器实现的步骤:
①下载require.js, 并引入
- 官网:
http://www.requirejs.cn/ - github :
https://github.com/requirejs/requirejs
然后将require.js导入项目: js/libs/require.js
②创建项目结构
1 | |-js |
③定义require.js的模块代码
1 | // dataService.js文件 |
④页面引入require.js模块:
在index.html引入 <script data-main="js/main" src="js/libs/require.js"></script>
此外在项目中如何引入第三方库?只需在上面代码的基础稍作修改:
1 | // alerter.js文件 |
上例是在alerter.js文件中引入jQuery第三方库,main.js文件也要有相应的路径配置。
小结:通过两者的比较,可以得出AMD模块定义的方法非常清晰,不会污染全局环境,能够清楚地显示依赖关系。AMD模式可以用于浏览器环境,并且允许非同步加载模块,也可以根据需要动态加载模块。
2.2.3 CMD
CMD规范专门用于浏览器端,模块的加载是异步的,模块使用时才会加载执行。CMD规范整合了CommonJS和AMD规范的特点。在 Sea.js 中,所有 JavaScript 模块都遵循 CMD模块定义规范。
(1)CMD规范基本语法
定义暴露模块:
1 | //定义没有依赖的模块 |
引入使用模块:
1 | define(function (require) { |
(2)sea.js简单使用教程
①下载sea.js, 并引入
- 官网: http://seajs.org/
- github : https://github.com/seajs/seajs
然后将sea.js导入项目: js/libs/sea.js
②创建项目结构
1 | |-js |
③定义sea.js的模块代码
1 | // module1.js文件 |
④在index.html中引入
1 | <script type="text/javascript" src="js/libs/sea.js"></script> |
最后得到结果如下:

2.2.4 ES6模块化
ES6 模块的设计思想是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。CommonJS 和 AMD 模块,都只能在运行时确定这些东西。比如,CommonJS 模块就是对象,输入时必须查找对象属性。
(1)ES6模块化语法
export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。
1 | /** 定义模块 math.js **/ |
如上例所示,使用import命令的时候,用户需要知道所要加载的变量名或函数名,否则无法加载。为了给用户提供方便,让他们不用阅读文档就能加载模块,就要用到export default命令,为模块指定默认输出。
1 | // export-default.js |
模块默认输出, 其他模块加载该模块时,import命令可以为该匿名函数指定任意名字。
(2)ES6 模块与 CommonJS 模块的差异
它们有两个重大差异:
① CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
② CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
第二个差异是因为 CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
下面重点解释第一个差异,我们还是举上面那个CommonJS模块的加载机制例子:
1 | // lib.js |
ES6 模块的运行机制与 CommonJS 不一样。ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
(3) ES6-Babel-Browserify使用教程
简单来说就一句话:使用Babel将ES6编译为ES5代码,使用Browserify编译打包js。
①定义package.json文件
1 | { |
②安装babel-cli, babel-preset-es2015和browserify
npm install babel-cli browserify -g
npm install babel-preset-es2015 –save-dev
preset 预设(将es6转换成es5的所有插件打包)
③定义.babelrc文件
1 | { |
④定义模块代码
1 | //module1.js文件 |
⑤ 编译并在index.html中引入
- 使用Babel将ES6编译为ES5代码(但包含CommonJS语法) :
babel js/src -d js/lib - 使用Browserify编译js :
browserify js/lib/app.js -o js/lib/bundle.js
然后在index.html文件中引入
1 | <script type="text/javascript" src="js/lib/bundle.js"></script> |
最后得到如下结果:

此外第三方库(以jQuery为例)如何引入呢?
首先安装依赖npm install jquery@1
然后在app.js文件中引入
1 | //app.js文件 |
2.3 总结
- CommonJS规范主要用于服务端编程,加载模块是同步的,这并不适合在浏览器环境,因为同步意味着阻塞加载,浏览器资源是异步加载的,因此有了AMD CMD解决方案。
- AMD规范在浏览器环境中异步加载模块,而且可以并行加载多个模块。不过,AMD规范开发成本高,代码的阅读和书写比较困难,模块定义方式的语义不顺畅。
- CMD规范与AMD规范很相似,都用于浏览器编程,依赖就近,延迟执行,可以很容易在Node.js中运行。不过,依赖SPM 打包,模块的加载逻辑偏重
- ES6 在语言标准的层面上,实现了模块功能,而且实现得相当简单,完全可以取代 CommonJS 和 AMD 规范,成为浏览器和服务器通用的模块解决方案。
3.Tree-Shaking
3.1 什么是Tree-shaking

先来看一下Tree-shaking原始的本意

上图形象的解释了Tree-shaking 的本意,本文所说的前端中的tree-shaking可以理解为通过工具”摇”我们的JS文件,将其中用不到的代码”摇”掉,是一个性能优化的范畴。具体来说,在 webpack 项目中,有一个入口文件,相当于一棵树的主干,入口文件有很多依赖的模块,相当于树枝。实际情况中,虽然依赖了某个模块,但其实只使用其中的某些功能。通过 tree-shaking,将没有使用的模块摇掉,这样来达到删除无用代码的目的。

Tree-shaking 较早由 Rich_Harris 的 rollup 实现,后来,webpack2 也增加了tree-shaking 的功能。其实在更早,google closure compiler 也做过类似的事情。三个工具的效果和使用各不相同,使用方法可以通过官网文档去了解,三者的效果对比,后文会详细介绍。
3.2 tree-shaking的原理

Tree-shaking的本质是消除无用的js代码。无用代码消除在广泛存在于传统的编程语言编译器中,编译器可以判断出某些代码根本不影响输出,然后消除这些代码,这个称之为DCE(dead code elimination)。
Tree-shaking 是 DCE 的一种新的实现,Javascript同传统的编程语言不同的是,javascript绝大多数情况需要通过网络进行加载,然后执行,加载的文件大小越小,整体执行时间更短,所以去除无用代码以减少文件体积,对javascript来说更有意义。
Tree-shaking 和传统的 DCE的方法又不太一样,传统的DCE 消灭不可能执行的代码,而Tree-shaking 更关注宇消除没有用到的代码。下面详细介绍一下DCE和Tree-shaking。
(1)先来看一下DCE消除大法

Dead Code 一般具有以下几个特征
•代码不会被执行,不可到达
•代码执行的结果不会被用到
•代码只会影响死变量(只写不读)
下面红框标示的代码就属于死码,满足以上特征
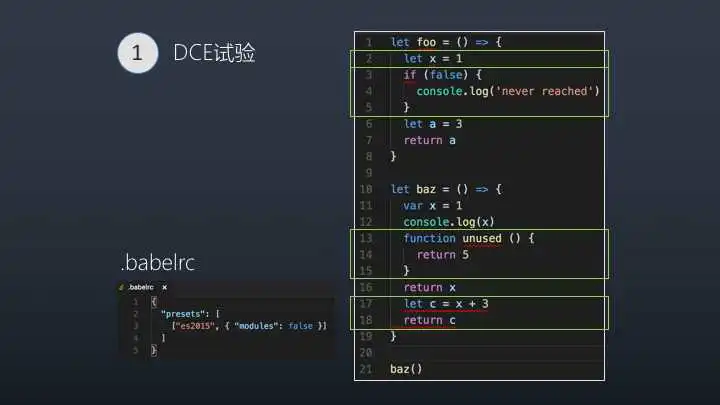
传统编译型的语言中,都是由编译器将Dead Code从AST(抽象语法树)中删除,那javascript中是由谁做DCE呢?
首先肯定不是浏览器做DCE,因为当我们的代码送到浏览器,那还谈什么消除无法执行的代码来优化呢,所以肯定是送到浏览器之前的步骤进行优化。
其实也不是上面提到的三个工具,rollup,webpack,cc做的,而是著名的代码压缩优化工具uglify,uglify完成了javascript的DCE,下面通过一个实验来验证一下。
以下所有的示例代码都能在github中找到github.com/lin-xi/tree…
分别用rollup和webpack将图4中的代码进行打包
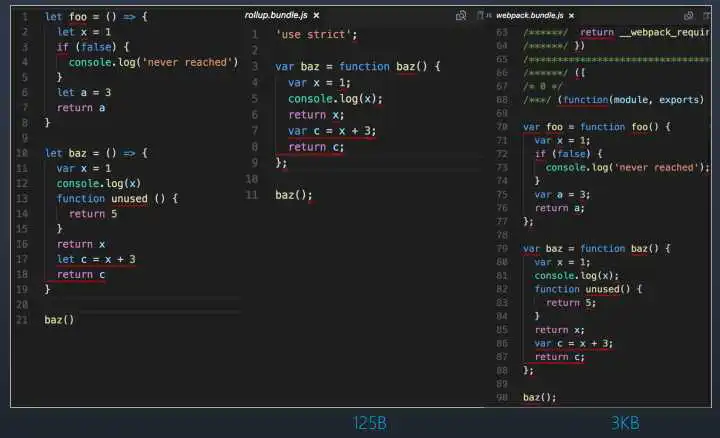
中间是rollup打包的结果,右边是webpack打包的结果
可以发现,rollup将无用的代码foo函数和unused函数消除了,但是仍然保留了不会执行到的代码,而webpack完整的保留了所有的无用代码和不会执行到的代码。
分别用rollup + uglify和 webpack + uglify 将图4中的代码进行打包
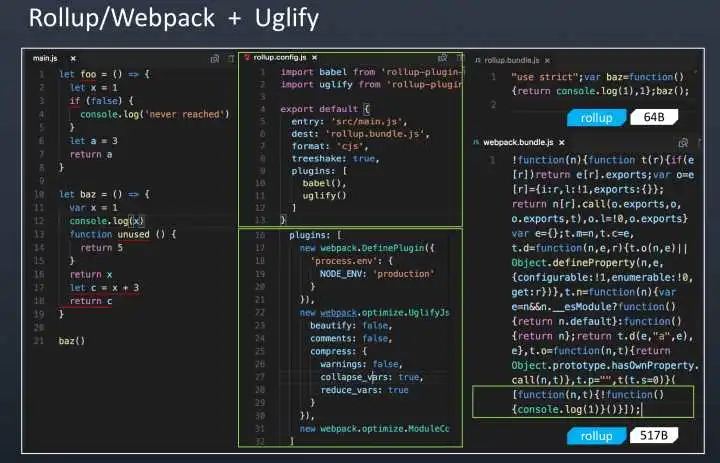
图6
中间是配置文件,右侧是结果
可以看到右侧最终打包结果中都去除了无法执行到的代码,结果符合我们的预期。
(2) 再看一下Tree-shaking消除大法
前面提到了tree-shaking更关注于无用模块的消除,消除那些引用了但并没有被使用的模块。
先思考一个问题,为什么tree-shaking是最近几年流行起来了?而前端模块化概念已经有很多年历史了,其实tree-shaking的消除原理是依赖于ES6的模块特性。

ES6 module 特点:
- 只能作为模块顶层的语句出现
- import 的模块名只能是字符串常量
- import binding 是 immutable的
ES6模块依赖关系是确定的,和运行时的状态无关,可以进行可靠的静态分析,这就是tree-shaking的基础。
所谓静态分析就是不执行代码,从字面量上对代码进行分析,ES6之前的模块化,比如我们可以动态require一个模块,只有执行后才知道引用的什么模块,这个就不能通过静态分析去做优化。
这是 ES6 modules 在设计时的一个重要考量,也是为什么没有直接采用 CommonJS,正是基于这个基础上,才使得 tree-shaking 成为可能,这也是为什么 rollup 和 webpack 2 都要用 ES6 module syntax 才能 tree-shaking。
我们还是通过例子来详细了解一下
面向过程编程函数和面向对象编程是javascript最常用的编程模式和代码组织方式,从这两个方面来实验:
- 函数消除实验
- 类消除实验
先看下函数消除实验
utils中get方法没有被使用到,我们期望的是get方法最终被消除。
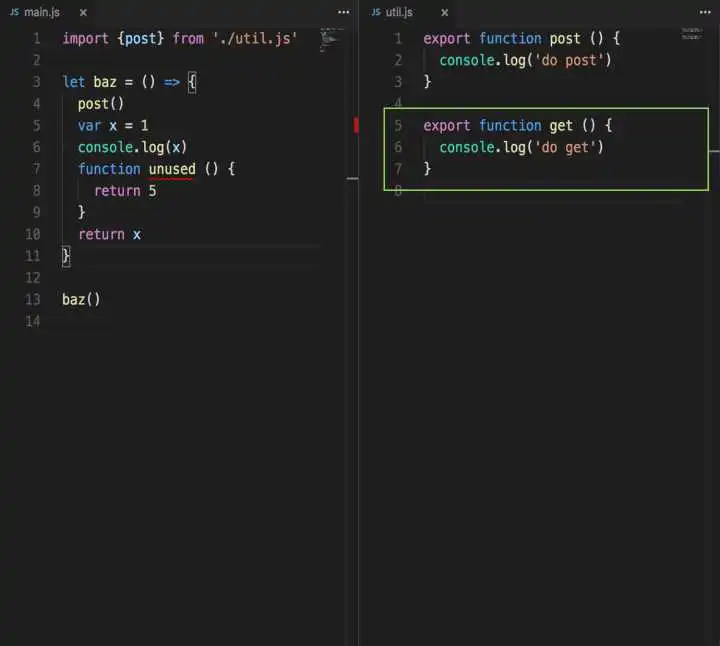
注意,uglify目前不会跨文件去做DCE,所以上面这种情况,uglify是不能优化的。
先看看rollup的打包结果
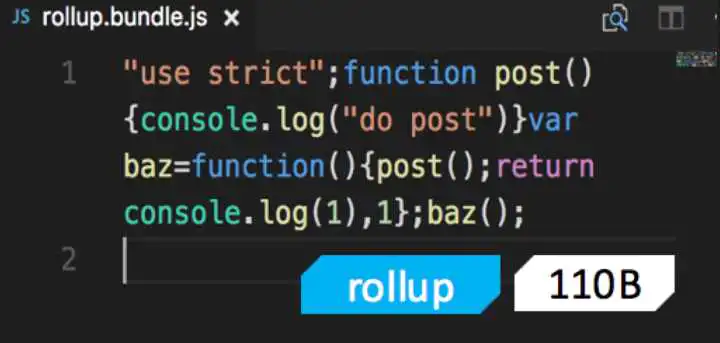
完全符合预期,最终结果中没有get方法
再看看webpack的结果
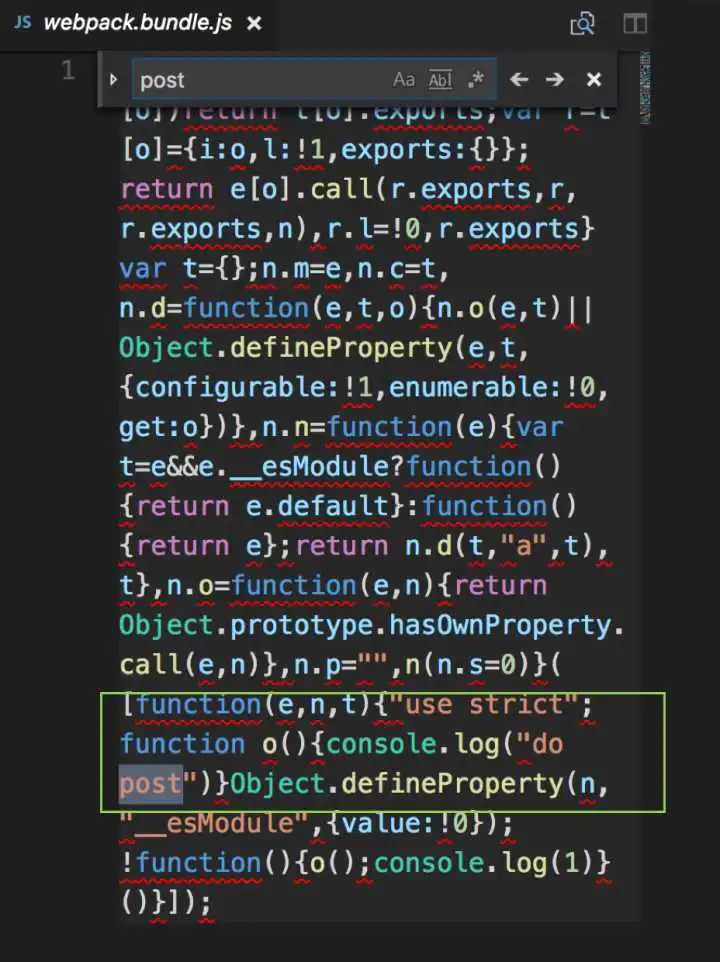
也符合预期,最终结果中没有get方法
可以看到rollup打包的结果比webpack更优化
函数消除实验中,rollup和webpack都通过,符合预期
再来看下类消除实验
增加了对menu.js的引用,但其实代码中并没有用到menu的任何方法和变量,所以我们的期望是,最终代码中menu.js里的内容被消除
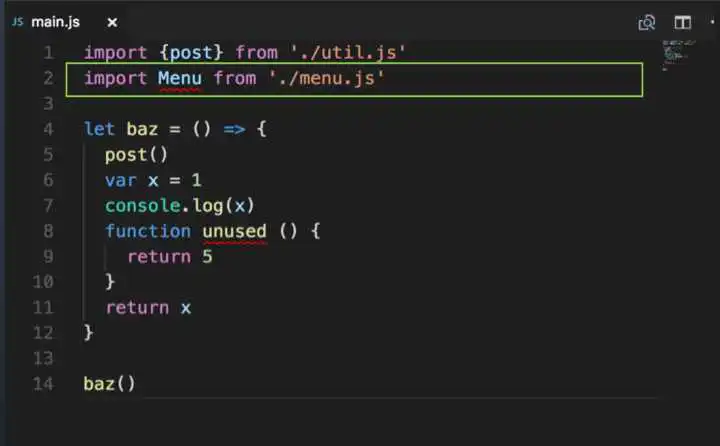
main.js
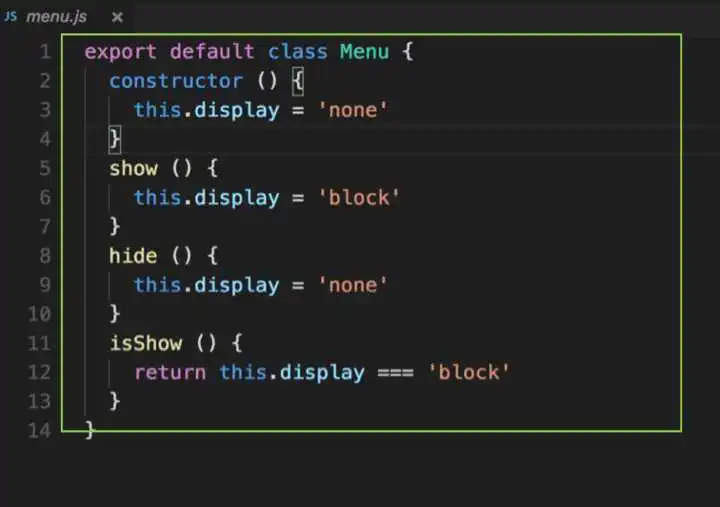
menu.js
rollup打包结果
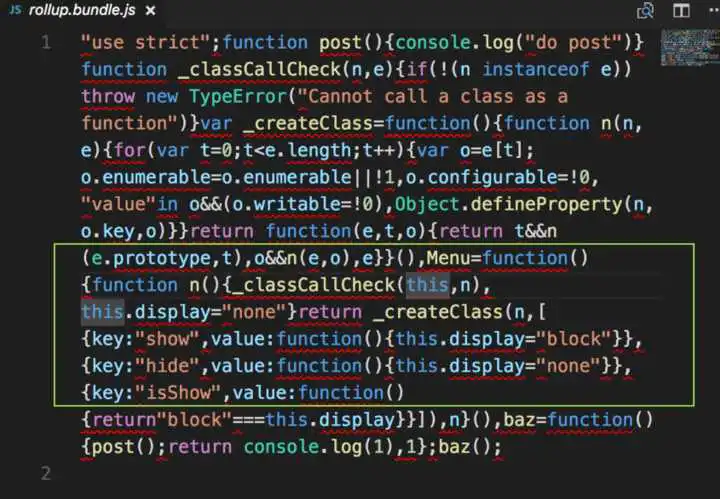
包中竟然包含了menu.js的全部代码
webpack打包结果
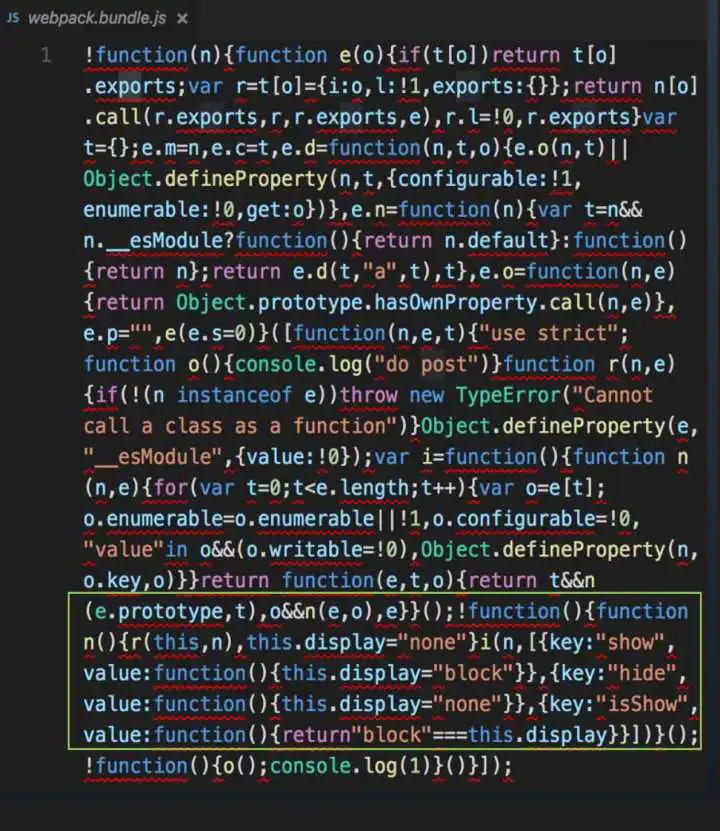
包中竟然也包含了menu.js的全部代码
类消除实验中,rollup,webpack 全军覆没,都没有达到预期
这跟我们想象的完全不一样啊?为什么呢?无用的类不能消除,这还能叫做tree-shaking吗?我当时一度怀疑自己的demo有问题,后来各种网上搜索,才明白demo没有错。
下面摘取了rollup核心贡献者的的一些回答:
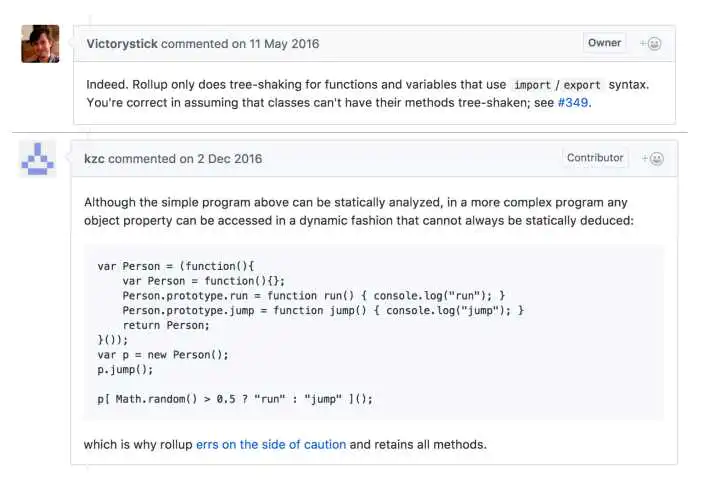
图7
- rollup只处理函数和顶层的import/export变量,不能把没用到的类的方法消除掉
- javascript动态语言的特性使得静态分析比较困难
- 图7下部分的代码就是副作用的一个例子,如果静态分析的时候删除里run或者jump,程序运行时就可能报错,那就本末倒置了,我们的目的是优化,肯定不能影响执行
再举个例子说明下为什么不能消除menu.js,比如下面这个场景
1 | function Menu() { |
如果删除里menu.js,那对Array的扩展也会被删除,就会影响功能。那也许你会问,难道rollup,webpack不能区分是定义Menu的proptotype 还是定义Array的proptotype吗?当然如果代码写成上面这种形式是可以区分的,如果我写成这样呢?
1 | function Menu() { |
这种代码,静态分析是分析不了的,就算能静态分析代码,想要正确完全的分析也比较困难。
更多关于副作用的讨论,可以看这个

Tree shaking class methods · Issue #349 · rollup/rollupgithub.com

tree-shaking对函数效果较好
函数的副作用相对较少,顶层函数相对来说更容易分析,加上babel默认都是”use strict”严格模式,减少顶层函数的动态访问的方式,也更容易分析
我们开始说的三个工具,rollup和webpack表现不理想,那closure compiler又如何呢?
将示例中的代码用cc打包后得到的结果如下:
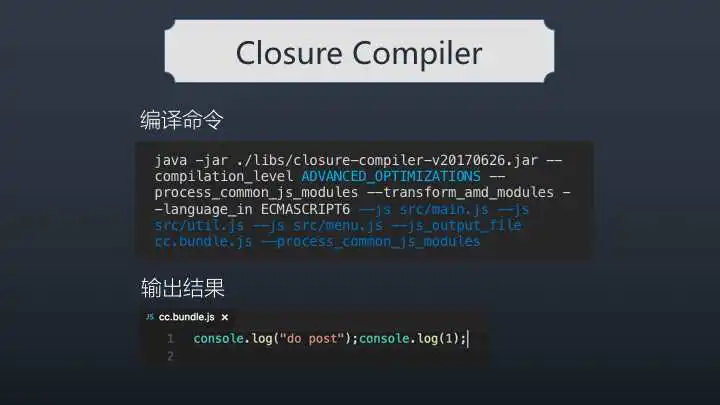
天啊,这不就是我们要的结果吗?完美消除所有无用代码的结果,输出的结果非常性感
closure compiler, tree-shaking的结果完美!
可是不能高兴得太早,能得到这么完美结果是需要条件的,那就是cc的侵入式约束规范。必须在代码里添加这样的代码,看红线框标示的
google定义一整套注解规范Annotating JavaScript for the Closure Compiler,想更多了解的,可以去看下官网。
侵入式这个就让人很不爽,google Closure Compiler是java写的,和我们基于node的各种构建库不可能兼容(不过目前好像已经有nodejs版 Closure Compiler),Closure Compiler使用起来也比较麻烦,所以虽然效果很赞,但比较难以应用到项目中,迁移成本较大。
说了这么多,总结一下:
三大工具的tree-shaking对于无用代码,无用模块的消除,都是有限的,有条件的。closure compiler是最好的,但与我们日常的基于node的开发流很难兼容。
tree-shaking对web意义重大,是一个极致优化的理想世界,是前端进化的又一个终极理想。
理想是美好的,但目前还处在发展阶段,还比较困难,有各个方面的,甚至有目前看来无法解
决的问题,但还是应该相信新技术能带来更好的前端世界。
优化是一种态度,不因小而不为,不因艰而不攻。
3.3 tree-shaking实践
webpack2 发布,宣布支持tree-shaking,webpack 3发布,支持作用域提升,生成的bundle文件更小。 再没有升级webpack之前,增幻想我们的性能又要大幅提升了,对升级充满了期待。实际上事实是这样的
升级完之后,bundle文件大小并没有大幅减少,当时有较大的心理落差,然后去研究了为什么效果不理想,原因见 Tree-Shaking性能优化实践 - 原理篇 。
优化还是要继续的,虽然工具自带的tree-shaking不能去除太多无用代码,在去除无用代码这一方面也还是有可以做的事情。我们从三个方面做里一些优化。
(1)对组件库引用的优化
先来看一个问题
当我们使用组件库的时候,import {Button} from ‘element-ui’,相对于Vue.use(elementUI),已经是具有性能意识,是比较推荐的做法,但如果我们写成右边的形式,具体到文件的引用,打包之后的区别是非常大的,以antd为例,右边形式bundle体积减少约80%。
这个引用也属于有副作用,webpack不能把其他组件进行tree-shaking。既然工具本身是做不了,那我们可以做工具把左边代码自动改成右边代码这种形式。这个工具antd库本身也是提供的。我在antd的工具基础上做了少量的修改,不用任何配置,原生支持我们自己的组件库, wui 和 xcui 以及一些其他常用的库
babel-plugin-import-fix ,缩小引用范围
lin-xi/babel-plugin-import-fix
下面介绍一下原理
这是一个babel的插件,babel通过核心babylon将ES6代码转换成AST抽象语法树,然后插件遍历语法树找出类似import {Button} from ‘element-ui’这样的语句,进行转换,最后重新生成代码。
babel-plugin-import-fix默认支持antd,element,meterial-UI,wui,xcui和d3,只需要再.babelrc中配置插件本身就可以。
.babelrc
1 | { |
其实是想把所有常用的库都默认支持,但很多常用的库却不支持缩小引用范围。因为没有独立输出各个子模块,不能把引用修改为对单个子模块的引用。
(2)CSS Tree-shaking
我们前面所说的tree-shaking都是针对js文件,通过静态分析,尽可能消除无用的代码,那对于css我们能做tree-shaking吗?
随着CSS3,LESS,SASS等各种css预处理语言的普及,css文件在整个工程中占比是不可忽视的。随着大项目功能的不停迭代,导致css中可能就存在着无用的代码。我实现了一个webpack插件来解决这个问题,找出css代码无用的代码。
webpack-css-treeshaking-plugin,对css进行tree-shaking
webpack-css-treeshaking-plugin
下面介绍一下原理
整体思路是这样的,遍历所有的css文件中的selector选择器,然后去所有js代码中匹配,如果选择器没有在代码出现过,则认为该选择器是无用代码。
首先面临的问题是,如何优雅的遍历所有的选择器呢?难道要用正则表达式很苦逼的去匹配分割吗?
babel是js世界的福星,其实css世界也有利器,那就是postCss。
PostCSS 提供了一个解析器,它能够将 CSS 解析成AST抽象语法树。然后我们能写各种插件,对抽象语法树做处理,最终生成新的css文件,以达到对css进行精确修改的目的。
整体又是一个webpack的插件,架构图如下:
主要流程:
- 插件监听webapck编译完成事件,webpack编译完成之后,从compilation中找出所有的css文件和js文件
1 | apply (compiler) { |
- 将所有的css文件送至postCss处理,找出无用代码
1 | let tasks = [] |
- postCss 遍历,匹配,删除过程
1 | module.exports = postcss.plugin('list-selectors', function (options) { |
checkRule 处理每一个规则核心代码
1 | let checkRule = (rule) => { |
可以看到其实我只处理里 id选择器和class选择器,id和class相对来说副作用小,引起样式异常的可能性相对较小。
判断css是否再js中出现过,是使用正则匹配。
其实,后续还可以继续优化,比如对tag类的选择器,可以配置是否再html,jsx,template中出现过,如果出现过,没有出现过也可以认为是无用代码。
当然,插件能正常工作还是的有一些前提和约束。我们可以在代码中动态改变css,比如再react和vue中,可以这么写
这样是比较推荐的方式,选择器作为字符或变量名出现在代码中,下面这样动态生成选择器的情况就会导致匹配失败
1 | render(){ |
其中这样情况很容易避免
1 | render(){ |
所以有一个好的编码规范的约束,插件能更好的工作。
(3)webpack bundle文件去重
如果webpack打包后的bundle文件中存在着相同的模块,也属于无用代码的一种。也应该被去除掉
首先我们需要一个能对bundle文件定性分析的工具,能发现问题,能看出优化效果。
webpack-bundle-analyzer这个插件完全能满足我们的需求,他能以图形化的方式展示bundle中所有的模块的构成的各构成的大小。
其次,需求对通用模块进行提取,CommonsChunkPlugin是最被人熟知的用于提供通用模块的插件。早期的时候,我并不完全了解他的功能,并没有发挥最大的功效。
下面介绍CommonsChunkPlugin的正确用法
自动提取所有的node_moudles或者引用次数两次以上的模块
minChunks可以接受一个数值或者函数,如果是函数,可自定义打包规则
但使用上面记载的配置之后,并不能高枕无忧。因为这个配置只能提取所有entry打包后的文件中的通用模块。而现实是,有了提高性能,我们会按需加载,通过webpack提供的import(…)方法,这种按需加载的文件并不会存在于entry之中,所以按需加载的异步模块中的通用模块并没有提取。
如何提取按需加载的异步模块里的通用模块呢?
配置另一个CommonsChunkPlugin,添加async属性,async可以接受布尔值或字符串。当时字符串时,默认是输出文件的名称。
names是所有异步模块的名称
这里还涉及一个给异步模块命名的知识点。我是这样做的:
1 | const Edit = resolve => { import( /* webpackChunkName: "EditPage" */ './pages/Edit/Edit').then((mod) => { resolve(mod.default); }) }; |
没错,在import里添加注释。/* webpackChunkName: “EditPage” */ ,虽然看着不舒服,但是管用。
贴一个项目的优化效果对比图
优化效果还是比较明显。
优化前bundle
优化后bundle
最后思考一个问题:
不同entry模块或按需加载的异步模块需不需要提取通用模块?
这个需要看场景了,比如模块都是在线加载的,如果通用模块提取粒度过小,会导致首页首屏需要的文件变多,很多可能是首屏用不到的,导致首屏过慢,二级或三级页面加载会大幅提升。所以这个就需要根据业务场景做权衡,控制通用模块提取的粒度。
百度外卖的移动端应用场景是这样的,我们所有的移动端页面都做了离线化的处理。离线之后,加载本地的js文件,与网络无关,基本上可以忽略文件大小,所以更关注整个离线包的大小。离线包越小,耗费用户的流量就越小,用户体验更好,所以离线化的场景是非常适合最小粒提取通用模块的,即将所有entry模块和异步加载模块的引用大于2的模块都提取,这样能获得最小的输出文件,最小的离线包。
4.uglify原理
4.1 AST(抽象语法树)
要想了解JS的压缩原理,需要首先了解AST。
1 | 抽象语法树:AST(Abstract Syntax Tree),是源代码的抽象语法结构的树状表现形式,这里特指编程语言的源代码。树上的每个节点都表示源代码中的一种结构。之所以说语法是「抽象」的,是因为这里的语法并不会表示出真实语法中出现的每个细节。 |
举个例子:


从上面两个例子中,可以看出AST是源代码根据其语法结构,省略一些细节(比如:括号没有生成节点),抽象成树形表达。抽象语法树在计算机科学中有很多应用,比如编译器、IDE、压缩代码、格式化代码等。[1]
4.2 代码压缩原理
了解了AST之后,我们再分析一下JS的代码压缩原理。简单的说,就是
1 | 1. 将code转换成AST |
PS:具体的AST树大家可以在astexplorer上在线获得
babel,eslint,v8的逻辑均与此类似,下图是我们引用了babel的转化示意图:
以我们之前被质疑的代码为例,看看它在uglify中是怎么样一步一步被压缩的:
1 | // uglify-js的版本需要为2.x, 3.0之后uglifyjs不再暴露Compressor api |
到这里,我们已经了解了uglifyjs的代码压缩原理,但是还没有解决一个问题——为什么某些语句间的分号会被转换为逗号,某些不会转换。这就涉及到了uglifyjs的压缩规则。
4.3 代码压缩规则
由于uglifyjs的代码压缩规则很多,我们这里只分析与本文中相关的部分:
1 | uglifyjs的全部压缩规则可以参见:《[解读uglifyJS(四)——Javascript代码压缩](https://rapheal.sinaapp.com/2014/05/22/uglifyjs-squeeze/#more-705)》 |

PS:在线demo
这其中需要注意的是只有“表达式语句”才能被合并,那么什么是表达式语句呢?
表达式 VS 语句 VS 表达式语句
例如:
1 | a; //返回a的值 |
例如:
1 | if(x > 0) { |
例如:
1 | A(); |
综上所述,因为a = 123 和 delete x都是表达式语句,所以分号被转换为逗号。而var x = {b:123}则因为是声明语句,所以和a=123不会合并,分号不会被转换。但var x = {b:123}和第一行var a又触发了另外一条规则,
所以第一行和第二行会被合并为var a,x={b:123}
4.4 总结
在本文中,我们讨论了什么是抽象语法树,uglifyjs的压缩原理,以及相应的压缩规则,最终明晰了为什么代码会被压缩成我们得到的样子,希望对大家有所帮助。
参考文献
[1]《抽象语法树在 JavaScript 中的应用》
[2]《javascript 代码是如何被压缩的》
[3]《[译]JavaScript中:表达式和语句的区别》
[4]《解读uglifyJS(四)——Javascript代码压缩》
5.Babel原理
5.1 什么是 AST
抽象语法树(Abstract Syntax Tree)简称 AST,是源代码的抽象语法结构的树状表现形式。webpack、eslint 等很多工具库的核心都是通过抽象语法树这个概念来实现对代码的检查、分析等操作。今天我为大家分享一下 JavaScript 这类解释型语言的抽象语法树的概念
我们常用的浏览器就是通过将 js 代码转化为抽象语法树来进行下一步的分析等其他操作。所以将 js 转化为抽象语法树更利于程序的分析。
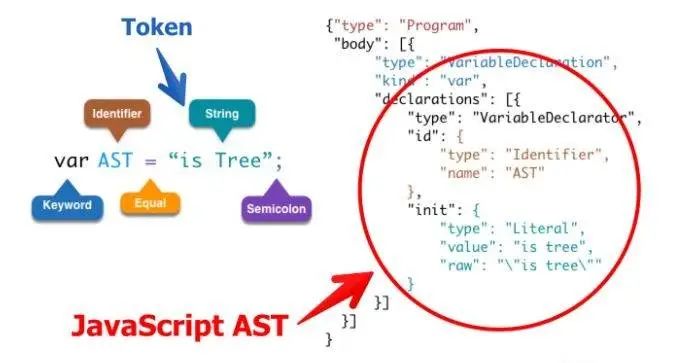
如上图中变量声明语句,转换为 AST 之后就是右图中显示的样式
左图中对应的:
var是一个关键字AST是一个定义者=是 Equal 等号的叫法有很多形式,在后面我们还会看到is tree是一个字符串;就是 Semicoion
首先一段代码转换成的抽象语法树是一个对象,该对象会有一个顶级的 type 属性 Program;第二个属性是 body 是一个数组。
body 数组中存放的每一项都是一个对象,里面包含了所有的对于该语句的描述信息
1 | type: 描述该语句的类型 --> 变量声明的语句 |
5.2 词法分析和语法分析
JavaScript 是解释型语言,一般通过 词法分析 -> 语法分析 -> 语法树,就可以开始解释执行了
词法分析:也叫扫描,是将字符流转换为记号流(tokens),它会读取我们的代码然后按照一定的规则合成一个个的标识
比如说:var a = 2 ,这段代码通常会被分解成 var、a、=、2
1 | ;[ |
当词法分析源代码的时候,它会一个一个字符的读取代码,所以很形象地称之为扫描 - scans。当它遇到空格、操作符,或者特殊符号的时候,它会认为一个话已经完成了。
语法分析:也称解析器,将词法分析出来的数组转换成树的形式,同时验证语法。语法如果有错的话,抛出语法错误。
1 | { ... "type": "VariableDeclarator", "id": { "type": "Identifier", "name": "a" }, ...} |
语法分析成 AST ,我们可以在这里在线看到效果 http://esprima.org
5.3 AST 能做什么
- 语法检查、代码风格检查、格式化代码、语法高亮、错误提示、自动补全等
- 代码混淆压缩
- 优化变更代码,改变代码结构等
比如说,有个函数 function a() {} 我想把它变成 function b() {}
比如说,在 webpack 中代码编译完成后 require('a') --> __webapck__require__("*/**/a.js")
下面来介绍一套工具,可以把代码转成语法树然后改变节点以及重新生成代码
5.4 AST 解析流程
准备工具:
- esprima:code => ast 代码转 ast
- estraverse: traverse ast 转换树
- escodegen: ast => code
在推荐一个常用的 AST 在线转换网站:https://astexplorer.net/
比如说一段代码 function getUser() {},我们把函数名字更改为 hello,看代码流程
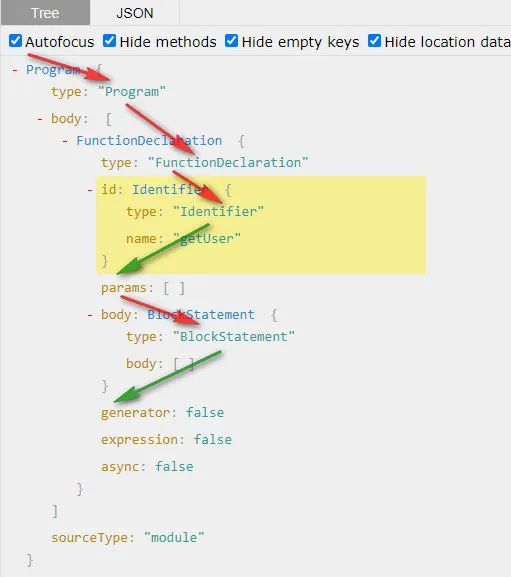
看以下代码,简单说明 AST 遍历流程
1 | const esprima = require('esprima') |
输出结果如下:
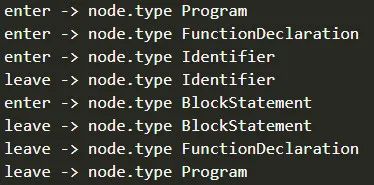
由此可以得到 AST 遍历的流程是深度优先,遍历过程如下:
5.5 修改函数名字
此时我们发现函数的名字在 type 为 Identifier 的时候就是该函数的名字,我们就可以直接修改它便可实现一个更改函数名字的 AST 工具

1 | // 转换树 |
5.6 babel 工作原理
提到 AST 我们肯定会想到 babel,自从 Es6 开始大规模使用以来,babel 就出现了,它主要解决了就是一些浏览器不兼容 Es6 新特性的问题,其实就把 Es6 代码转换为 Es5 的代码,兼容所有浏览器,babel 转换代码其实就是用了 AST,babel 与 AST 就有着很一种特别的关系。
那么我们就在 babel 的中来使用 AST,看看 babel 是如何编译代码的(不讲源码啊)
需要用到两个工具包 @babel/core、@babel/preset-env
当我们配置 babel 的时候,不管是在 .babelrc 或者 babel.config.js 文件里面配置的都有 presets 和 plugins 两个配置项(还有其他配置项,这里不做介绍)
5.6.1 插件和预设的区别
1 | // .babelrc |
当我们配置了 presets 中有 @babel/preset-env,那么 @babel/core 就会去找 preset-env 预设的插件包,它是一套
babel 核心包并不会去转换代码,核心包只提供一些核心 API,真正的代码转换工作由插件或者预设来完成,比如要转换箭头函数,会用到这个 plugin,@babel/plugin-transform-arrow-functions,当需要转换的要求增加时,我们不可能去一一配置相应的 plugin,这个时候就可以用到预设了,也就是 presets。presets 是 plugins 的集合,一个 presets 内部包含了很多 plugin。
5.6.2 babel 插件的使用
现在我们有一个箭头函数,要想把它转成普通函数,我们就可以直接这么写:
1 | const babel = require('@babel/core') |
此时我们可以看到最终代码会被转成普通函数,但是我们,只需要箭头函数转通函数的功能,不需要用这么大一套包,只需要一个箭头函数转普通函数的包,我们其实是可以在 node_modules 下面找到有个叫做 plugin-transform-arrow-functions 的插件,这个插件是专门用来处理 箭头函数的,我们就可以这么写:
1 | const r = babel.transform(code, { |
我们可以从打印结果发现此时并没有转换我们变量的声明方式还是 const 声明,只是转换了箭头函数
5.7 编写自己的插件
此时,我们就可以自己来写一些插件,来实现代码的转换,中间处理代码的过程就是使用前面提到的 AST 的处理逻辑
现在我们来个实战把 const fn = (a, b) => a + b 转换为 const fn = function(a, b) { return a + b }
5.7.1 分析 AST 结构
首先我们在在线分析 AST 的网站上分析 const fn = (a, b) => a + b 和 const fn = function(a, b) { return a + b }看两者语法树的区别
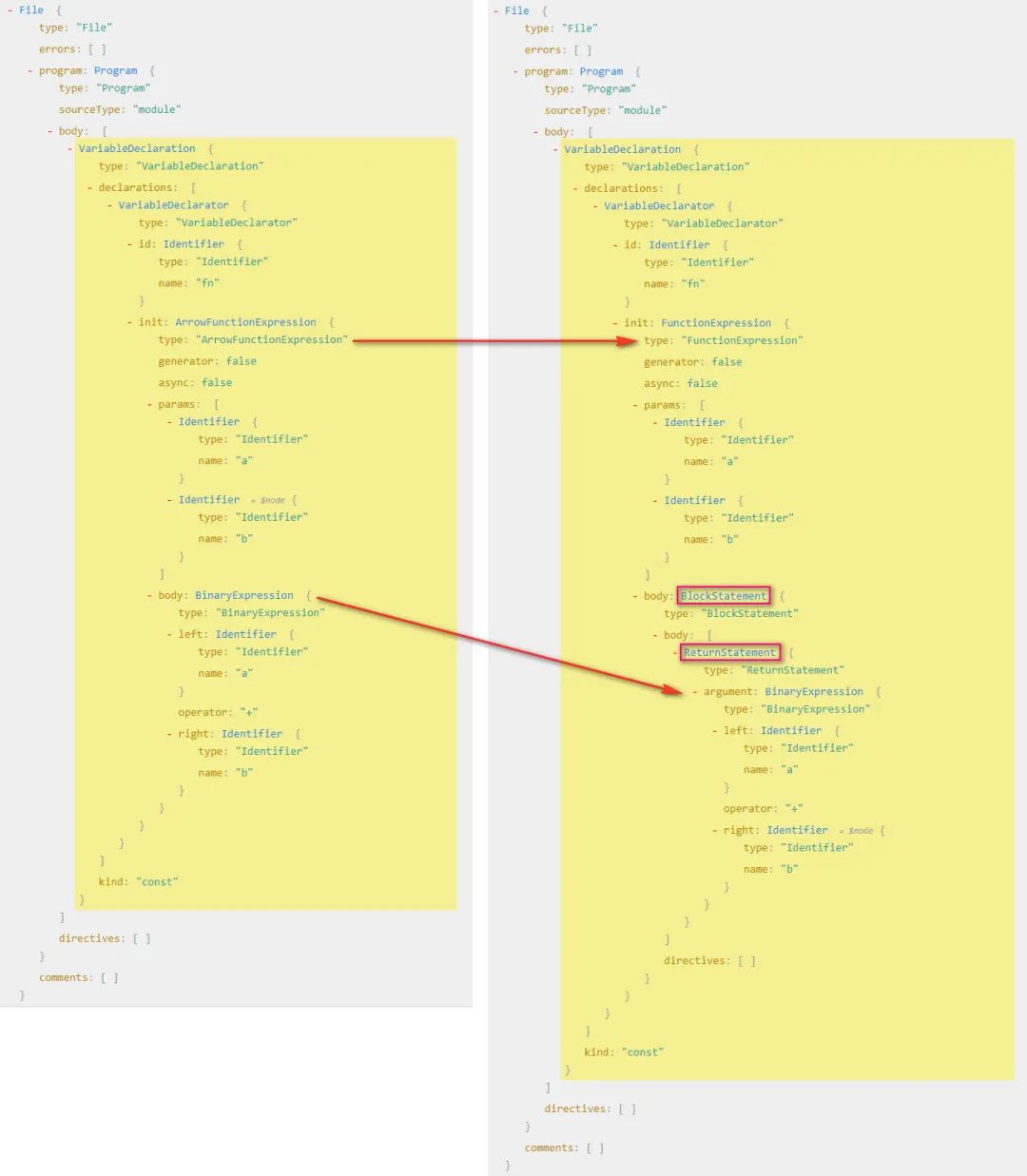
根据我们分析可得:
- 变成普通函数之后他就不叫箭头函数了
ArrowFunctionExpression,而是函数表达式了FunctionExpression - 所以首先我们要把
箭头函数表达式(ArrowFunctionExpression)转换为函数表达式(FunctionExpression) - 要把
二进制表达式(BinaryExpression)放到一个代码块中(BlockStatement) - 其实我们要做就是把一棵树变成另外一颗树,说白了其实就是拼成另一颗树的结构,然后生成新的代码,就可以完成代码的转换
5.7.2 访问者模式
在 babel 中,我们开发 plugins 的时候要用到访问者模式,就是说在访问到某一个路径的时候进行匹配,然后在对这个节点进行修改,比如说上面的当我们访问到 ArrowFunctionExpression 的时候,对 ArrowFunctionExpression 进行修改,变成普通函数
那么我们就可以这么写:
1 | const babel = require('@babel/core') |
5.7.3 修改 AST 结构
此时我们拿到的结果是这样的节点结果是 这样的,其实就是 ArrowFunctionExpression 的 AST,此时我们要做的是把 ArrowFunctionExpression 的结构替换成 FunctionExpression的结构,但是需要我们组装类似的结构,这么直接写很麻烦,但是 babel 为我们提供了一个工具叫做 @babel/types
@babel/types 有两个作用:
- 判断这个节点是不是这个节点(ArrowFunctionExpression 下面的 path.node 是不是一个 ArrowFunctionExpression)
- 生成对应的表达式
然后我们使用的时候,需要经常查文档,因为里面的节点类型特别多,不是做编译相关工作的是记不住怎么多节点的
那么接下来我们就开始生成一个 FunctionExpression,然后把之前的 ArrowFunctionExpression 替换掉,我们可以看 types 文档,找到 functionExpression,该方法接受相应的参数我们传递过去即可生成一个 FunctionExpression
1 | t.functionExpression(id, params, body, generator, async) |
- id: Identifier (default: null) id 可传递 null
- params: Array
(required) 函数参数,可以把之前的参数拿过来 - body: BlockStatement (required) 函数体,接受一个
BlockStatement我们需要生成一个 - generator: boolean (default: false) 是否为 generator 函数,当然不是了
- async: boolean (default: false) 是否为 async 函数,肯定不是了
还需要生成一个 BlockStatement,我们接着看文档找到 BlockStatement 接受的参数
1 | t.blockStatement(body, directives) |
看文档说明,blockStatement 接受一个 body,那我们把之前的 body 拿过来就可以直接用,不过这里 body 接受一个数组
我们细看 AST 结构,函数表达式中的 BlockStatement 中的 body 是一个 ReturnStatement,所以我们还需要生成一个 ReturnStatement
现在我们就可以改写 AST 了
1 | const babel = require('@babel/core') |
5.7.4 特殊情况
我们知道在剪头函数中是可以省略 return 关键字,我们上面是处理了省略关键字的写法,但是如果用户写了 return 关键字后,我们写的这个插件就有问题了,所以我们可以在优化一下
1 | const fn = (a, b) => { retrun a + b }` -> `const fn = function(a, b) { return a + b } |
观察代码我们发现,我们就不需要把 body 转换成 blockStatement 了,直接放过去就可以了,那么我们就可以这么写
1 | ArrowFunctionExpression(path) { |
5.8 按需引入
在开发中,我们引入 UI 框架,比如 vue 中用到的 element-ui,vant 或者 React 中的 antd 都支持全局引入和按需引入,默认是全局引入,如果需要按需引入就需要安装一个 babel-plugin-import 的插件,将全局的写法变成按需引入的写法。
就拿我最近开发移动端用的 vant 为例, import { Button } from 'vant' 这种写法经过这个插件之后会变成 import Button from 'vant/lib/Button' 这种写法,引用整个 vant 变成了我只用了 vant 下面的某一个文件,打包后的文件会比全部引入的文件大小要小很多
5.8.1 分析语法树
看一下两个语法树的区别
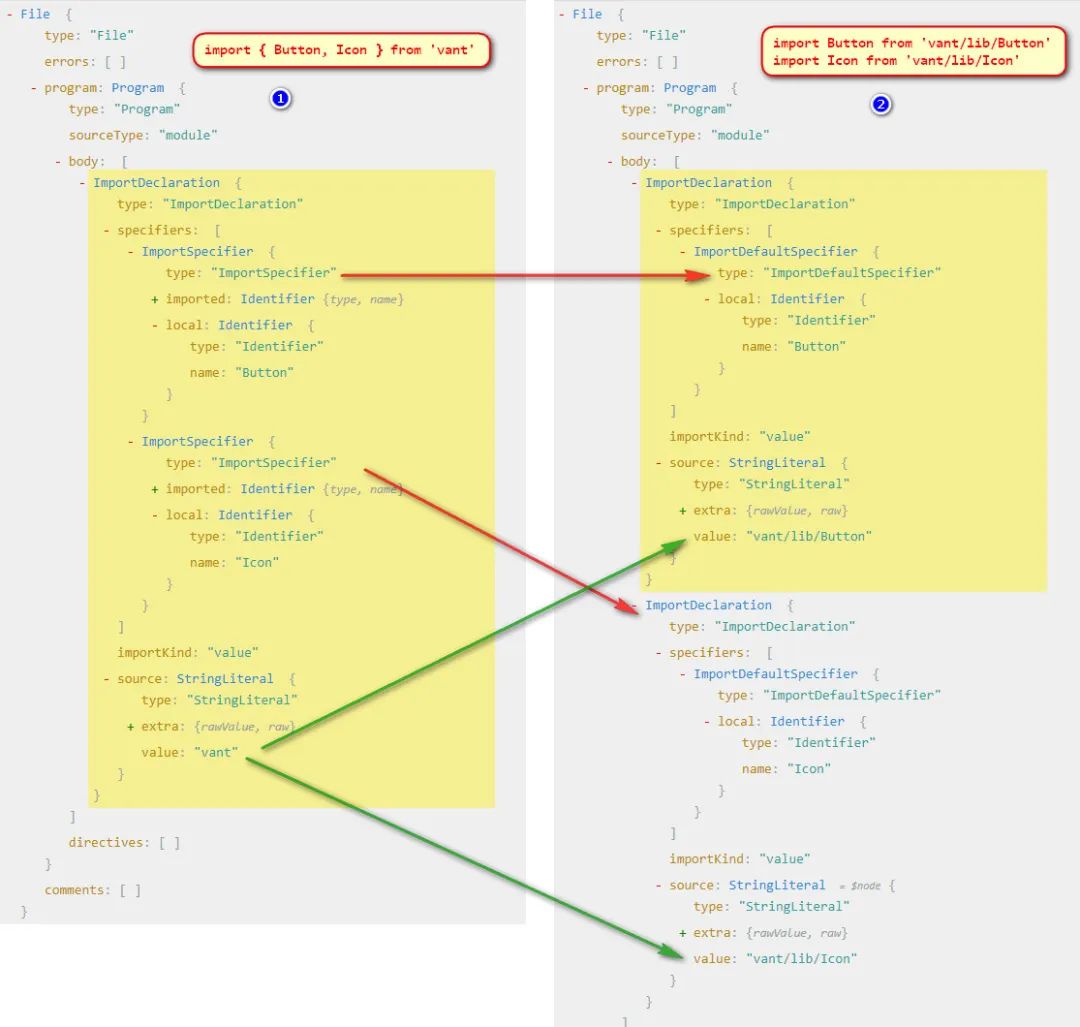
根据两张图分析我们可以得到一些信息:
- 我们发现解构方式引入的模块只有 import 声明,第二张图是两个 import 声明
- 解构方式引入的详细说明里面(
specifiers)是两个ImportSpecifier,第二张图里面是分开的,而且都是ImportDefaultSpecifier - 他们引入的
source也不一样 - 那我们要做的其实就是要把单个的
ImportDeclaration变成多个ImportDeclaration, 然后把单个 import 解构引入的specifiers部分ImportSpecifier转换成多个ImportDefaultSpecifier并修改对应的source即可
5.8.2 分析类型
为了方便传递参数,这次我们写到一个函数里面,可以方便传递转换后拼接的目录
这里我们需要用到的几个类型,也需要在 types 官网上找对应的解释
首先我们要生成多个
importDeclaration类型1
2
3
4
5/**
* @param {Array<ImportSpecifier | ImportDefaultSpecifier | ImportNamespaceSpecifier>} specifiers (required)
* @param {StringLiteral} source (required)
*/
t.importDeclaration(specifiers, source)在
importDeclaration中需要生成ImportDefaultSpecifier1
2
3
4/**
* @param {Identifier} local (required)
*/
t.importDefaultSpecifier(local)在
importDeclaration中还需要生成一个StringLiteral1
2
3
4/**
* @param {string} value (required)
*/
t.stringLiteral(value)
5.8.3 上代码
按照上面的分析,我们开始上代码
1 | const babel = require('@babel/core') |
看打印结果和转换结果似乎没什么问题,这个插件几乎就实现了
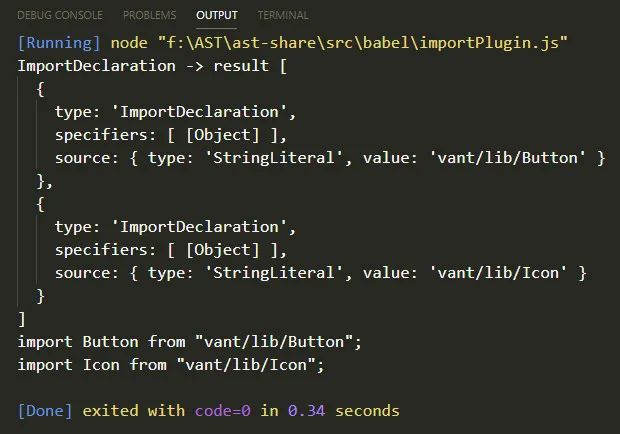
5.8.4 特殊情况
但是我们考虑一种情况,如果用户不全部按需加载了,按需加载只是一种选择,如果用户这么写了 import vant, { Button, Icon } from 'vant',那么我们这个插件就出现问题了
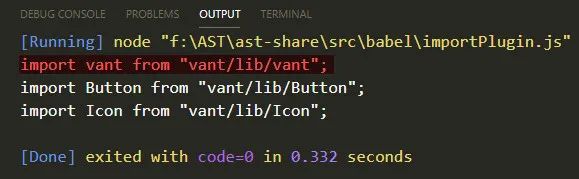
如果遇到这种写法,那么默认导入的他的 source 应该是不变的,我们要把原来的 source 拿出来
所以还需要判断一下,每一个 specifier 是不是一个 ImportDefaultSpecifier 然后处理不同的 source,完整处理逻辑应该如下
1 | function importPlugin(opt) { |
5.9 babylon
在 babel 官网上有一句话 Babylon is a JavaScript parser used in Babel.
5.9.1 babylon 与 babel 的关系
babel 使用的引擎是 babylon,Babylon 并非 babel 团队自己开发的,而是 fork 的 acorn 项目,acorn 的项目本人在很早之前在兴趣部落 1.0 在构建中使用,为了是做一些代码的转换,是很不错的一款引擎,不过 acorn 引擎只提供基本的解析 ast 的能力,遍历还需要配套的 acorn-travesal, 替换节点需要使用 acorn-,而这些开发,在 Babel 的插件体系开发下,变得一体化了(摘自 AlloyTeam 团队的剖析 babel)
5.9.2 使用 babylon
使用 babylon 编写一个数组 rest 转 Es5 语法的插件
把 const arr = [ ...arr1, ...arr2 ] 转成 var arr = [].concat(arr1, arr2)
我们使用 babylon 的话就不需要使用 @babel/core 了,只需要用到他里面的 traverse 和 generator,用到的包有 babylon、@babel/traverse、@babel/generator、@babel/types
5.9.3 分析语法树
先来看一下两棵语法树的区别

根据上图我们分析得出:
- 两棵树都是变量声明的方式,不同的是他们声明的关键字不一样
- 他们初始化变量值的时候是不一样的,一个数组表达式(ArrayExpression)另一个是调用表达式(CallExpression)
- 那我们要做的就很简单了,就是把 数组表达式转换为调用表达式就可以
5.9.4 分析类型
这段代码的核心生成一个 callExpression 调用表达式,所以对应官网上的类型,我们分析需要用到的 api
先来分析 init 里面的,首先是 callExpression
1
2
3
4
5/**
* @param {Expression} callee (required)
* @param {Array<Expression | SpreadElement | JSXNamespacedName>} source (required)
*/
t.callExpression(callee, arguments)对应语法树上 callee 是一个 MemberExpression,所以要生成一个成员表达式
1
2
3
4
5
6
7/**
* @param {Expression} object (required)
* @param {if computed then Expression else Identifier} property (required)
* @param {boolean} computed (default: false)
* @param {boolean} optional (default: null)
*/
t.memberExpression(object, property, computed, optional)在 callee 的 object 是一个 ArrayExpression 数组表达式,是一个空数组
1
2
3
4/**
* @param {Array<null | Expression | SpreadElement>} elements (default: [])
*/
t.arrayExpression(elements)对了里面的东西分析完了,我们还要生成 VariableDeclarator 和 VariableDeclaration 最终生成新的语法树
1
2
3
4
5
6
7
8
9
10
11/**
* @param {LVal} id (required)
* @param {Expression} init (default: null)
*/
t.variableDeclarator(id, init)
/**
* @param {"var" | "let" | "const"} kind (required)
* @param {Array<VariableDeclarator>} declarations (required)
*/
t.variableDeclaration(kind, declarations)其实倒着分析语法树,分析完怎么写也就清晰了,那么我们开始上代码吧
5.9.5 上代码
1 | const babylon = require('babylon') |
5.10 具体语法树
和抽象语法树相对的是具体语法树(Concrete Syntax Tree)简称 CST(通常称作分析树)。一般的,在源代码的翻译和编译过程中,语法分析器创建出分析树。一旦 AST 被创建出来,在后续的处理过程中,比如语义分析阶段,会添加一些信息。可参考抽象语法树和具体语法树有什么区别?
5.11 补充
关于 node 类型,全集大致如下:
1 | (parameter) node: Identifier | SimpleLiteral | RegExpLiteral | Program | FunctionDeclaration | FunctionExpression | ArrowFunctionExpression | SwitchCase | CatchClause | VariableDeclarator | ExpressionStatement | BlockStatement | EmptyStatement | DebuggerStatement | WithStatement | ReturnStatement | LabeledStatement | BreakStatement | ContinueStatement | IfStatement | SwitchStatement | ThrowStatement | TryStatement | WhileStatement | DoWhileStatement | ForStatement | ForInStatement | ForOfStatement | VariableDeclaration | ClassDeclaration | ThisExpression | ArrayExpression | ObjectExpression | YieldExpression | UnaryExpression | UpdateExpression | BinaryExpression | AssignmentExpression | LogicalExpression | MemberExpression | ConditionalExpression | SimpleCallExpression | NewExpression | SequenceExpression | TemplateLiteral | TaggedTemplateExpression | ClassExpression | MetaProperty | AwaitExpression | Property | AssignmentProperty | Super | TemplateElement | SpreadElement | ObjectPattern | ArrayPattern | RestElement | AssignmentPattern | ClassBody | MethodDefinition | ImportDeclaration | ExportNamedDeclaration | ExportDefaultDeclaration | ExportAllDeclaration | ImportSpecifier | ImportDefaultSpecifier | ImportNamespaceSpecifier | ExportSpecifier |
Babel 有文档对 AST 树的详细定义,可参考这里
5.12 配套源码地址
代码以存放到 GitHub,地址:https://github.com/fecym/ast-share
参考链接
- JavaScript 语法解析、AST、V8、JIT
- 详解 AST 抽象语法树
- AST 抽象语法树 ps: 这个里面有 class 转 Es5 构造函数的过程,有兴趣可以看一下
- 剖析 Babel——Babel 总览 | AlloyTeam
- @babel/types
6.webpack-流程
6.1 引言
目前,几乎所有业务的开发构建都会用到 webpack 。的确,作为模块加载和打包神器,只需配置几个文件,加载各种 loader 就可以享受无痛流程化开发。但对于 webpack 这样一个复杂度较高的插件集合,它的整体流程及思想对我们来说还是很透明的。那么接下来我会带你了解 webpack 这样一个构建黑盒,首先来谈谈它的流程。
6.2 准备工作
6.2.1 webstorm 中配置 webpack-webstorm-debugger-script
在开始了解之前,必须要能对 webpack 整个流程进行 debug ,配置过程比较简单。
先将 webpack-webstorm-debugger-script 中的 webstorm-debugger.js 置于webpack.config.js 的同一目录下,搭建好你的脚手架后就可以直接 Debug 这个 webstorm-debugger.js 文件了。
6.2.2 webpack.config.js 配置
估计大家对 webpack.config.js 的配置也尝试过不少次了,这里就大致对这个配置文件进行个分析。
1 | var path = require('path'); |
除此之外再大致介绍下 webpack 的一些核心概念:
- loader:能转换各类资源,并处理成对应模块的加载器。loader 间可以串行使用。
- chunk:code splitting 后的产物,也就是按需加载的分块,装载了不同的 module。
对于 module 和 chunk 的关系可以参照 webpack 官方的这张图:
- plugin:webpack 的插件实体,这里以 UglifyJsPlugin 为例。
1 | function UglifyJsPlugin(options) { |
在 webpack 中你经常可以看到 compilation.plugin(‘xxx’, callback) ,你可以把它当作是一个事件的绑定,这些事件在打包时由 webpack 来触发。
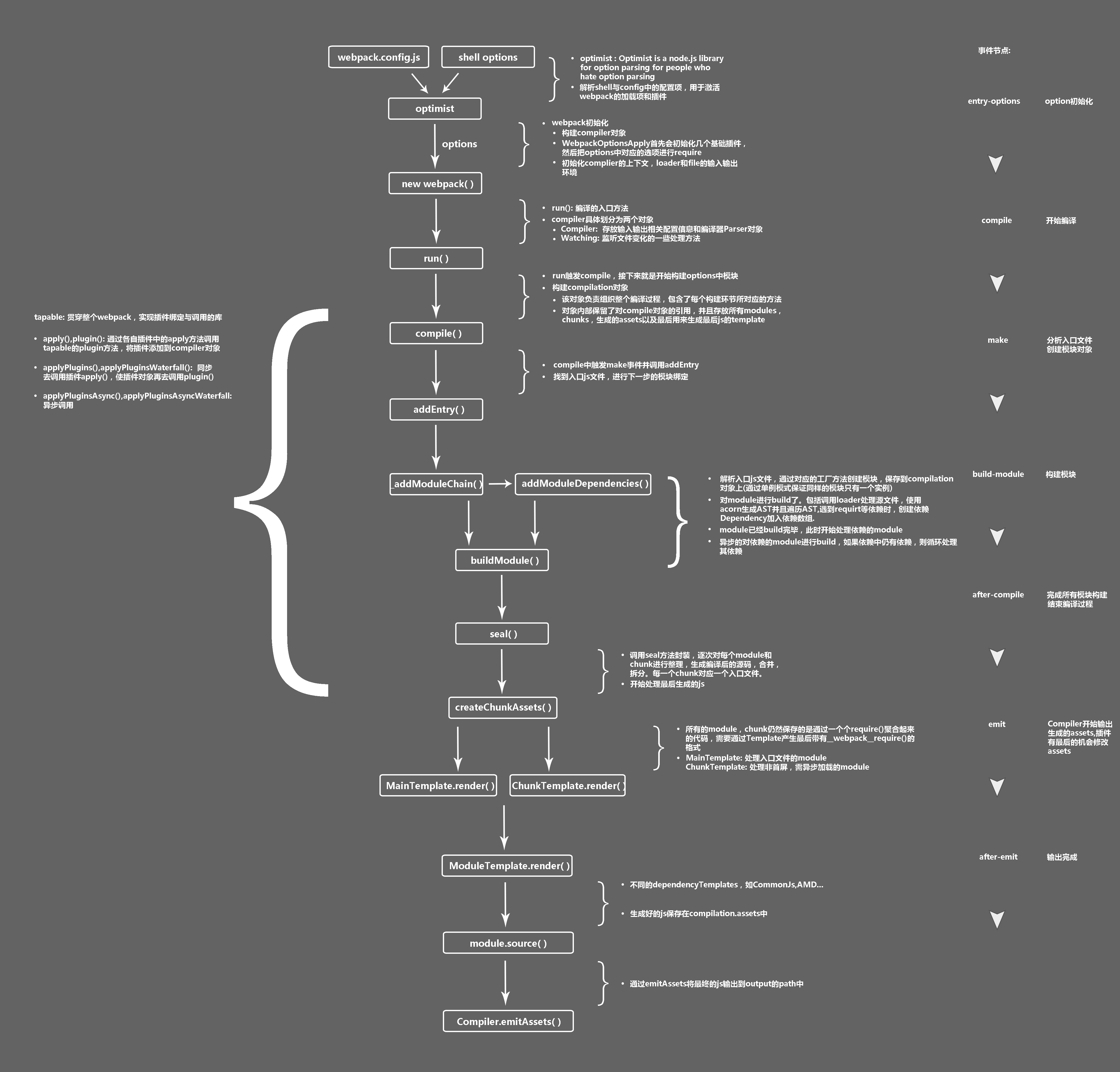
6.2.3 流程总览
在具体流程学习前,可以先通过这幅 webpack 整体流程图 了解一下大致流程(建议保存下来查看)。
6.3 shell 与 config 解析
每次在命令行输入 webpack 后,操作系统都会去调用 ./node_modules/.bin/webpack 这个 shell 脚本。这个脚本会去调用 ./node_modules/webpack/bin/webpack.js 并追加输入的参数,如 -p , -w 。(图中 webpack.js 是 webpack 的启动文件,而 $@ 是后缀参数)
在 webpack.js 这个文件中 webpack 通过 optimist 将用户配置的 webpack.config.js 和 shell 脚本传过来的参数整合成 options 对象传到了下一个流程的控制对象中。
6.3.1 optimist
和 commander 一样,optimist 实现了 node 命令行的解析,其 API 调用非常方便。
1 | var optimist = require("optimist"); |
获取到后缀参数后,optimist 分析参数并以键值对的形式把参数对象保存在 optimist.argv 中,来看看 argv 究竟有什么?
1 | // webpack --hot -w{ hot: true, profile: false, watch: true, ...} |
6.3.2 config 合并与插件加载
在加载插件之前,webpack 将 webpack.config.js 中的各个配置项拷贝到 options 对象中,并加载用户配置在 webpack.config.js 的 plugins 。接着 optimist.argv 会被传入到./node_modules/webpack/bin/convert-argv.js 中,通过判断 argv 中参数的值决定是否去加载对应插件。(至于 webpack 插件运行机制,在之后的运行机制篇会提到)
1 | ifBooleanArg("hot", function() { |
options 作为最后返回结果,包含了之后构建阶段所需的重要信息。
1 | { |
这和 webpack.config.js 的配置非常相似,只是多了一些经 shell 传入的插件对象。插件对象一初始化完毕, options 也就传入到了下个流程中。
1 | var webpack = require("../lib/webpack.js");var compiler = webpack(options); |
6.3.3 编译与构建流程
在加载配置文件和 shell 后缀参数申明的插件,并传入构建信息 options 对象后,开始整个 webpack 打包最漫长的一步。而这个时候,真正的 webpack 对象才刚被初始化,具体的初始化逻辑在 lib/webpack.js 中,如下:
1 | function webpack(options) { |
webpack 的实际入口是 Compiler 中的 run 方法,run 一旦执行后,就开始了编译和构建流程 ,其中有几个比较关键的 webpack 事件节点。
compile开始编译make从入口点分析模块及其依赖的模块,创建这些模块对象build-module构建模块after-compile完成构建seal封装构建结果emit把各个chunk输出到结果文件after-emit完成输出
1. 核心对象 Compilation
compiler.run 后首先会触发 compile ,这一步会构建出 Compilation 对象:

这个对象有两个作用,一是负责组织整个打包过程,包含了每个构建环节及输出环节所对应的方法,可以从图中看到比较关键的步骤,如 addEntry() , _addModuleChain() ,buildModule() , seal() , createChunkAssets() (在每一个节点都会触发 webpack 事件去调用各插件)。二是该对象内部存放着所有 module ,chunk,生成的 asset 以及用来生成最后打包文件的 template 的信息。
2. 编译与构建主流程
在创建 module 之前,Compiler 会触发 make,并调用 Compilation.addEntry 方法,通过 options 对象的 entry 字段找到我们的入口js文件。之后,在 addEntry 中调用私有方法_addModuleChain ,这个方法主要做了两件事情。一是根据模块的类型获取对应的模块工厂并创建模块,二是构建模块。
而构建模块作为最耗时的一步,又可细化为三步:
调用各 loader 处理模块之间的依赖
webpack 提供的一个很大的便利就是能将所有资源都整合成模块,不仅仅是 js 文件。所以需要一些 loader ,比如
url-loader,jsx-loader,css-loader等等来让我们可以直接在源文件中引用各类资源。webpack 调用doBuild(),对每一个 require() 用对应的 loader 进行加工,最后生成一个 js module。调用 acorn 解析经 loader 处理后的源文件生成抽象语法树 AST
1 | Parser.prototype.parse = function parse(source, initialState) { |
遍历 AST,构建该模块所依赖的模块
对于当前模块,或许存在着多个依赖模块。当前模块会开辟一个依赖模块的数组,在遍历 AST 时,将 require() 中的模块通过
addDependency()添加到数组中。当前模块构建完成后,webpack 调用processModuleDependencies开始递归处理依赖的 module,接着就会重复之前的构建步骤。
3. 构建细节
module 是 webpack 构建的核心实体,也是所有 module 的 父类,它有几种不同子类:NormalModule , MultiModule , ContextModule , DelegatedModule 等。但这些核心实体都是在构建中都会去调用对应方法,也就是 build() 。来看看其中具体做了什么:
1 | // 初始化module信息,如context,id,chunks,dependencies等。 |
对于每一个 module ,它都会有这样一个构建方法。当然,它还包括了从构建到输出的一系列的有关 module 生命周期的函数,我们通过 module 父类类图其子类类图(这里以 NormalModule 为例)来观察其真实形态:

可以看到无论是构建流程,处理依赖流程,包括后面的封装流程都是与 module 密切相关的。
6.4 打包输出
在所有模块及其依赖模块 build 完成后,webpack 会监听 seal 事件调用各插件对构建后的结果进行封装,要逐次对每个 module 和 chunk 进行整理,生成编译后的源码,合并,拆分,生成 hash 。 同时这是我们在开发时进行代码优化和功能添加的关键环节。
1 | Compilation.prototype.seal = function seal(callback) { |
1. 生成最终 assets
在封装过程中,webpack 会调用 Compilation 中的 createChunkAssets 方法进行打包后代码的生成。 createChunkAssets 流程如下:
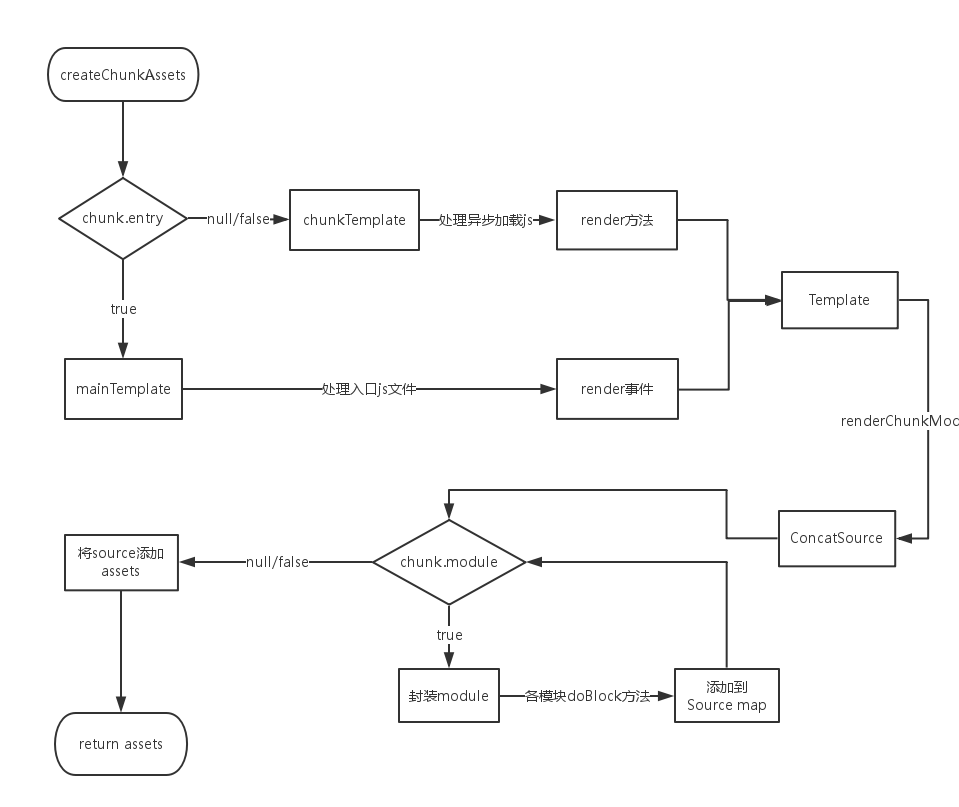
不同的 Template
从上图可以看出通过判断是入口 js 还是需要异步加载的 js 来选择不同的模板对象进行封装,入口 js 会采用 webpack 事件流的 render 事件来触发
Template类中的renderChunkModules()(异步加载的 js 会调用 chunkTemplate 中的 render 方法)。
1 | if(chunk.entry) { |
在 webpack 中有四个 Template 的子类,分别是 MainTemplate.js , ChunkTemplate.js,ModuleTemplate.js , HotUpdateChunkTemplate.js ,前两者先前已大致有介绍,而 ModuleTemplate 是对所有模块进行一个代码生成,HotUpdateChunkTemplate 是对热替换模块的一个处理。
模块封装
模块在封装的时候和它在构建时一样,都是调用各模块类中的方法。封装通过调用
module.source()来进行各操作,比如说 require() 的替换。
1 | MainTemplate.prototype.requireFn = "__webpack_require__"; |
生成 assets
各模块进行 doBlock 后,把 module 的最终代码循环添加到 source 中。一个 source 对应着一个 asset 对象,该对象保存了单个文件的文件名( name )和最终代码( value )。
2. 输出
最后一步,webpack 调用 Compiler 中的 emitAssets() ,按照 output 中的配置项将文件输出到了对应的 path 中,从而 webpack 整个打包过程结束。要注意的是,若想对结果进行处理,则需要在 emit 触发后对自定义插件进行扩展。
总结
webpack 的整体流程主要还是依赖于 compilation 和 module 这两个对象,但其思想远不止这么简单。最开始也说过,webpack 本质是个插件集合,并且由 tapable 控制各插件在 webpack 事件流上运行,至于具体的思想和细节,将会在后一篇文章中提到。同时,在业务开发中,无论是为了提升构建效率,或是减小打包文件大小,我们都可以通过编写 webpack 插件来进行流程上的控制,这个也会在之后提到。
7.webpack-插件
7.1 前言
webpack本身并不难,他所完成的各种复杂炫酷的功能都依赖于他的插件机制。或许我们在日常的开发需求中并不需要自己动手写一个插件,然而,了解其中的机制也是一种学习的方向,当插件出现问题时,我们也能够自己来定位。
7.2 Tapable
Webpack的插件机制依赖于一个核心的库, Tapable。
在深入webpack的插件机制之前,需要对该核心库有一定的了解。
7.2.1 Tapable是什么
tapable 是一个类似于nodejs 的EventEmitter 的库, 主要是控制钩子函数的发布与订阅。当然,tapable提供的hook机制比较全面,分为同步和异步两个大类(异步中又区分异步并行和异步串行),而根据事件执行的终止条件的不同,由衍生出 Bail/Waterfall/Loop 类型。
7.2.2 Tapable的使用 (该小段内容引用文章)
基本使用:
1 | const { |
钩子类型:
BasicHook:执行每一个,不关心函数的返回值,有SyncHook、AsyncParallelHook、AsyncSeriesHook。
BailHook:顺序执行 Hook,遇到第一个结果result!==undefined则返回,不再继续执行。有:SyncBailHook、AsyncSeriseBailHook, AsyncParallelBailHook。
什么样的场景下会使用到 BailHook 呢?设想如下一个例子:假设我们有一个模块 M,如果它满足 A 或者 B 或者 C 三者任何一个条件,就将其打包为一个单独的。这里的 A、B、C 不存在先后顺序,那么就可以使用 AsyncParallelBailHook 来解决:
1 | x.hooks.拆分模块的Hook.tap('A', () => { |
如果 A 中返回为 true,那么就无须再去判断 B 和 C。 但是当 A、B、C 的校验,需要严格遵循先后顺序时,就需要使用有顺序的 SyncBailHook(A、B、C 是同步函数时使用) 或者 AsyncSeriseBailHook(A、B、C 是异步函数时使用)。
WaterfallHook:类似于 reduce,如果前一个 Hook 函数的结果 result !== undefined,则 result 会作为后一个 Hook 函数的第一个参数。既然是顺序执行,那么就只有 Sync 和 AsyncSeries 类中提供这个Hook:SyncWaterfallHook,AsyncSeriesWaterfallHook 当一个数据,需要经过 A,B,C 三个阶段的处理得到最终结果,并且 A 中如果满足条件 a 就处理,否则不处理,B 和 C 同样,那么可以使用如下
1 | x.hooks.tap('A', (data) => { |
LoopHook:不停的循环执行 Hook,直到所有函数结果 result === undefined。同样的,由于对串行性有依赖,所以只有 SyncLoopHook 和 AsyncSeriseLoopHook (PS:暂时没看到具体使用 Case)
7.2.3 Tapable的源码分析
Tapable 基本逻辑是,先通过类实例的 tap 方法注册对应 Hook 的处理函数, 这里直接分析sync同步钩子的主要流程,其他的异步钩子和拦截器等就不赘述了。
1 | const hook = new SyncHook(['arg1', 'arg2']) |
从该句代码, 作为源码分析的入口,
1 | class SyncHook extends Hook { |
从类SyncHook看到, 他是继承于一个基类Hook, 他的核心实现compile等会再讲, 我们先看看基类Hook
1 | // 变量的初始化 |
初始化完成后, 通常会注册一个事件, 如:
1 | // 注册 |
很明显, 这两个语句都会调用基类中的tap方法:
1 | tap(options, fn) { |
从上面的源码分析, 可以看到_insert方法是注册阶段的关键函数, 直接进入该方法内部
1 | _insert(item) { |
_insert主要是排序tap并放入到taps数组里面, 排序的算法并不是特别复杂,这里就不赘述了, 到了这里, 注册阶段就已经结束了, 继续看触发阶段。
1 | hook.call(1, 2) // 触发函数 |
在基类hook中, 有一个初始化过程,
1 | this.call = this._call; |
我们可以看出_call是由createCompileDelegate生成的, 往下看
1 | function createCompileDelegate(name, type) { |
createCompileDelegate返回一个名为lazyCompileHook的函数,顾名思义,即懒编译, 直到调用call的时候, 才会编译出正在的call函数。
createCompileDelegate也是调用的_createCall, 而_createCall调用了Compier函数
1 | _createCall(type) { |
可以看到compiler必须由子类重写, 返回到syncHook的compile函数, 即我们一开始说的核心方法
1 | class SyncHookCodeFactory extends HookCodeFactory { |
关键就在于SyncHookCodeFactory和工厂类HookCodeFactory, 先看setup函数,
1 | setup(instance, options) { |
然后是最关键的create函数, 可以看到最后返回的fn,其实是一个new Function动态生成的函数
1 | create(options) { |
最后生成的代码大致如下, 参考文章
1 | "use strict"; |
ok, 以上就是Tapabled的机制, 然而本篇的主要对象其实是基于tapable实现的compile和compilation对象。不过由于他们都是基于tapable,所以介绍的篇幅相对短一点。
7.3 compile
7.3.1 compile是什么
compiler 对象代表了完整的 webpack 环境配置。这个对象在启动 webpack 时被一次性建立,并配置好所有可操作的设置,包括 options,loader 和 plugin。当在 webpack 环境中应用一个插件时,插件将收到此 compiler 对象的引用。可以使用 compiler 来访问 webpack 的主环境。
也就是说, compile是webpack的整体环境。
7.3.2 compile的内部实现
1 | class Compiler extends Tapable { |
可以看到, Compier继承了Tapable, 并且在实例上绑定了一个hook对象, 使得Compier的实例compier可以像这样使用
1 | compiler.hooks.compile.tapAsync( |
7.4 compilation
7.4.1 什么是compilation
compilation 对象代表了一次资源版本构建。当运行 webpack 开发环境中间件时,每当检测到一个文件变化,就会创建一个新的 compilation,从而生成一组新的编译资源。一个 compilation 对象表现了当前的模块资源、编译生成资源、变化的文件、以及被跟踪依赖的状态信息。compilation 对象也提供了很多关键时机的回调,以供插件做自定义处理时选择使用。
7.4.2 compilation的实现
1 | class Compilation extends Tapable { |
具体参考上面提到的compiler实现。
7.5 编写一个插件
了解到tapable\compiler\compilation之后, 再来看插件的实现就不再一头雾水了
以下代码源自官方文档
1 | class MyExampleWebpackPlugin { |
可以看到其实就是在apply中传入一个Compiler实例, 然后基于该实例注册事件, compilation同理, 最后webpack会在各流程执行call方法。
7.6 compiler和compilation一些比较重要的事件钩子
7.6.1 compier
| 事件钩子 | 触发时机 | 参数 | 类型 |
|---|---|---|---|
| entry-option | 初始化 option | - | SyncBailHook |
| run | 开始编译 | compiler | AsyncSeriesHook |
| compile | 真正开始的编译,在创建 compilation 对象之前 | compilation | SyncHook |
| compilation | 生成好了 compilation 对象,可以操作这个对象啦 | compilation | SyncHook |
| make | 从 entry 开始递归分析依赖,准备对每个模块进行 build | compilation | AsyncParallelHook |
| after-compile | 编译 build 过程结束 | compilation | AsyncSeriesHook |
| emit | 在将内存中 assets 内容写到磁盘文件夹之前 | compilation | AsyncSeriesHook |
| after-emit | 在将内存中 assets 内容写到磁盘文件夹之后 | compilation | AsyncSeriesHook |
| done | 完成所有的编译过程 | stats | AsyncSeriesHook |
| failed | 编译失败的时候 | error | SyncHook |
7.6.2 compilation
| 事件钩子 | 触发时机 | 参数 | 类型 |
|---|---|---|---|
| normal-module-loader | 普通模块 loader,真正(一个接一个地)加载模块图(graph)中所有模块的函数。 | loaderContext module | SyncHook |
| seal | 编译(compilation)停止接收新模块时触发。 | - | SyncHook |
| optimize | 优化阶段开始时触发。 | - | SyncHook |
| optimize-modules | 模块的优化 | modules | SyncBailHook |
| optimize-chunks | 优化 chunk | chunks | SyncBailHook |
| additional-assets | 为编译(compilation)创建附加资源(asset)。 | - | AsyncSeriesHook |
| optimize-chunk-assets | 优化所有 chunk 资源(asset)。 | chunks | AsyncSeriesHook |
| optimize-assets | 优化存储在 compilation.assets 中的所有资源(asset) | assets | AsyncSeriesHook |
总结
插件机制并不复杂,webpack也不复杂,复杂的是插件本身..
另外, 本应该先写流程的, 流程只能后面补上了。
引用
不满足于只会使用系列: tapable
webpack系列之二Tapable
编写一个插件
Compiler
Compilation
compiler和comnpilation钩子
看清楚真正的 Webpack 插件
8.webpack-loader
8.1 问题
以加载 less 为例。
1 | // example.js |
按照官方文档,想要加载 less 文件,我们需要配置三个 loader:style-loader!css-loader!less-loader。
该从什么地方着手研究呢? → 仔细观察最终生成的 output.js ,如下图所示。

由此我们进行以下思考:
既然最终 css 代码会被插入到 head 标签中,那么一定是模块2在起作用。但是,项目中并不包含这部分代码,经过排查,发现源自于 node-modules/style-loader/addStyle.js ,也就是说,是由 style-loader 引入的。(后面我们再考察是如何引入的)
观察模块3,那应该是 less 代码经过 less-loader 的转换之后,再包装一层 module.exports,成为一个 JS module。
style-loader 和 less-loader 的作用已经明了,但是,css-loader 发挥什么作用呢?虽然我一直按照官方文档配置三个 loader,但我从未真正理解为什么需要 css-loader。后来我在 css-loader 的文档中找到了答案。
@import and url() are interpreted like import and will be resolved by the css-loader.
来源:https://github.com/webpack-contrib/css-loader#options
既然如此,为了降低实现的难度,我们暂时不予考虑 import 和 url 的情况,也就无需实现 css-loader 了。
观察模块1,
require(2)(require(3)),很显然:”模块3的导出作为模块2的输入参数,执行模块2“,也就是说:“将模块3中的 css 代码插入到 head 标签中“。理解这个逻辑不难,难点在于:webpack 如何知道应该拼接成require(2)(require(3)),而不是别的什么。也就说,如何控制拼接出require(2)(require(3))?
8.2 思路
思路进行到这儿,似乎走不下去了。看来只分析 output.js 还不足以理清,那么,让我们更进一步,观察 depTree,如下图所示。(图片较大,请点击放大查看)
问题在于:为什么凭空多出来2个模块?到底是哪里起了作用呢?→ 我在 style-loader 的源码中找到了答案。
8.3 style-loader 的再 require
1 | // style-loader/index.js |
观察源码,我们发现:style-loader 返回的字符串里面又包含了2个 require,分别 require 了 addStyle 和 less-loader!style.less,由此,我们终于找到了突破口。→ loader 本质上是一个函数,输入参数是一个字符串,输出参数也是一个字符串。当然,输出的参数会被当成是 JS 代码,从而被 esprima 解析成 AST,触发进一步的依赖解析。 这就是多引入2个模块的原因。
8.4 loaders 的拆解与运行
loaders 就像首尾相接的管道那样,从右到左地被依次运行。对应的代码如下:
1 | // buildDep.js |
请注意:loader 也是分为同步和异步两种的,比如 style-loader 是同步的(看源码就知道,直接 return);而 less-loader 却是异步的,为什么呢?
8.5 异步的 less-loader
1 | // less-loader |
由代码我们可以看出:less-loader 本质上只是调用了 less 本身的 render 方法,由于 less.render 是异步的,less-loader 肯定也得异步,所以需要通过回调函数来获取其解析之后的 css 代码。
8.6 node-modules 的逐级查找
还差最后一点,我们就能完成 loader 机制了。
试想以下情景:webpack 检测到当前为 less 文件,需要找到 style-loader 和 less-loader 运行。但是,webpack 怎么知道这两个 loader 藏在哪个目录下面呢?他们可能藏在 example.js 所在目录的任意上层文件夹的 node-modules 中。 说到底,我们还是得实现之前提到过的 node-modules 的逐级查找功能。 核心代码如下:
1 | // resolve.js |
举个例子,对于 style-loader 来说,生成的查找路径集合如下:
1 | [ |
程序按照这个顺序依次查找,直到找到为止或者最终找不到抛出错误。
后话
至此,我们就完成了一个非常简单的 loader 机制,可以通过 style-loader 和 less-loader 处理加载 less 文件。当然,还有很多可以完善的地方,比如:
- 实现 css-loader,以处理 import 和 url 的情况
- 给 loader 传递选项参数,以控制是否压缩代码等等特性
- ……
9.微前端(前端微服务)
前言
想跳过技术细节直接看怎么实践的同学可以直接看最后一节。
目前社区有很多关于微前端架构的介绍,但大多停留在概念介绍的阶段。而本文会就某一个具体的类型场景,着重介绍微前端架构可以带来什么价值以及具体实践过程中需要关注的技术决策,并辅以具体代码,从而能真正意义上帮助你构建一个生产可用的微前端架构系统。
两个月前 Twitter 曾爆发过关于微前端的“热烈”讨论,参与大佬众多(Dan、Larkin 等),对“事件”本身我们今天不做过多评论(后面可能会写篇文章来回顾一下),有兴趣的同学可以通过这篇文章(https://zendev.com/2019/06/17/microfrontends-good-bad-ugly.html)了解一二。
9.1 微前端的价值
微前端架构具备以下几个核心价值:
技术栈无关:主框架不限制接入应用的技术栈,子应用具备完全自主权
独立开发、独立部署:子应用仓库独立,前后端可独立开发,部署完成后主框架自动完成同步更新
独立运行时:每个子应用之间状态隔离,运行时状态不共享
微前端架构旨在解决单体应用在一个相对长的时间跨度下,由于参与的人员、团队的增多、变迁,从一个普通应用演变成一个巨石应用( Frontend Monolith )后,随之而来的应用不可维护的问题。这类问题在企业级 Web 应用中尤其常见。
9.2 针对中后台应用的解决方案
中后台应用由于其应用生命周期长(动辄 3+ 年)等特点,最后演变成一个巨石应用的概率往往高于其他类型的 web 应用。而从技术实现角度,微前端架构解决方案大概分为两类场景:
单实例:即同一时刻,只有一个子应用被展示,子应用具备一个完整的应用生命周期。通常基于 url 的变化来做子应用的切换。
多实例:同一时刻可展示多个子应用。通常使用 Web Components 方案来做子应用封装,子应用更像是一个业务组件而不是应用。
本文将着重介绍单实例场景下的微前端架构实践方案(基于 single-spa),因为这个场景更贴近大部分中后台应用。
9.3 行业现状
传统的云控制台应用,几乎都会面临业务快速发展之后,单体应用进化成巨石应用的问题。为了解决产品研发之间各种耦合的问题,大部分企业也都会有自己的解决方案。笔者于17年底,针对国内外几个著名的云产品控制台,做过这样一个技术调研:
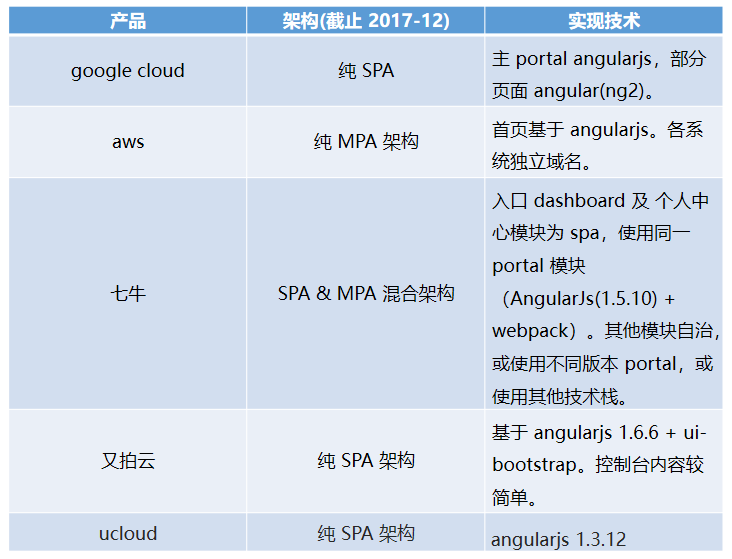
MPA 方案的优点在于 部署简单、各应用之间硬隔离,天生具备技术栈无关、独立开发、独立部署的特性。缺点则也很明显,应用之间切换会造成浏览器重刷,由于产品域名之间相互跳转,流程体验上会存在断点。
SPA 则天生具备体验上的优势,应用直接无刷新切换,能极大的保证多产品之间流程操作串联时的流程性。缺点则在于各应用技术栈之间是强耦合的。
那我们有没有可能将 MPA 和SPA 两者的优势结合起来,构建出一个相对完善的微前端架构方案呢?
jsconf china 2016 大会上,ucloud 的同学分享了他们的基于 angularjs 的方案(单页应用“联邦制”实践),里面提到的 “联邦制” 概念很贴切,可以认为是早期的基于耦合技术栈的微前端架构实践。
9.4 微前端架构实践中的问题
可以发现,微前端架构的优势,正是 MPA 与 SPA 架构优势的合集。即保证应用具备独立开发权的同时,又有将它们整合到一起保证产品完整的流程体验的能力。
这样一套模式下,应用的架构就会变成:
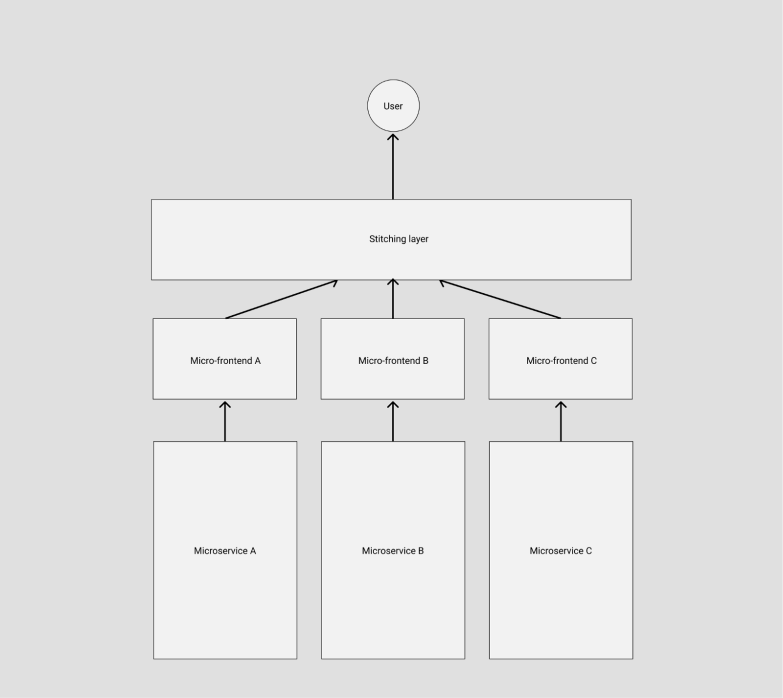
Stitching layer 作为主框架的核心成员,充当调度者的角色,由它来决定在不同的条件下激活不同的子应用。因此主框架的定位则仅仅是:导航路由 + 资源加载框架。
而具体要实现这样一套架构,我们需要解决以下几个技术问题:
路由系统及 FutureStat
我们在一个实现了微前端内核的产品中,正常访问一个子应用的页面时,可能会有这样一个链路:

由于我们的子应用都是 lazy load 的,当浏览器重新刷新时,主框架的资源会被重新加载,同时异步 load 子应用的静态资源,由于此时主应用的路由系统已经激活,但子应用的资源可能还没有完全加载完毕,从而导致路由注册表里发现没有能匹配子应用 /subApp/123/detail 的规则,这时候就会导致跳 NotFound 页或者直接路由报错。
这个问题在所有 lazy load 方式加载子应用的方案中都会碰到,早些年前 angularjs 社区把这个问题统一称之为 Future State。
解决的思路也很简单,我们需要设计这样一套路由机制:
主框架配置子应用的路由为subApp: { url: ‘/subApp/**’, entry:’./subApp.js’ },则当浏览器的地址为 /subApp/abc 时,框架需要先加载 entry 资源,待 entry 资源加载完毕,确保子应用的路由系统注册进主框架之后后,再去由子应用的路由系统接管 url change 事件。同时在子应用路由切出时,主框架需要触发相应的destroy 事件,子应用在监听到该事件时,调用自己的卸载方法卸载应用,如 React 场景下 destroy = () => ReactDOM.unmountAtNode(container) 。
要实现这样一套机制,我们可以自己去劫持 url change 事件从而实现自己的路由系统,也可以基于社区已有的 ui router library,尤其是 react-router 在 v4 之后实现了 Dynamic Routing 能力,我们只需要复写一部分路由发现的逻辑即可。这里我们推荐直接选择社区比较完善的相关实践single-spa。
App Entry
解决了路由问题后,主框架与子应用集成的方式,也会成为一个需要重点关注的技术决策。
1. 构建时组合 VS 运行时组合
微前端架构模式下,子应用打包的方式,基本分为两种:
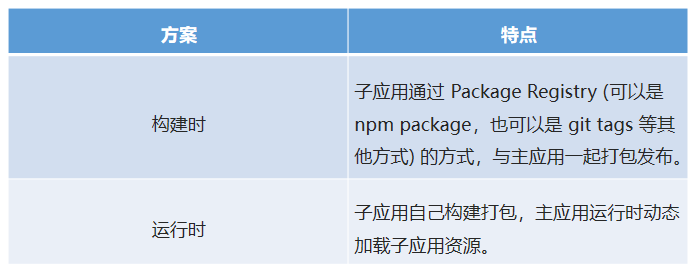
两者的优缺点也很明显:
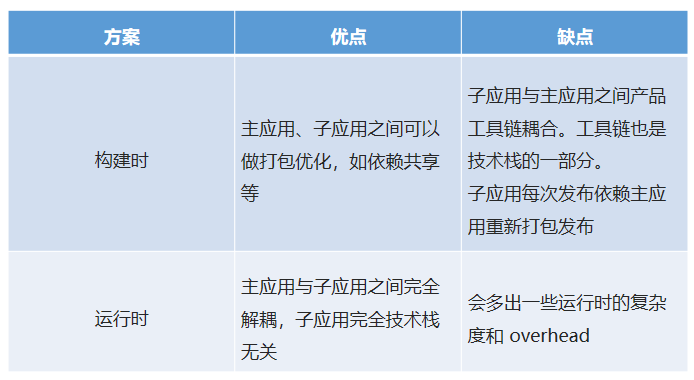
很显然,要实现真正的技术栈无关跟独立部署两个核心目标,大部分场景下我们需要使用运行时加载子应用这种方案。
2. JS Entry vs HTMLEntry
在确定了运行时载入的方案后,另一个需要决策的点是,我们需要子应用提供什么形式的资源作为渲染入口?
JS Entry 的方式通常是子应用将资源打成一个entry script,比如 single-spa 的 example 中的方式。但这个方案的限制也颇多,如要求子应用的所有资源打包到一个 js bundle 里,包括 css、图片等资源。除了打出来的包可能体积庞大之外的问题之外,资源的并行加载等特性也无法利用上。
HTML Entry 则更加灵活,直接将子应用打出来 HTML作为入口,主框架可以通过 fetch html 的方式获取子应用的静态资源,同时将 HTML document 作为子节点塞到主框架的容器中。这样不仅可以极大的减少主应用的接入成本,子应用的开发方式及打包方式基本上也不需要调整,而且可以天然的解决子应用之间样式隔离的问题(后面提到)。想象一下这样一个场景:

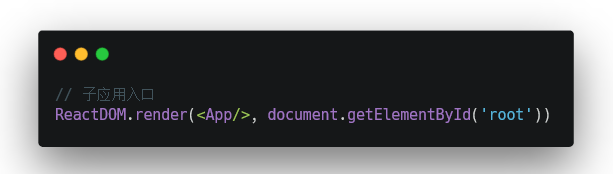
如果是 JS Entry 方案,主框架需要在子应用加载之前构建好相应的容器节点(比如这里的 “#root” 节点),不然子应用加载时会因为找不到 container 报错。但问题在于,主应用并不能保证子应用使用的容器节点为某一特定标记元素。而 HTML Entry 的方案则天然能解决这一问题,保留子应用完整的环境上下文,从而确保子应用有良好的开发体验。
HTML Entry 方案下,主框架注册子应用的方式则变成:

本质上这里 HTML 充当的是应用静态资源表的角色,在某些场景下,我们也可以将 HTML Entry 的方案优化成 Config Entry,从而减少一次请求,如:

总结一下:

3. 模块导入
微前端架构下,我们需要获取到子应用暴露出的一些钩子引用,如 bootstrap、mount、unmout 等(参考 single-spa),从而能对接入应用有一个完整的生命周期控制。而由于子应用通常又有集成部署、独立部署两种模式同时支持的需求,使得我们只能选择 umd 这种兼容性的模块格式打包我们的子应用。如何在浏览器运行时获取远程脚本中导出的模块引用也是一个需要解决的问题。
通常我们第一反应的解法,也是最简单的解法就是与子应用与主框架之间约定好一个全局变量,把导出的钩子引用挂载到这个全局变量上,然后主应用从这里面取生命周期函数。
这个方案很好用,但是最大的问题是,主应用与子应用之间存在一种强约定的打包协议。那我们是否能找出一种松耦合的解决方案呢?
很简单,我们只需要走 umd 包格式中的 global export 方式获取子应用的导出即可,大体的思路是通过给 window变量打标记,记住每次最后添加的全局变量,这个变量一般就是应用 export 后挂载到 global 上的变量。实现方式可以参考 systemjs global import,这里不再赘述。
应用隔离
微前端架构方案中有两个非常关键的问题,有没有解决这两个问题将直接标志你的方案是否真的生产可用。比较遗憾的是此前社区在这个问题上的处理都会不约而同选择”绕道“的方式,比如通过主子应用之间的一些默认约定去规避冲突。而今天我们会尝试从纯技术角度,更智能的解决应用之间可能冲突的问题。
1. 样式隔离
由于微前端场景下,不同技术栈的子应用会被集成到同一个运行时中,所以我们必须在框架层确保各个子应用之间不会出现样式互相干扰的问题。
Shadow DOM?
针对 “Isolated Styles” 这个问题,如果不考虑浏览器兼容性,通常第一个浮现到我们脑海里的方案会是 Web Components。基于 Web Components 的 Shadow DOM 能力,我们可以将每个子应用包裹到一个 Shadow DOM 中,保证其运行时的样式的绝对隔离。
但 Shadow DOM 方案在工程实践中会碰到一个常见问题,比如我们这样去构建了一个在 Shadow DOM 里渲染的子应用:

由于子应用的样式作用域仅在 shadow 元素下,那么一旦子应用中出现运行时越界跑到外面构建 DOM 的场景,必定会导致构建出来的 DOM 无法应用子应用的样式的情况。
比如 sub-app 里调用了antd modal 组件,由于 modal 是动态挂载到document.body 的,而由于 Shadow DOM 的特性 antd 的样式只会在 shadow 这个作用域下生效,结果就是弹出框无法应用到 antd 的样式。解决的办法是把 antd 样式上浮一层,丢到主文档里,但这么做意味着子应用的样式直接泄露到主文档了。gg…
CSS Module? BEM?
社区通常的实践是通过约定 css 前缀的方式来避免样式冲突,即各个子应用使用特定的前缀来命名 class,或者直接基于 css module 方案写样式。对于一个全新的项目,这样当然是可行,但是通常微前端架构更多的目标是解决存量/遗产 应用的接入问题。很显然遗产应用通常是很难有动力做大幅改造的。
最主要的是,约定的方式有一个无法解决的问题,假如子应用中使用了三方的组件库,三方库在写入了大量的全局样式的同时又不支持定制化前缀?比如 a 应用引入了 antd 2.x,而b 应用引入了 antd 3.x,两个版本的 antd 都写入了全局的 .menu class ,但又彼此不兼容怎么办?
Dynamic Stylesheet !
解决方案其实很简单,我们只需要在应用切出/卸载后,同时卸载掉其样式表即可,原理是浏览器会对所有的样式表的插入、移除做整个 CSSOM 的重构,从而达到 插入、卸载 样式的目的。这样即能保证,在一个时间点里,只有一个应用的样式表是生效的。
上文提到的 HTML Entry 方案则天生具备样式隔离的特性,因为应用卸载后会直接移除去 HTML 结构,从而自动移除了其样式表。
比如 HTML Entry 模式下,子应用加载完成的后的 DOM 结构可能长这样:
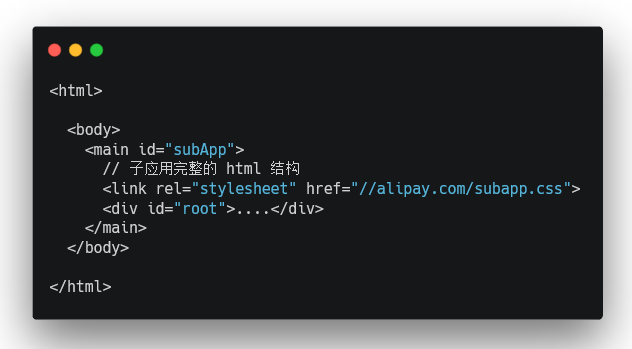
当子应用被替换或卸载时,subApp节点的innerHTML 也会被复写,//alipay.com/subapp.css 也就自然被移除样式也随之卸载了。
2. JS 隔离
解决了样式隔离的问题后,有一个更关键的问题我们还没有解决:如何确保各个子应用之间的全局变量不会互相干扰,从而保证每个子应用之间的软隔离?
这个问题比样式隔离的问题更棘手,社区的普遍玩法是给一些全局副作用加各种前缀从而避免冲突。但其实我们都明白,这种通过团队间的“口头”约定的方式往往低效且易碎,所有依赖人为约束的方案都很难避免由于人的疏忽导致的线上 bug。那么我们是否有可能打造出一个好用的且完全无约束的 JS 隔离方案呢?
针对 JS 隔离的问题,我们独创了一个运行时的 JS 沙箱。简单画了个架构图:
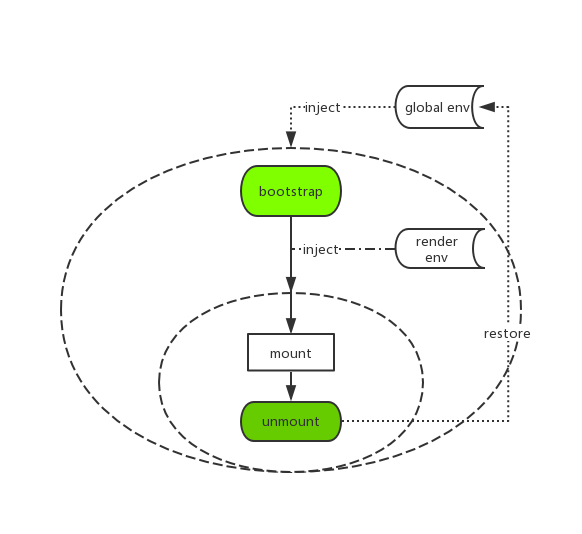
即在应用的 bootstrap 及 mount 两个生命周期开始之前分别给全局状态打下快照,然后当应用切出/卸载时,将状态回滚至 bootstrap 开始之前的阶段,确保应用对全局状态的污染全部清零。而当应用二次进入时则再恢复至 mount 前的状态的,从而确保应用在 remount 时拥有跟第一次 mount 时一致的全局上下文。
当然沙箱里做的事情还远不止这些,其他的还包括一些对全局事件监听的劫持等,以确保应用在切出之后,对全局事件的监听能得到完整的卸载,同时也会在 remount 时重新监听这些全局事件,从而模拟出与应用独立运行时一致的沙箱环境。
9.5 蚂蚁金服微前端落地实践
自去年年底伊始,我们便尝试基于微前端架构模式,构建出一套全链路的面向中后台场景的产品接入平台,目的是解决不同产品之间集成困难、流程割裂的问题,希望接入平台后的应用,不论使用哪种技术栈,在运行时都可以通过自定义配置,实现不同应用之间页面级别的自由组合,从而生成一个千人千面的个性化控制台。
目前这套平台已在蚂蚁生产环境运行半年多,同时接入了多个产品线的 40+ 应用、4+ 不同类型的技术栈。过程中针对大量微前端实践中的问题,我们总结出了一套完整的解决方案:
在内部得到充分的技术验证和线上考验之后,我们决定将这套解决方案开源出来!
qiankun - 一套完整的微前端解决方案
https://github.com/umijs/qiankun
取名 qiankun,意为统一。我们希望通过 qiankun 这种技术手段,让你能很方便的将一个巨石应用改造成一个基于微前端架构的系统,并且不再需要去关注各种过程中的技术细节,做到真正的开箱即用和生产可用。
对于umi用户我们也提供了配套的qiankun插件,以便于 umi 应用能几乎零成本的接入 qiankun:
@umijs/plugin-qiankun
https://github.com/umijs/umi-plugin-qiankun/
最后欢迎大家点赞使用提出宝贵的意见。
Maybe the most complete micro-frontends solution youever met.
可能是你见过的最完善的微前端架构解决方案。
10.Nodejs模块机制
我们都知道Nodejs遵循的是CommonJS规范,当我们require('moduleA')时,模块是怎么通过名字或者路径获取到模块的呢?首先要聊一下模块引用、模块定义、模块标识三个概念。
10.1 CommonJS规范
10.1.1 模块引用
模块上下文提供require()方法来引入外部模块,看似简单的require函数, 其实内部做了大量工作。示例代码如下:
1 | // test.js |
10.1.2 模块定义
模块上下文提供了exports对象用于导入导出当前模块的方法或者变量,并且它是唯一的导出出口。模块中存在一个module对象,它代表模块自身,exports是module的属性。一个文件就是一个模块,将方法作为属性挂载在exports上就可以定义导出的方式:
1 | //math.js |
这样就可像test.js里那样在require()之后调用模块的属性或者方法了。
10.1.3 模块标识
模块标识就是传递给require()方法的参数,它必须是符合小驼峰命名的字符串,或者以.、..开头的相对路径或者绝对路径,可以没有文件后缀名.js.
10.2 Node的模块实现
在Node中引入模块,需要经历如下四个步骤:
- 路径分析
- 文件定位
- 编译执行
- 加入内存
10.2.1 路径分析
Node.js中模块可以通过文件路径或名字获取模块的引用。模块的引用会映射到一个js文件路径。 在Node中模块分为两类:
- 一是Node提供的模块,称为核心模块(内置模块),内置模块公开了一些常用的API给开发者,并且它们在Node进程开始的时候就预加载了。
- 另一类是用户编写的模块,称为文件模块。如通过NPM安装的第三方模块(third-party modules)或本地模块(local modules),每个模块都会暴露一个公开的API。以便开发者可以导入。如
1 | const mod = require('module_name') |
执行后,Node内部会载入内置模块或通过NPM安装的模块。require函数会返回一个对象,该对象公开的API可能是函数、对象或者属性如函数、数组甚至任意类型的JS对象。
核心模块是Node源码在编译过程中编译进了二进制执行文件。在Node启动时这些模块就被加载进内存中,所以核心模块引入时省去了文件定位和编译执行两个步骤,并且在路径分析中优先判断,因此核心模块的加载速度是最快的。文件模块则是在运行时动态加载,速度比核心模块慢。
这里列下node模块的载入及缓存机制:
1、载入内置模块(A Core Module)
2、载入文件模块(A File Module)
3、载入文件目录模块(A Folder Module)
4、载入node_modules里的模块
5、自动缓存已载入模块
1、载入内置模块
Node的内置模块被编译为二进制形式,引用时直接使用名字而非文件路径。当第三方的模块和内置模块同名时,内置模块将覆盖第三方同名模块。因此命名时需要注意不要和内置模块同名。如获取一个http模块
1 | const http = require('http') |
返回的http即是实现了HTTP功能Node的内置模块。
2、载入文件模块
绝对路径的
1 | const myMod = require('/home/base/my_mod') |
或相对路径的
1 | const myMod = require('./my_mod') |
注意,这里忽略了扩展名.js,以下是对等的
1 | const myMod = require('./my_mod') |
3、载入文件目录模块
可以直接require一个目录,假设有一个目录名为folder,如
1 | const myMod = require('./folder') |
此时,Node将搜索整个folder目录,Node会假设folder为一个包并试图找到包定义文件package.json。如果folder目录里没有包含package.json文件,Node会假设默认主文件为index.js,即会加载index.js。如果index.js也不存在, 那么加载将失败。
4、载入node_modules里的模块
如果模块名不是路径,也不是内置模块,Node将试图去当前目录的node_modules文件夹里搜索。如果当前目录的node_modules里没有找到,Node会从父目录的node_modules里搜索,这样递归下去直到根目录。
5、自动缓存已载入模块
对于已加载的模块Node会缓存下来,而不必每次都重新搜索。下面是一个示例
1 | // modA.js |
命令行node init.js执行:
1 | 模块modA开始加载... |
可以看到虽然require了两次,但modA.js仍然只执行了一次。mod1和mod2是相同的,即两个引用都指向了同一个模块对象。
优先从缓存加载
和浏览器会缓存静态js文件一样,Node也会对引入的模块进行缓存,不同的是,浏览器仅仅缓存文件,而nodejs缓存的是编译和执行后的对象(缓存内存) require()对相同模块的二次加载一律采用缓存优先的方式,这是第一优先级的,核心模块缓存检查先于文件模块的缓存检查。
基于这点:我们可以编写一个模块,用来记录长期存在的变量。例如:我可以编写一个记录接口访问数的模块:
1 | let count = {}; // 因模块是封闭的,这里实际上借用了js闭包的概念 |
我们在路由的 action 或 controller里这样引用:
1 | let count = require('count'); |
以上便完成了对接口调用数的统计,但这只是个demo,因为数据存储在内存,服务器重启后便会清空。真正的计数器一定是要结合持久化存储器的。
在进入路径查找之前有必要描述一下module path这个Node.js中的概念。对于每一个被加载的文件模块,创建这个模块对象的时候,这个模块便会有一个paths属性,其值根据当前文件的路径 计算得到。我们创建modulepath.js这样一个文件,其内容为:
1 | // modulepath.js |
我们将其放到任意一个目录中执行node modulepath.js命令,将得到以下的输出结果。
1 | [ '/home/ikeepstudying/research/node_modules', |
10.2.2 文件定位
1.文件扩展名分析
调用require()方法时若参数没有文件扩展名,Node会按.js、.json、.node的顺寻补足扩展名,依次尝试。
在尝试过程中,需要调用fs模块阻塞式地判断文件是否存在。因为Node的执行是单线程的,这是一个会引起性能问题的地方。如果是.node或者·.json·文件可以加上扩展名加快一点速度。另一个诀窍是:同步配合缓存。
2.目录分析和包
require()分析文件扩展名后,可能没有查到对应文件,而是找到了一个目录,此时Node会将目录当作一个包来处理。
首先, Node在挡墙目录下查找package.json,通过JSON.parse()解析出包描述对象,从中取出main属性指定的文件名进行定位。若main属性指定文件名错误,或者没有pachage.json文件,Node会将index当作默认文件名。
简而言之,如果require绝对路径的文件,查找时不会去遍历每一个node_modules目录,其速度最快。其余流程如下:
1.从module path数组中取出第一个目录作为查找基准。
2.直接从目录中查找该文件,如果存在,则结束查找。如果不存在,则进行下一条查找。
3.尝试添加.js、.json、.node后缀后查找,如果存在文件,则结束查找。如果不存在,则进行下一条。
4.尝试将require的参数作为一个包来进行查找,读取目录下的package.json文件,取得main参数指定的文件。
5.尝试查找该文件,如果存在,则结束查找。如果不存在,则进行第3条查找。
6.如果继续失败,则取出module path数组中的下一个目录作为基准查找,循环第1至5个步骤。
7.如果继续失败,循环第1至6个步骤,直到module path中的最后一个值。
8.如果仍然失败,则抛出异常。
整个查找过程十分类似原型链的查找和作用域的查找。所幸Node.js对路径查找实现了缓存机制,否则由于每次判断路径都是同步阻塞式进行,会导致严重的性能消耗。
一旦加载成功就以模块的路径进行缓存
10.2.3 模块编译
每个模块文件模块都是一个对象,它的定义如下:
1 | function Module(id, parent) { |
对于不同扩展名,其载入方法也有所不同:
.js通过fs模块同步读取文件后编译执行。.node这是C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件.json同过fs模块同步读取文件后,用JSON.pares()解析返回结果
其他当作.js
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上。
json 文件的编译
1 | .json`文件调用的方法如下:其实就是调用`JSON.parse |
Module._extensions会被赋值给require()的extensions属性,所以可以用:console.log(require.extensions);输出系统中已有的扩展加载方式。 当然也可以自己增加一些特殊的加载:
1 | require.extensions['.txt'] = function(){ |
但是官方不鼓励通过这种方式自定义扩展名加载,而是期望先将其他语言或文件编译成JavaScript文件后再加载,这样的好处在于不讲烦琐的编译加载等过程引入Node的执行过程。
js模块的编译 在编译的过程中,Node对获取的javascript文件内容进行了头尾包装,将文件内容包装在一个function中:
1 | (function (exports, require, module, __filename, __dirname) { |
包装之后的代码会通过vm原生模块的runInThisContext()方法执行(具有明确上下文,不污染全局),返回一个具体的function对象,最后传参执行,执行后返回module.exports.
核心模块编译
核心模块分为C/C++编写和JavaScript编写的两个部分,其中C/C++文件放在Node项目的src目录下,JavaScript文件放在lib目录下。
1.转存为C/C++代码
Node采用了V8附带的js2c.py工具,将所有内置的JavaScript代码转换成C++里的数组,生成node_natives.h头文件:
1 | namespace node { |
在这个过程中,JavaScript代码以字符串形式存储在node命名空间中,是不可直接执行的。在启动Node进程时,js代码直接加载到内存中。在加载的过程中,js核心模块经历标识符分析后直接定位到内存中。
2.编译js核心模块
lib目录下的模块文件也在引入过程中经历了头尾包装的过程,然后才执行和导出了exports对象。与文件模块的区别在于:获取源代码的方式(核心模块从内存加载)和缓存执行结果的位置。
js核心模块源文件通过process.binding('natives')取出,编译成功的模块缓存到NativeModule._cache上。代码如下:
1 | function NativeModule() { |
10.3 import和require
简单的说一下import和require的本质区别
import是ES6的模块规范,require是commonjs的模块规范,详细的用法我不介绍,我只想说一下他们最基本的区别,import是静态加载模块,require是动态加载,那么静态加载和动态加载的区别是什么呢?
静态加载时代码在编译的时候已经执行了,动态加载是编译后在代码运行的时候再执行,那么具体点是什么呢? 先说说import,如下代码
1 | import { name } from 'name.js' |
上面的代码表示main.js文件里引入了name.js文件导出的变量,在代码编译阶段执行后的代码如下:
1 | let name = 'jinux' |
这个是我自己理解的,其实就是直接把name.js里的代码放到了main.js文件里,好比是在main.js文件中声明一样。 再来看看require
1 | var obj = require('obj.js'); |
require是在运行阶段,需要把obj对象整个加载进内存,之后用到哪个变量就用哪个,这里再对比一下import,import是静态加载,如果只引入了name,age是不会引入的,所以是按需引入,性能更好一点。
10.4 nodejs清除require缓存
开发nodejs应用时会面临一个麻烦的事情,就是修改了配置数据之后,必须重启服务器才能看到修改后的结果。
于是问题来了,挖掘机哪家强?噢,no! no! no!怎么做到修改文件之后,自动重启服务器。
server.js中的片段:
1 | const port = process.env.port || 1337; |
假定我们现在是这样的, app.js的片段:
1 | const app = require('./server.js'); |
如果我们在server.js中启动了服务器,我们停止服务器可以在app.js中调用
1 | app.app.close() |
但是当我们重新引入server.js
1 | app = require('./server.js') |
的时候会发现并不是用的最新的server.js文件,原因是require的缓存机制,在第一次调用require('./server.js')的时候缓存下来了。
这个时候怎么办?
下面的代码解决了这个问题:
1 | delete require.cache[require.resolve('./server.js')]; |
11.require原理
2009年,Node.js 项目诞生,所有模块一律为 CommonJS 格式。
时至今日,Node.js 的模块仓库 npmjs.com ,已经存放了15万个模块,其中绝大部分都是 CommonJS 格式。
这种格式的核心就是 require 语句,模块通过它加载。学习 Node.js ,必学如何使用 require 语句。本文通过源码分析,详细介绍 require 语句的内部运行机制,帮你理解 Node.js 的模块机制。
11.1 require() 的基本用法
分析源码之前,先介绍 require 语句的内部逻辑。如果你只想了解 require 的用法,只看这一段就够了。
下面的内容翻译自《Node使用手册》。
当 Node 遇到 require(X) 时,按下面的顺序处理。
(1)如果 X 是内置模块(比如 require(‘http’))
a. 返回该模块。
b. 不再继续执行。(2)如果 X 以 “./“ 或者 “/“ 或者 “../“ 开头
a. 根据 X 所在的父模块,确定 X 的绝对路径。
b. 将 X 当成文件,依次查找下面文件,只要其中有一个存在,就返回该文件,不再继续执行。
- X
- X.js
- X.json
- X.node
c. 将 X 当成目录,依次查找下面文件,只要其中有一个存在,就返回该文件,不再继续执行。
- X/package.json(main字段)
- X/index.js
- X/index.json
- X/index.node
(3)如果 X 不带路径
a. 根据 X 所在的父模块,确定 X 可能的安装目录。
b. 依次在每个目录中,将 X 当成文件名或目录名加载。(4) 抛出 “not found”
请看一个例子。
当前脚本文件 /home/ry/projects/foo.js 执行了 require(‘bar’) ,这属于上面的第三种情况。Node 内部运行过程如下。
首先,确定 x 的绝对路径可能是下面这些位置,依次搜索每一个目录。
2
3
4
/home/ry/node_modules/bar
/home/node_modules/bar
/node_modules/bar
搜索时,Node 先将 bar 当成文件名,依次尝试加载下面这些文件,只要有一个成功就返回。
2
3
4
bar.js
bar.json
bar.node
如果都不成功,说明 bar 可能是目录名,于是依次尝试加载下面这些文件。
2
3
4
bar/index.js
bar/index.json
bar/index.node
如果在所有目录中,都无法找到 bar 对应的文件或目录,就抛出一个错误。
11.2 Module 构造函数
了解内部逻辑以后,下面就来看源码。
require 的源码在 Node 的 lib/module.js 文件。为了便于理解,本文引用的源码是简化过的,并且删除了原作者的注释。
2
3
4
5
6
7
8
9
10
11
12
this.id = id;
this.exports = {};
this.parent = parent;
this.filename = null;
this.loaded = false;
this.children = [];
}
module.exports = Module;
var module = new Module(filename, parent);
上面代码中,Node 定义了一个构造函数 Module,所有的模块都是 Module 的实例。可以看到,当前模块(module.js)也是 Module 的一个实例。
每个实例都有自己的属性。下面通过一个例子,看看这些属性的值是什么。新建一个脚本文件 a.js 。
2
3
4
5
6
7
8
9
console.log('module.id: ', module.id);
console.log('module.exports: ', module.exports);
console.log('module.parent: ', module.parent);
console.log('module.filename: ', module.filename);
console.log('module.loaded: ', module.loaded);
console.log('module.children: ', module.children);
console.log('module.paths: ', module.paths);
运行这个脚本。
2
3
4
5
6
7
8
9
10
11
12
module.id: .
module.exports: {}
module.parent: null
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
可以看到,如果没有父模块,直接调用当前模块,parent 属性就是 null,id 属性就是一个点。filename 属性是模块的绝对路径,path 属性是一个数组,包含了模块可能的位置。另外,输出这些内容时,模块还没有全部加载,所以 loaded 属性为 false 。
新建另一个脚本文件 b.js,让其调用 a.js 。
2
3
var a = require('./a.js');
运行 b.js 。
2
3
4
5
6
7
8
9
10
11
12
module.id: /home/ruanyf/tmp/a.js
module.exports: {}
module.parent: { object }
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
上面代码中,由于 a.js 被 b.js 调用,所以 parent 属性指向 b.js 模块,id 属性和 filename 属性一致,都是模块的绝对路径。
11.3 模块实例的 require 方法
每个模块实例都有一个 require 方法。
2
3
return Module._load(path, this);
};
由此可知,require 并不是全局性命令,而是每个模块提供的一个内部方法,也就是说,只有在模块内部才能使用 require 命令(唯一的例外是 REPL 环境)。另外,require 其实内部调用 Module._load 方法。
下面来看 Module._load 的源码。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
// 第三步:生成模块实例,存入缓存
var module = new Module(filename, parent);
Module._cache[filename] = module;
// 第四步:加载模块
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};
上面代码中,首先解析出模块的绝对路径(filename),以它作为模块的识别符。然后,如果模块已经在缓存中,就从缓存取出;如果不在缓存中,就加载模块。
因此,Module._load 的关键步骤是两个。
- Module._resolveFilename() :确定模块的绝对路径
- module.load():加载模块
11.4 模块的绝对路径
下面是 Module._resolveFilename 方法的源码。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 第一步:如果是内置模块,不含路径返回
if (NativeModule.exists(request)) {
return request;
}
// 第二步:确定所有可能的路径
var resolvedModule = Module._resolveLookupPaths(request, parent);
var id = resolvedModule[0];
var paths = resolvedModule[1];
// 第三步:确定哪一个路径为真
var filename = Module._findPath(request, paths);
if (!filename) {
var err = new Error("Cannot find module '" + request + "'");
err.code = 'MODULE_NOT_FOUND';
throw err;
}
return filename;
};
上面代码中,在 Module.*resolveFilename 方法内部,又调用了两个方法 Module.*resolveLookupPaths() 和 Module._findPath() ,前者用来列出可能的路径,后者用来确认哪一个路径为真。
为了简洁起见,这里只给出 Module._resolveLookupPaths() 的运行结果。
2
3
4
5
6
7
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules'
'/home/ruanyf/.node_modules',
'/home/ruanyf/.node_libraries',
'$Prefix/lib/node' ]
上面的数组,就是模块所有可能的路径。基本上是,从当前路径开始一级级向上寻找 node_modules 子目录。最后那三个路径,主要是为了历史原因保持兼容,实际上已经很少用了。
有了可能的路径以后,下面就是 Module._findPath() 的源码,用来确定到底哪一个是正确路径。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
// 列出所有可能的后缀名:.js,.json, .node
var exts = Object.keys(Module._extensions);
// 如果是绝对路径,就不再搜索
if (request.charAt(0) === '/') {
paths = [''];
}
// 是否有后缀的目录斜杠
var trailingSlash = (request.slice(-1) === '/');
// 第一步:如果当前路径已在缓存中,就直接返回缓存
var cacheKey = JSON.stringify({request: request, paths: paths});
if (Module._pathCache[cacheKey]) {
return Module._pathCache[cacheKey];
}
// 第二步:依次遍历所有路径
for (var i = 0, PL = paths.length; i < PL; i++) {
var basePath = path.resolve(paths[i], request);
var filename;
if (!trailingSlash) {
// 第三步:是否存在该模块文件
filename = tryFile(basePath);
if (!filename && !trailingSlash) {
// 第四步:该模块文件加上后缀名,是否存在
filename = tryExtensions(basePath, exts);
}
}
// 第五步:目录中是否存在 package.json
if (!filename) {
filename = tryPackage(basePath, exts);
}
if (!filename) {
// 第六步:是否存在目录名 + index + 后缀名
filename = tryExtensions(path.resolve(basePath, 'index'), exts);
}
// 第七步:将找到的文件路径存入返回缓存,然后返回
if (filename) {
Module._pathCache[cacheKey] = filename;
return filename;
}
}
// 第八步:没有找到文件,返回false
return false;
};
经过上面代码,就可以找到模块的绝对路径了。
有时在项目代码中,需要调用模块的绝对路径,那么除了 module.filename ,Node 还提供一个 require.resolve 方法,供外部调用,用于从模块名取到绝对路径。
2
3
4
5
6
7
return Module._resolveFilename(request, self);
};
// 用法
require.resolve('a.js')
// 返回 /home/ruanyf/tmp/a.js
11.5 加载模块
有了模块的绝对路径,就可以加载该模块了。下面是 module.load 方法的源码。
2
3
4
5
6
var extension = path.extname(filename) || '.js';
if (!Module._extensions[extension]) extension = '.js';
Module._extensions[extension](this, filename);
this.loaded = true;
};
上面代码中,首先确定模块的后缀名,不同的后缀名对应不同的加载方法。下面是 .js 和 .json 后缀名对应的处理方法。
2
3
4
5
6
7
8
9
10
11
12
13
14
var content = fs.readFileSync(filename, 'utf8');
module._compile(stripBOM(content), filename);
};
Module._extensions['.json'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
这里只讨论 js 文件的加载。首先,将模块文件读取成字符串,然后剥离 utf8 编码特有的BOM文件头,最后编译该模块。
module._compile 方法用于模块的编译。
2
3
4
5
var self = this;
var args = [self.exports, require, self, filename, dirname];
return compiledWrapper.apply(self.exports, args);
};
上面的代码基本等同于下面的形式。
2
3
// 模块源码
});
也就是说,模块的加载实质上就是,注入exports、require、module三个全局变量,然后执行模块的源码,然后将模块的 exports 变量的值输出。
12.Node.js 事件循环
前言 Node 事件循环
翻译完了之后,才发现有官方翻译 ; 但是本文更加全面。本文是从官方文档和多篇文章整合而来。
看完本文之后,你会发现这里内容与《NodeJs 深入浅出》第三章第四节 3.4 非I/O异步API 中的内容不吻合。因为书上是有些内容是错误的。
还有一点的是,NodeJS 的事件循环与 Javascript 的略有不同。因此需要把两者区分开。
12.1 什么是事件循环 (What is the Event Loop)?
事件循环使 Node.js 可以通过将操作转移到系统内核中来执行非阻塞 I/O 操作(尽管 JavaScript 是单线程的)。
由于大多数现代内核都是多线程的,因此它们可以处理在后台执行的多个操作。 当这些操作之一完成时,内核会告诉 Node.js,以便可以将适当的回调添加到轮询队列中以最终执行。 我们将在本文的后面对此进行详细说明。
12.2 这就是事件循环 (Event Loop Explained)
Node.js 启动时,它将初始化事件循环,处理提供的输入脚本(或放入 REPL,本文档未涵盖),这些脚本可能会进行异步 API 调用,调度计时器或调用 process.nextTick, 然后开始处理事件循环。
下图显示了事件循环操作顺序的简化概述。
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
每个阶段都有一个要执行的回调 FIFO 队列。 尽管每个阶段都有其自己的特殊方式,但是通常,当事件循环进入给定阶段时,它将执行该阶段特定的任何操作,然后在该阶段的队列中执行回调,直到队列耗尽或执行回调的最大数量为止。 当队列已为空或达到回调限制时,事件循环将移至下一个阶段,依此类推。
由于这些操作中的任何一个都可能调度更多操作,并且在 poll阶段处理由内核排队的新事件 (比如 I/O 事件),因此可以在处理 poll 事件时将 poll 事件排队。 最终导致的结果是,长时间运行的回调可使 poll 阶段运行的时间比 timer 的阈值长得多。 有关更多详细信息,请参见计时器 (timer) 和轮询 (poll) 部分。
注意:Windows 和 Unix / Linux 实现之间存在细微差异,但这对于本演示并不重要。 最重要的部分在这里。 实际上有七个或八个阶段,但是我们关心的那些(Node.js 实际使用的那些)是上面的阶段。
12.3 各阶段概览 Phases Overview
- timers:此阶段执行由 setTimeout 和 setInterval 设置的回调。
- pending callbacks:执行推迟到下一个循环迭代的 I/O 回调。
- idle, prepare, :仅在内部使用。
- poll:取出新完成的 I/O 事件;执行与 I/O 相关的回调(除了关闭回调,计时器调度的回调和 setImmediate 之外,几乎所有这些回调) 适当时,node 将在此处阻塞。
- check:在这里调用 setImmediate 回调。
- close callbacks:一些关闭回调,例如 socket.on(‘close’, …)。
在每次事件循环运行之间,Node.js 会检查它是否正在等待任何异步 I/O 或 timers,如果没有,则将其干净地关闭。
12.4 各阶段详细解释 Phases in Detail
12.4.1 timers 计时器阶段
计时器可以在回调后面指定时间阈值,但这不是我们希望其执行的确切时间。 计时器回调将在经过指定的时间后尽早运行。 但是,操作系统调度或其他回调的运行可能会延迟它们。– 执行的实际时间不确定
注意:从技术上讲,轮询 (poll) 阶段控制计时器的执行时间。
例如,假设你计划在 100 毫秒后执行回调,然后脚本开始异步读取耗时 95 毫秒的文件:
1 | const fs = require('fs'); |
当事件循环进入 poll 阶段时,它有一个空队列(fs.readFile 尚未完成),因此它将等待直到达到最快的计时器 timer 阈值为止。 等待 95 ms 过去时,fs.readFile 完成读取文件,并将需要 10ms 完成的其回调添加到轮询 (poll) 队列并执行。 回调完成后,队列中不再有回调,此时事件循环已达到最早计时器 (timer) 的阈值 (100ms),然后返回到计时器 (timer) 阶段以执行计时器的回调。 在此示例中,您将看到计划的计时器与执行的回调之间的总延迟为 105ms。
Note: To prevent the poll phase from starving the event loop, libuv (the C library that implements the Node.js event loop and all of the asynchronous behaviors of the platform) also has a hard maximum (system dependent) before it stops polling for more events.
注意:为防止轮询 poll 阶段使事件循环陷入饥饿状态 (一直等待 poll 事件),libuv 还具有一个硬最大值限制来停止轮询。
12.4.2 pending callbacks 阶段
此阶段执行某些系统操作的回调,例如 TCP 错误。 举个例子,如果 TCP 套接字在尝试连接时收到 ECONNREFUSED,则某些 * nix 系统希望等待报告错误。 这将会在 pending callbacks 阶段排队执行。
12.4.3 轮询 poll 阶段
轮询阶段具有两个主要功能:
计算应该阻塞并 I/O 轮询的时间
处理轮询队列 (poll queue) 中的事件
当事件循环进入轮询 (poll) 阶段并且没有任何计时器调度 (timers scheduled) 时,将发生以下两种情况之一:如果轮询队列 (poll queue) 不为空,则事件循环将遍历其回调队列,使其同步执行,直到队列用尽或达到与系统相关的硬限制为止 (到底是哪些硬限制?)。
如果轮询队列为空,则会发生以下两种情况之一:
如果已通过 setImmediate 调度了脚本,则事件循环将结束轮询 poll 阶段,并继续执行 check 阶段以执行那些调度的脚本。
如果脚本并没有 setImmediate 设置回调,则事件循环将等待 poll 队列中的回调,然后立即执行它们。
一旦轮询队列 (poll queue) 为空,事件循环将检查哪些计时器 timer 已经到时间。 如果一个或多个计时器 timer 准备就绪,则事件循环将返回到计时器阶段,以执行这些计时器的回调。
12.4.4 检查阶段 check
此阶段允许在轮询 poll 阶段完成后立即执行回调。 如果轮询 poll 阶段处于空闲,并且脚本已使用 setImmediate 进入 check 队列,则事件循环可能会进入 check 阶段,而不是在 poll 阶段等待。
setImmediate 实际上是一个特殊的计时器,它在事件循环的单独阶段运行。 它使用 libuv API,该 API 计划在轮询阶段完成后执行回调。
通常,在执行代码时,事件循环最终将到达轮询 poll 阶段,在该阶段它将等待传入的连接,请求等。但是,如果已使用 setImmediate 设置回调并且轮询阶段变为空闲,则它将将结束并进入 check 阶段,而不是等待轮询事件。
12.4.5 close callbacks 阶段
如果套接字或句柄突然关闭(例如 socket.destroy),则在此阶段将发出 ‘close’ 事件。 否则它将通过 process.nextTick 发出。
12.5 setImmediate vs setTimeout
setImmediate 和 setTimeout 相似,但是根据调用时间的不同,它们的行为也不同。
- setImmediate 设计为在当前轮询 poll 阶段完成后执行脚本。
- setTimeout 计划在以毫秒为单位的最小阈值过去之后运行脚本。
计时器的执行顺序将根据调用它们的上下文而有所不同。 如果两者都是主模块 (main module) 中调用的,则时序将受到进程性能的限制(这可能会受到计算机上运行的其他应用程序的影响)。有点难懂,举个例子:
例如,如果我们运行以下不在 I/O 回调(即主模块)内的脚本,则两个计时器的执行顺序是不确定的,因为它受进程性能的约束:
1 | // timeout_vs_immediate.js |
但是,如果这两个调用在一个 I/O 回调中,那么 immediate 总是执行第一:
1 | // timeout_vs_immediate.js |
与 setTimeout 相比,使用 setImmediate 的主要优点是,如果在 I/O 周期内 setImmediate 总是比任何 timers 快。这个可以在下方彩色图中找到答案:poll 阶段用 setImmediate 设置下阶段 check 的回调,等到了 check 就开始执行;timers 阶段只能等到下次循环执行!
问题:那为什么在外部 (比如主代码部分 mainline) 这两者的执行顺序不确定呢?
解答:在 mainline 部分执行 setTimeout 设置定时器 (没有写入队列呦),与 setImmediate 写入 check 队列。mainline 执行完开始事件循环,第一阶段是 timers,这时候 timers 队列可能为空,也可能有回调;如果没有那么执行 check 队列的回调,下一轮循环在检查并执行 timers 队列的回调;如果有就先执行 timers 的回调,再执行 check 阶段的回调。因此这是 timers 的不确定性导致的。
举一反三:timers 阶段写入 check 队列
1 | setTimeout(() => { |
总是会输出:
1 | immediate |
1 | const ITERATIONS_MAX = 2; |
输出:
1 | TIME PHASE START:0 |
这表明,可以理解 setInterval 是 setTimeout 的嵌套调用的语法糖。setInterval(() => {}, 0) 是在每一次事件循环中添加回调到 timers 队列。因此不会阻止事件循环的继续运行,在浏览器上也不会感到卡顿。
12.6process.nextTick
12.6.1 理解 process.nextTick
你可能已经注意到 process.nextTick 并未显示在图中,即使它是异步 API 的一部分也是如此。 这是因为 process.nextTick 从技术上讲不是事件循环的一部分。 相反,无论事件循环的当前阶段如何,都将在当前操作完成之后处理 nextTickQueue。 在此,将操作定义为在 C/C ++ 处理程序基础下过渡并处理需要执行的 JavaScript。
回顾一下我们的图,在给定阶段里可以在任意时间调用 process.nextTick,传递给 process.nextTick 的所有回调都将在事件循环继续之前得到解决。 这可能会导致一些不良情况,因为它允许您通过进行递归 process.nextTick 调用来让 I/O 处于 “饥饿” 状态,从而防止事件循环进入轮询 poll 阶段。
注意:Microtask callbacks 微服务
12.6.2 为什么允许这样操作? Why would that be allowed?
为什么这样的东西会包含在 Node.js 中? 它的一部分是一种设计理念,即使不是必须的情况下,API 也应始终是异步的。
举个例子:
1 | function apiCall(arg, callback) { |
该代码段会进行参数检查,如果不正确,则会将错误传递给回调。 该 API 最近进行了更新,以允许将参数传递给 process.nextTick,从而可以将回调后传递的所有参数都传播为回调的参数,因此您不必嵌套函数。
我们正在做的是将错误传递回用户,但只有在我们允许其余用户的代码执行之后。 通过使用 process.nextTick,我们保证 apiCall 始终在用户的其余代码之后以及事件循环继续下阶段之前运行其回调。 为此,允许 JS 调用堆栈展开,然后立即执行所提供的回调,该回调可以对 process.nextTick 进行递归调用,而不会达到 RangeError:v8 超出最大调用堆栈大小。
这种理念可能会导致某些潜在的问题情况。 以下代码段为例:
1 | let bar; |
用户将 someAsyncApiCall 定义为具有异步签名,但实际上它是同步运行的。 调用它时,提供给 someAsyncApiCall 的回调在事件循环的同一阶段被调用,因为 someAsyncApiCall 实际上并不异步执行任何操作。 结果,即使脚本可能尚未在范围内,该回调也会尝试引用 bar,因为该脚本无法运行完毕。
通过将回调放置在 process.nextTick 中,脚本仍具有运行完成的能力,允许在调用回调之前初始化所有变量,函数等。 它还具有不允许事件循环继续下个阶段的优点。 在允许事件循环继续之前,向用户发出错误提示可能很有用。 这是使用 process.nextTick 的先前示例:
1 | let bar; |
这是另一个真实的例子:
1 | const server = net.createServer(() => {}).listen(8080); |
仅通过端口时,该端口将立即绑定。 因此,可以立即调用 “监听” 回调。 问题在于那时尚未设置.on(‘listening’) 回调。
为了解决这个问题,”listening” 事件在 nextTick() 中排队,以允许脚本运行完成。 这允许用户设置他们想要的任何事件处理程序。
12.6.3 process.nextTick vs setImmediate
他们的调用方式很相似,但是名称让人困惑。
- process.nextTick 在同一阶段立即触发
- setImmediate fires on the following iteration or ‘tick’ of the event loop (在事件循环接下来的阶段迭代中执行 - check 阶段)。
本质上,名称应互换。 process.nextTick 比 setImmediate 触发得更快,但由于历史原因,不太可能改变。 进行此切换将破坏 npm 上很大一部分软件包。 每天都会添加更多的新模块,这意味着我们每天都在等待,更多潜在的损坏发生。 尽管它们令人困惑,但名称本身不会改变。
我们建议开发人员在所有情况下都使用 setImmediate,因为这样更容易推理(并且代码与各种环境兼容,例如浏览器 JS。)- 但是如果理解底层原理,就不一样。
12.6.4 为什么还用 process.nextTick?
- 这里举出两个原因:
- 在事件循环继续之前下个阶段允许开发者处理错误,清理所有不必要的资源,或者重新尝试请求。
有时需要让回调在事件循环继续下个阶段之前运行 (At times it’s necessary to allow a callback to run after the call stack has unwound but before the event loop continues.)。
简单的例子:
1 | const server = net.createServer(); |
假设 listen 在事件循环的开始处运行,但是侦听回调被放置在 setImmediate 中 (实际上 listen 使用 process.nextTick,.on 在本阶段完成)。 除非传递主机名,否则将立即绑定到端口。 为了使事件循环继续进行,它必须进入轮询 poll 阶段,这意味着存在已经接收到连接可能性,从而导致在侦听事件之前触发连接事件 (漏掉一些 poll 事件)。
另一个示例正在运行一个要从 EventEmitter 继承的函数构造函数,它想在构造函数中调用一个事件:
1 | const EventEmitter = require('events'); |
你无法立即从构造函数中发出事件,因为脚本还没运行到开发者为该事件分配回调的那里 (指 myEmitter.on)。 因此,在构造函数本身内,你可以使用 process.nextTick 设置构造函数完成后发出事件的回调,从而提供预期的结果:
1 | const EventEmitter = require('events'); |
12.6.5 process.nextTick 在事件循环的位置:
来子一位外国小哥之手。链接在本文下面。
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ nextTickQueue
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ nextTickQueue
│ ┌─────────────┴─────────────┐
| | idle, prepare │
| └─────────────┬─────────────┘
nextTickQueue nextTickQueue
| ┌─────────────┴─────────────┐
| │ poll │
│ └─────────────┬─────────────┘
│ nextTickQueue
│ ┌─────────────┴─────────────┐
│ │ check │
│ └─────────────┬─────────────┘
│ nextTickQueue
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
下图补充了官方并没有提及的 Microtasks 微任务:

12.7 Microtasks 微任务
微任务会在主线之后和事件循环的每个阶段之后立即执行。
如果您熟悉 JavaScript 事件循环,那么应该对微任务不陌生,这些微任务在 Node 中的工作方式相同。 如果你想重新了解事件循环和微任务队列,请查看此链接(这东西非常底层,慎点)。
在 Node 领域,微任务是来自以下对象的回调:
- process.nextTick()
- then() handlers for resolved or rejected Promises
在主线结束后以及事件循环的每个阶段之后,立即运行微任务回调。
resolved 的 promise.then 回调像微处理一样执行,就像 process.nextTick 一样。 虽然,如果两者都在同一个微任务队列中,则将首先执行 process.nextTick 的回调。
优先级 process.nextTick > promise.then = queueMicrotask
下面例子完整演示了事件循环:
1 | const fs = require('fs'); |
输出:
1 | 1577168519233:INFO: MAINLINE: START |
运行结果的顺序不固定,因为 fs.readdir 需要 I/O 系统调用,需要等待系统的调度,因此等待事件并不固定。
但是顺序仍然是有规律的:
- 因为 setTimeout 和 setImmediate 在 timers 阶段 (不是 mainline 就行) 被调用,因此 setImmediate 总是比 setTimeout 快 (前面第 5 节已说明)
- 因为 poll 阶段等待系统调用的时间不确定。因此它会在上面两者之间插空,就是 3 种排序
poll check timers 这种可能比较少,取决于 I/O 调用速度与进程在当前 timers 阶段的处理时间 —— 也就是 I/O 的事件循环进入 poll 阶段前就已经完成,也就是 poll 队列不为空。把上面的 msleep 注释打开即可测试。
check poll timers 这种情况比较多出现。
check timers poll 这种情况也多。
因此存在 3 种顺序。
本文下方链接包含更多例子
timers 阶段和 poll 阶段,因为依赖系统的调度,所以具体在哪一次事件循环执行?这是不确定的,有可能是下次循环就可以,也许需要等待。在上面彩色图的事件循环中黄色标记的阶段中,只剩下 check 阶段是确定的 —— 必然是在本次 (还没到本次循环的 check 阶段的话) 或者下次循环调用。还有的是,微服务是能够保证,必然在本阶段结束后下阶段前执行。
timers 不确定,poll 不确定,check 确定,Microtasks 确定。
12.8题外话:Events
事件是应用程序中发生的重要事件。 诸如 Node 之类的事件驱动的运行时在某些地方发出事件,并在其他地方响应事件。
例子:
1 | // The Node EventEmitter |
输出:
1 | $ node example7 |
上面结果看出,Event 是同步,什么时候 emit 就什么时候执行回调。
13.cluster原理
13.1 概述
cluster模块是node.js中用于实现和管理多进程的模块。常规的node.js应用程序是单线程单进程的,这也意味着它很难充分利用服务器多核CPU的性能,而cluster模块就是为了解决这个 问题的,它使得node.js程序可以以多个实例并存的方式运行在不同的进程中,以求更大地榨取服务器的性能。node.js在官方示例代码中使用worker实例来表示主进程fork出的子进程,使得前端开发者在学习过程中非常容易和浏览器环境中的worker实现的多线程混淆。为了容易区分,我们和node官方文档使用一致的名称,用集群中的master和worker来区分主进程和工作进程,用worker_threads来描述工作线程。
node.js的主从模型中,master主进程相当于一个包工头,主管监听端口,而slave进程被用于实际的任务执行,当任务请求到达后,它会根据某种方式将连接循环分发给worker进程来处理。理论上,如果根据当前各个worker进程的负载状况或者相关信息来挑选工作进程,效率应该比直接循环发放要更高,但node.js文档中声明这种方式由于受到操作系统调度机制的影响,会使得分发变得不稳定,所以会将**”循环法”**作为默认的分发策略。
关于cluster模块的用法和API细节,可以直接参考官方文档《Node.js中文网V10.15.3/cluster》。
13.2 线程与进程
想要尽可能利用服务器性能,首先需要了解“线程”(thread)和“进程”(process)这两个概念。
计算机是由CPU来执行计算任务的,如果你只有一个CPU,那么这台机器上所有的任务都将由它来执行。它既可以按照串联执行的原则一个接一个执行任务,也可以依据并联原则同步执行多个任务,多个任务同步执行时,CPU会快速在多个线程之间进行切换,切换线程的同时要切换对应任务的上下文,这就会造成额外的CPU资源消耗,所以当线程数量非常多时,线程切换本身就会浪费大量的CPU资源。如果在执行一个任务的同时,CPU和内存都还有充足的剩余,就可以通过某种方式让它们去执行其他任务。
你可以将“线程”看作是一种轻量级的“进程”。
如果你在操作系统中打开任务管理器,在进程标签下就可以看到如下图的示例:
我们可以看到每一个程序至少开辟一个新的进程(你可能瞬间就明白了chrome效率高的原因,我什么都没说),它是一种粒度更大的资源隔离单元,进程之间使用不同的内存区域,无法直接共享数据,只能通过跨进程通讯机制来通讯,而且由于要使用新的内存区域,它的创建销毁和切换相对而言都更耗时,它的好处就是进程之间是互相隔离的,互不影响,所以你可以一边听音乐一边玩游戏,而不会因为音乐软件里突然放了一首轻音乐,结果你游戏里的角色攻击力减半了。
再来看一下性能这个标签:
可以看到线程数是远大于进程数的。“线程”通常用来在单个“进程”中提高CPU的利用率,它是一种粒度更细的资源调度单位,它更容易创建和销毁,在同一个进程内的线程共享分配给这个进程的内存,所以也就实现了共享数据,多线程的编程要更加复杂,由于共享数据,如果线程之间传递指针然后操作同一数据源,就必须考虑“原子操作”和“锁”的问题,否则很容易就乱套了,如果传递数据的拷贝,又会造成内存浪费,另外线程异常不会被隔离,而会导致整个进程异常。
线程和进程的相关知识涉及到底层操作系统的内容,笔者涉猎有限,先分享这么多(会的都告诉你了,还要我怎样)。
13.3 cluster模块源码解析
13.3.1 起步
cluster模块的用法看起来并不复杂,官方给出的示例是这样的:
1 | const cluster = require('cluster'); |
13.3.2 入口
cluster模块的入口在/lib/cluster.js,这里的代码很简单:
1 | ; |
可以看到,如果进程对象的环境变量中有NODE_UNIQUE_ID这个变量,就透传internal/cluster/child.js模块的输出,否则就透传internal/cluster/master.js模块的输出。这是node的主进程在进行子进程管理时的标识,后面的代码中可以看到当调用cluster.fork( )生成一个子进程时会以一个自增ID的形式生成这个环境变量。
13.3.3 主进程模块master.js
首先运行node程序的肯定是主线程,那么我们从master.js这个模块开始,先用工具折叠一下代码浏览一下:
可以看到除了模块属性外,cluster模块对外暴露的方法只有下面3个,其他的都是用来完成内部功能的:
setupMaster(options )-修改fork时默认设置fork( )-生成子进程disconnect( )- 断开和所有子进程的连接
我们按照官方示例的逻辑路线来阅读代码cluster.fork( )方法定义在161-217行,一样是用折叠工具来看全貌:
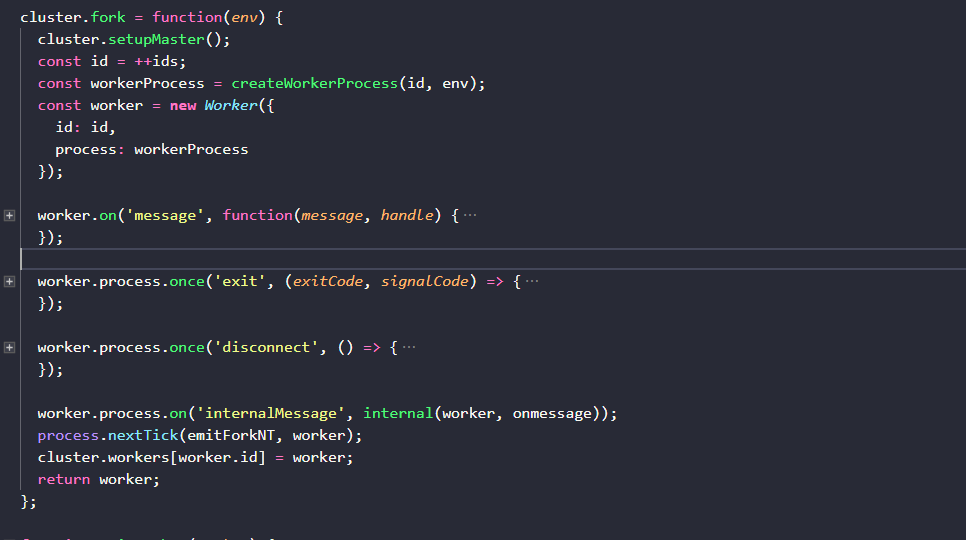
可以看到cluster.fork( )执行时做了如下几件事情:
1 | 1.设置主线程参数 |
接着看第一步setupMaster( ),在源码中50-95行,着重看81-95行:
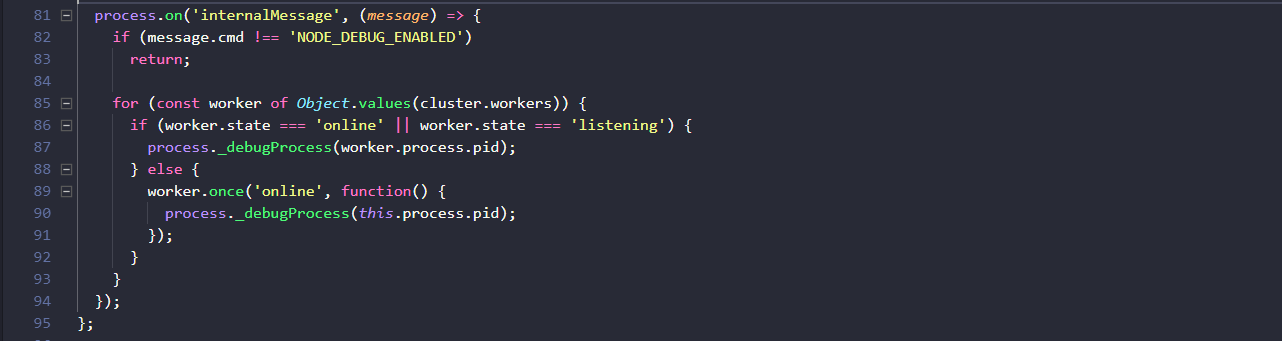
留意一下主线程在进程层面监听的internalMessage事件非常关键,主进程监听到这个事件后,首先判断消息对象的cmd属性是否为NODE_DEBUGE_ENABLED,并以此为条件判断后续语句是否执行,后续的逻辑是遍历每一个worker进程实例,如果子进程的状态是online或listening就将子进程pid作为参数调用主进程的_debugProcess( )方法,否则改为在worker进程实例首次上线时调用。
process._debugProcess的定义在src/node_process_methods.cc里,看名字推测大致的意思就是为了启用对子进程的调试功能。这是一个重载方法,在windows和linux下有不同的实现。linux下的代码较短,基本可以看懂(不秀一下怎么对得住自己看1周的C++):
1 |
|
win32平台中对应的代码比较长,看不懂。总结一下这里就是,在没有收到cmd属性等于NODE_DEBUG_ENABLED的内部消息之前,什么都不做,如果收到这个消息,就终止所有的子进程,或者通过事件在子进程第一次处于online状态就终止它。
按照执行顺序接下来是101-140行的createWorkerProcess(id,env)方法,看名字就知道是生成子进程process对象的,前半部分合并和处理环境参数,然后判断运行参数中是否包含启用--inspect功能的参数并进行一些处理,最后传入一堆参数调用了fork方法,这个方法就是child_process.fork( ),它就是用来生成子进程的,返回值就是子进程实例,你可以先简单浏览一下API【官方文档child_process.fork功能】,或者知道这里生成了子进程就好。
回到cluster.fork方法继续执行,下一步使用新生成的子进程process对象和唯一id作为参数传入Worker构造函数,生成worker实例,Worker的定义就在当前文件夹的worker.js中,它首先继承了EventEmitter的消息的发布订阅能力,然后把子进程的process对象挂在在自己的process属性上,接着为子进程添加error和 message事件的监听,最后暴露了一些更语义化的针对进程实例的管理方法(更详细的分析可以参考本系列前一篇博文)。生成了worker进程实例后,添加了对于message事件的响应,并在子进程process对象上监听进程的exit,disconnect,internalMessage事件,最后将worker实例和自己的id以键值对的形式添加到cluster.workers中记录,并通过return返回给外界,至此master模块的初始化流程就告一段落,先mark一下,后面还会讲这里。
13.3.4 子进程模块child.js
子进程模块是从master.js调用child_process时启动的,它和主进程是并行执行的。老规矩,代码折叠看一下:
看出什么了吗?child.js的代码里只有引用和定义,_setupWorker是在nodejs工作进程初始化时执行的,它在自己的独立进程中初始化了一个进程管理实例,并执行了下述逻辑:
1 | 1.实例化进程管理对象worker |
注意,这个process对象就是IPC(Inter Process Communication,也称为跨进程通讯)能够实现的关键,很明显它继承了EventEmitter的消息收发能力,在子进程内部进行消息收发不存在任何问题,还记得master.js中fork方法吗?这个process就是调用child_process启动子进程时返回给主进程的那个process对象,当你在主进程中获取它后,就可以共享worker进程的消息能力,从而在资源隔离的条件下实现master和worker进程的跨进程通讯。_getServer( )方法是在建立server实例时调用的,等到驱动事件信息到达child.js时再看,可以留意一下最后两个添加在Worker原型方法上的方法,它们只在子进程中有效。
13.4 小结
至此,你已经看到node是如何通过cluster模块实现多实例并初始化跨进程通讯了。但是跨进程通讯的底层实现以及服务器的建立,以及如何在进程间协调网络请求的处理,还依赖于net和http的一些内容,只好等研究完了再继续,硬刚反正我是吃不消的。
14.流机制
相信很多人对 Node 的 Stream 已经不陌生了,不论是请求流、响应流、文件流还是 socket 流,这些流的底层都是使用 stream 模块封装的,甚至我们平时用的最多的 console.log 打印日志也使用了它,不信你打开 Node runtime 的源码,看看 lib/console.js:
1 | function write(ignoreErrors, stream, string, errorhandler) { |
Stream 模块做了很多事情,了解了 Stream,那么 Node 中其他很多模块理解起来就顺畅多了。
本文代码和图片可以在这里取用:https://github.com/barretlee/dive-into-node-stream。
14.1 stream 模块
如果你了解 生产者和消费者问题 的解法,那理解 stream 就基本没有压力了,它不仅仅是资料的起点和落点,还包含了一系列状态控制,可以说一个 stream 就是一个状态管理单元。了解内部机制的最佳方式除了看 Node 官方文档,还可以去看看 Node 的 源码:
lib/module.jslib/_stream_readable.jslib/_stream_writable.jslib/_stream_tranform.jslib/_stream_duplex.js
把 Readable 和 Writable 看明白,Tranform 和 Duplex 就不难理解了。
14.2 Readable Stream
Readable Stream 存在两种模式,一种是叫做 Flowing Mode,流动模式,在 Stream 上绑定 ondata 方法就会自动触发这个模式,比如:
1 | const readable = getReadableStreamSomehow(); |
这个模式的流程图如下:
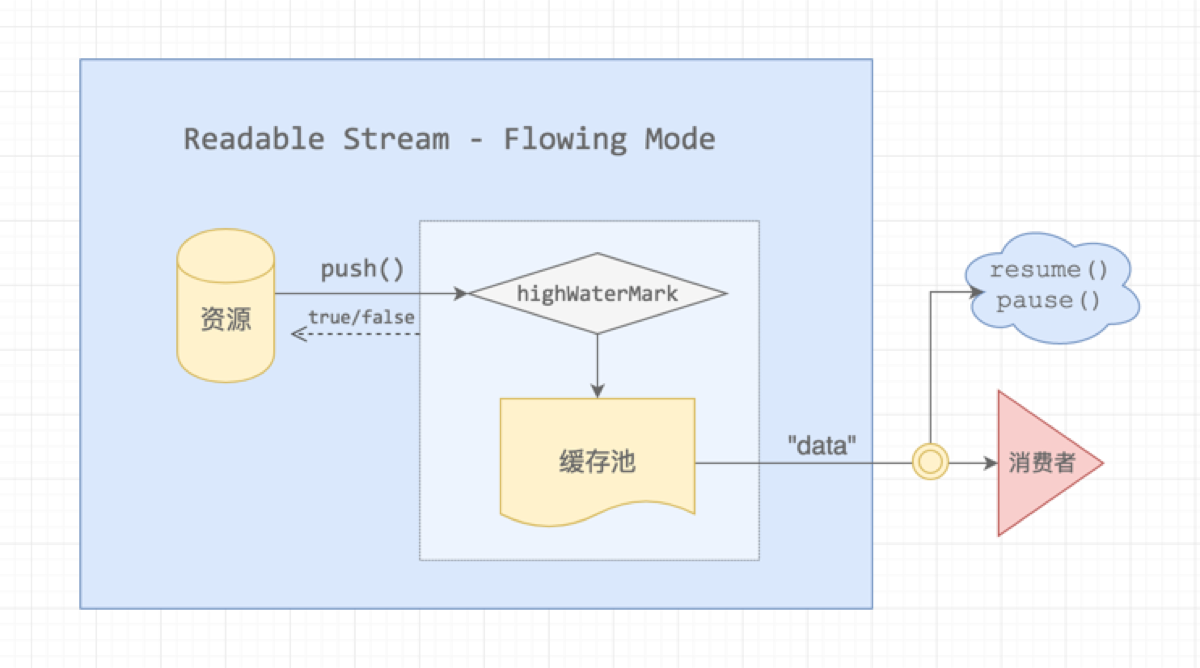
资源的数据流并不是直接流向消费者,而是先 push 到缓存池,缓存池有一个水位标记 highWatermark,超过这个标记阈值,push 的时候会返回 false,什么场景下会出现这种情况呢?
- 消费者主动执行了
.pause() - 消费速度比数据 push 到缓存池的生产速度慢
有个专有名词来形成这种情况,叫做「背压」,Writable Stream 也存在类似的情况。
流动模式,这个名词还是很形象的,缓存池就像一个水桶,消费者通过管口接水,同时,资源池就像一个水泵,不断地往水桶中泵水,而 highWaterMark 是水桶的浮标,达到阈值就停止蓄水。下面是一个简单的 Demo:
1 | const Readable = require('stream').Readable; |
另外一种模式是 Non-Flowing Mode,没流动,也就是暂停模式,这是 Stream 的预设模式,Stream 实例的 _readableState.flow 有三个状态,分别是:
_readableState.flow = null,暂时没有消费者过来_readableState.flow = false,主动触发了.pause()_readableState.flow = true,流动模式
当我们监听了 onreadable 事件后,会进入这种模式,比如:
1 | const myReadable = new MyReadable(dataSource); |
监听 readable 的回调函数第一个参数不会传递内容,需要我们通过 myReadable.read() 主动读取,为啥呢,可以看看下面这张图:
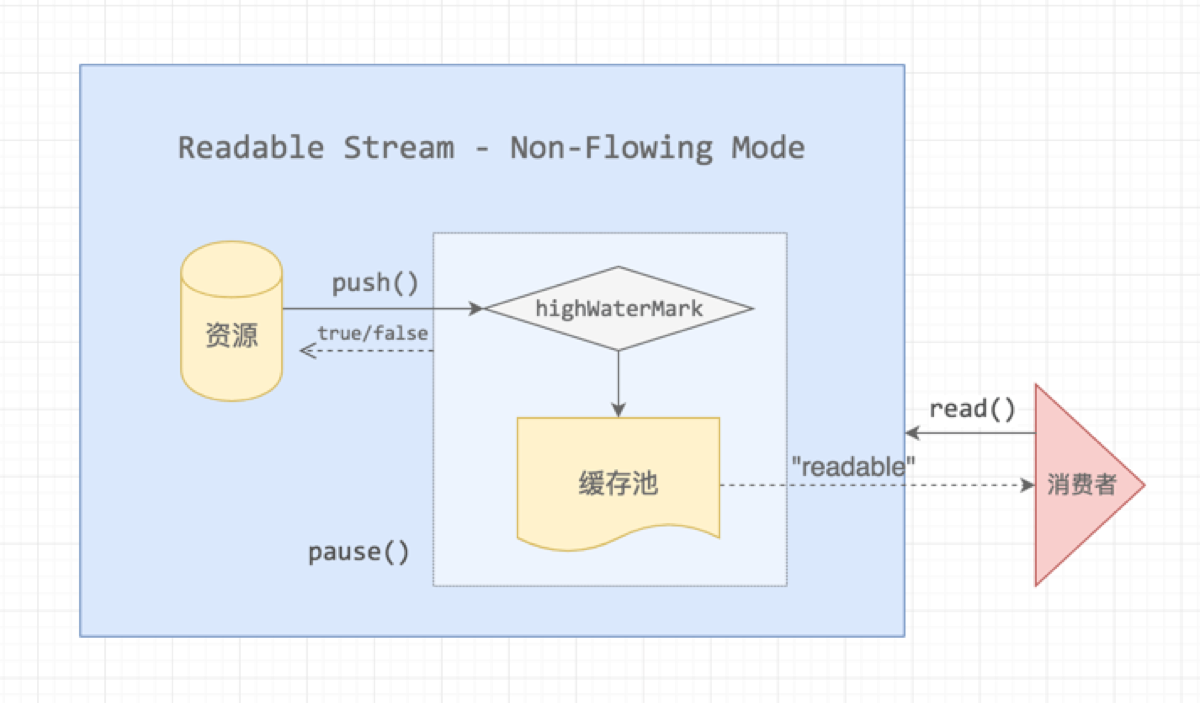
资源池会不断地往缓存池输送数据,直到 highWaterMark 阈值,消费者监听了 readable 事件并不会消费数据,需要主动调用 .read([size]) 函数才会从缓存池取出,并且可以带上 size 参数,用多少就取多少:
1 | const myReadable = new MyReadable(dataSource); |
这里需要注意一点,只要数据达到缓存池都会触发一次 readable 事件,有可能出现「消费者正在消费数据的时候,又触发了一次 readable 事件,那么下次回调中 read 到的数据可能为空」的情况。我们可以通过 _readableState.buffer 来查看缓存池到底缓存了多少资源:
1 | let once = false; |
上面的代码我们只消费一次缓存池的数据,那么在消费后,缓存池又收到了一次资源池的 push 操作,此时还会触发一次 readable 事件,我们可以看看这次存了多大的 buffer。
需要注意的是,buffer 大小也是有上限的,默认设置为 16kb,也就是 16384 个字节长度,它最大可设置为 8Mb,没记错的话,这个值好像是 Node 的 new space memory 的大小。
上面介绍了 Readable Stream 大概的机制,还有很多细节部分没有提到,比如 Flowing Mode 在不同 Node 版本中的 Stream 实现不太一样,实际上,它有三个版本,上面提到的是第 2 和 第 3 个版本的实现;再比如 Mixins Mode 模式,一般我们只推荐(允许)使用 ondata 和 onreadable 的一种来处理 Readable Stream,但是如果要求在 Non-Flowing Mode 的情况下使用 ondata 如何实现呢?那么就可以考虑 Mixins Mode 了。
14.3 Writable Stream
原理与 Readable Stream 是比较相似的,数据流过来的时候,会直接写入到资源池,当写入速度比较缓慢或者写入暂停时,数据流会进入队列池缓存起来,如下图所示:
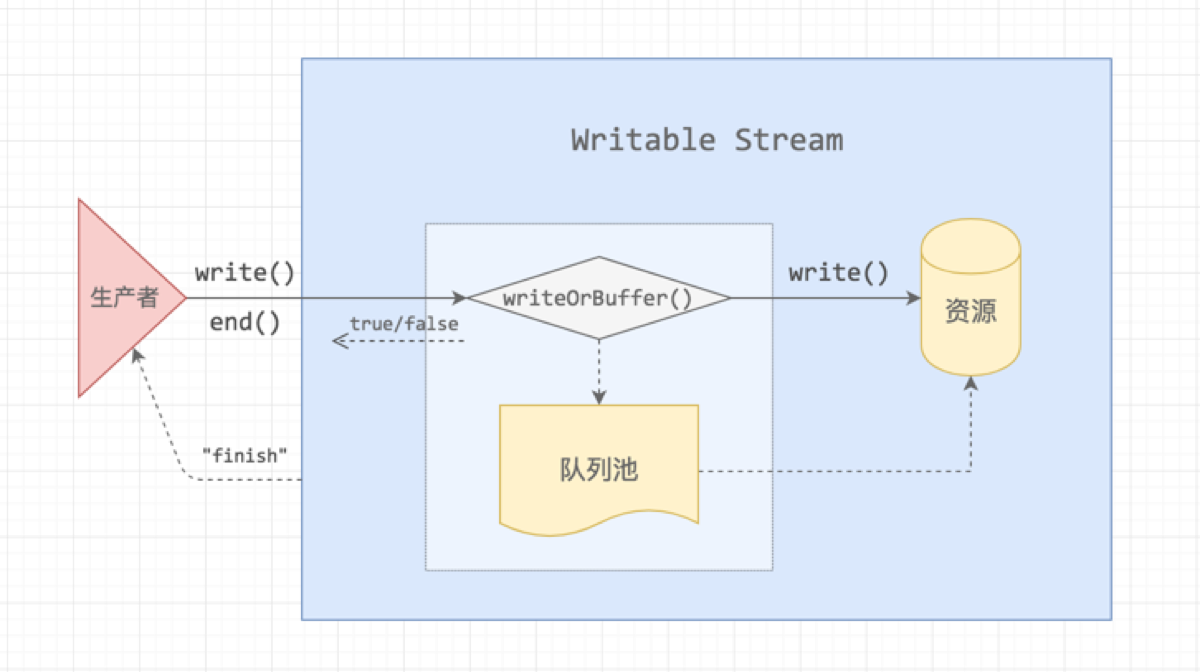
当生产者写入速度过快,把队列池装满了之后,就会出现「背压」,这个时候是需要告诉生产者暂停生产的,当队列释放之后,Writable Stream 会给生产者发送一个 drain 消息,让它恢复生产。下面是一个写入一百万条数据的 Demo:
1 | function writeOneMillionTimes(writer, data, encoding, callback) { |
我们构造一个 Writable Stream,在写入到资源池的时候,我们稍作处理,让它效率低一点:
1 | const Writable = require('stream').Writable; |
最后执行的结果是:
1 | drain 7268 |
说明程序遇到了三次「背压」,如果我们没有在上面绑定 writer.once('drain'),那么最后的结果就是 Stream 将第一次获取的数据消耗完变结束了程序。
14.4 pipe
了解了 Readable 和 Writable,pipe 这个常用的函数应该就很好理解了,
1 | readable.pipe(writable); |
这句代码的语意性很强,readable 通过 pipe(管道)传输给 writable,pipe 的实现大致如下(伪代码):
1 | Readable.prototype.pipe = function(writable, options) { |
上面做了五件事情:
emit(pipe),通知写入.write(),新数据过来,写入.pause(),消费者消费速度慢,暂停写入.resume(),消费者完成消费,继续写入return writable,支持链式调用
当然,上面只是最简单的逻辑,还有很多异常和临界判断没有加入,具体可以去看看 Node 的代码( /lib/_stream_readable.js)。
14.5 Duplex Stream
Duplex,双工的意思,它的输入和输出可以没有任何关系,
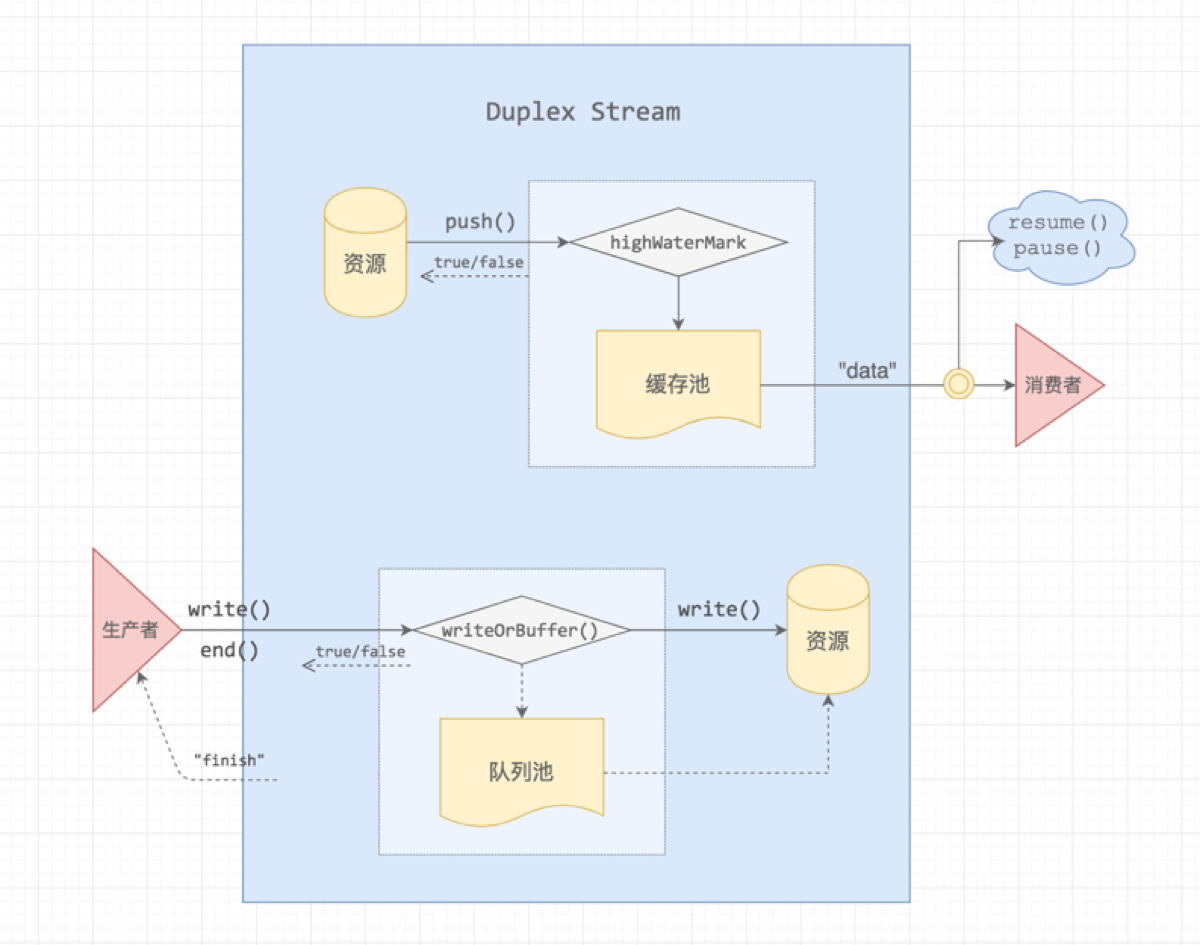
Duplex Stream 实现特别简单,不到一百行代码,它继承了 Readable Stream,并拥有 Writable Stream 的方法(源码地址):
1 | const util = require('util'); |
我们可以通过 options 参数来配置它为只可读、只可写或者半工模式,一个简单的 Demo:
1 | var Duplex = require('stream').Duplex |
输出的结果为:
1 | write |
可以看出,两个管道是相互之间不干扰的。
14.6 Transform Stream
Transform Stream 集成了 Duplex Stream,它同样具备 Readable 和 Writable 的能力,只不过它的输入和输出是存在相互关联的,中间做了一次转换处理。常见的处理有 Gzip 压缩、解压等。
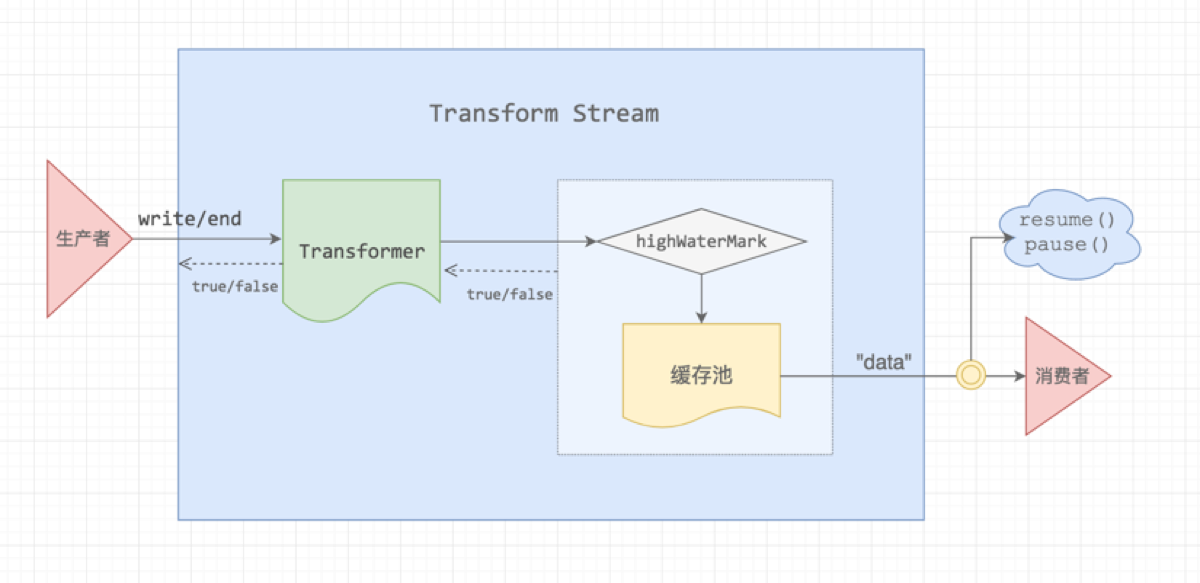
Transform 的处理就是通过 _transform 函数将 Duplex 的 Readable 连接到 Writable,由于 Readable 的生产效率与 Writable 的消费效率是一样的,所以这里 Transform 内部不存在「背压」问题,背压问题的源头是外部的生产者和消费者速度差造成的。
关于 Transfrom Stream,我写了一个简单的 Demo:
1 | const Transform = require('stream').Transform; |
小结
本文主要参考和查阅 Node 官网的文档和源码,细节问题都是从源码中找到的答案,如有理解不准确之处,还请斧正。关于 Stream,这篇文章只是讲述了基础的原理,还有很多细节之处没有讲到,要真正理解它,还是需要多读读文档,写写代码。
了解了这些 Stream 的内部机制,对我们后续深入理解上层代码有很大的促进作用,特别希望初学 Node 的同学花点时间进来看看。
另外,本文代码和图片可以在这里取用:https://github.com/barretlee/dive-into-node-stream。
15.pipe原理
通过流我们可以将一大块数据拆分为一小部分一点一点的流动起来,而无需一次性全部读入,在 Linux 下我们可以通过 | 符号实现,类似的在 Nodejs 的 Stream 模块中同样也为我们提供了 pipe() 方法来实现。
15.1 Nodejs Stream pipe 基本示例
选择 Koa 来实现这个简单的 Demo,因为之前有人在 “Nodejs技术栈” 交流群问过一个问题,怎么在 Koa 中返回一个 Stream,顺便在下文借此机会提下。
15.1.1 未使用 Stream pipe 情况
在 Nodejs 中 I/O 操作都是异步的,先用 util 模块的 promisify 方法将 fs.readFile 的 callback 形式转为 Promise 形式,这块代码看似没问题,但是它的体验不是很好,因为它是将数据一次性读入内存再进行的返回,当数据文件很大的时候也是对内存的一种消耗,因此不推荐它。
1 | const Koa = require('koa'); |
15.1.2 使用 Stream pipe 情况
下面,再看看怎么通过 Stream 的方式在 Koa 框架中响应数据
1 | ... |
以上在 Koa 中直接创建一个可读流赋值给 ctx.body 就可以了,你可能疑惑了为什么没有 pipe 方法,因为框架给你封装好了,不要被表象所迷惑了,看下相关源码:
1 | // https://github.com/koajs/koa/blob/master/lib/application.js#L256 |
没有神奇之处,框架在返回的时候做了层判断,因为 res 是一个可写流对象,如果 body 也是一个 Stream 对象(此时的 Body 是一个可读流),则使用 body.pipe(res) 以流的方式进行响应。
15.1.3 使用 Stream VS 不使用 Stream
使用流:

不适用流:

15.2 pipe 的调用过程与实现原理分析
以上最后以流的方式响应数据最核心的实现就是使用 pipe 方法来实现的输入、输出,本节的重点也是研究 pipe 的实现,最好的打开方式通过阅读源码实现吧。
15.2.1 顺藤摸瓜
在应用层我们调用了 fs.createReadStream() 这个方法,顺藤摸瓜找到这个方法创建的可读流对象的 pipe 方法实现,以下仅列举核心代码实现,基于 Nodejs v12.x 源码。
15.2.1.1 /lib/fs.js
导出一个 createReadStream 方法,在这个方法里面创建了一个 ReadStream 可读流对象,且 ReadStream 来自 internal/fs/streams 文件,继续向下找。
1 | // https://github.com/nodejs/node/blob/v12.x/lib/fs.js |
15.2.1.2 /lib/internal/fs/streams.js
这个方法里定义了构造函数 ReadStream,且在原型上定义了 open、_read、_destroy 等方法,并没有我们要找的 pipe 方法。
但是呢通过 ObjectSetPrototypeOf 方法实现了继承,ReadStream 继承了 Readable 在原型中定义的函数,接下来继续查找 Readable 的实现。
1 | // https://github.com/nodejs/node/blob/v12.x/lib/internal/fs/streams.js |
15.2.1.3 /lib/stream.js
在 stream.js 的实现中,有条注释:**在 Readable/Writable/Duplex/… 之前导入 Stream,原因是为了避免 cross-reference(require)**,为什么会这样?
第一步 stream.js 这里将 require(‘internal/streams/legacy’) 导出复制给了 Stream。
在之后的 _stream_readable、Writable、Duplex … 模块也会反过来引用 stream.js 文件,具体实现下面会看到。
Stream 导入了 internal/streams/legacy
上面 /lib/internal/fs/streams.js 文件从 stream 模块获取了一个 Readable 对象,就是下面的 Stream.Readable 的定义。
1 | // https://github.com/nodejs/node/blob/v12.x/lib/stream.js |
15.2.1.4 /lib/internal/streams/legacy.js
上面的 Stream 等于 internal/streams/legacy,首先继承了 Events 模块,之后呢在原型上定义了 pipe 方法,刚开始看到这里的时候以为实现是在这里了,但后来看 _stream_readable 的实现之后,发现 _stream_readable 继承了 Stream 之后自己又重新实现了 pipe 方法,那么疑问来了这个模块的 pipe 方法是干嘛的?什么时候会被用?翻译文件名 “legacy=遗留”?有点没太理解,难道是遗留了?有清楚的大佬可以指点下,也欢迎在公众号 “Nodejs技术栈” 后台加我微信一块讨论下!
1 | // https://github.com/nodejs/node/blob/v12.x/lib/internal/streams/legacy.js |
15.2.1.5 /lib/_stream_readable.js
在 _stream_readable.js 的实现里面定义了 Readable 构造函数,且继承于 Stream,这个 Stream 正是我们上面提到的 /lib/stream.js 文件,而在 /lib/stream.js 文件里加载了 internal/streams/legacy 文件且重写了里面定义的 pipe 方法。
经过上面一系列的分析,终于找到可读流的 pipe 在哪里,同时也更进一步的认识到了在创建一个可读流时的执行调用过程,下面将重点来看这个方法的实现。
1 | module.exports = Readable; |
15.2.2 _stream_readable 实现分析
15.2.2.1 声明构造函数 Readable
声明构造函数 Readable 继承 Stream 的构造函数和原型。
Stream 是 /lib/stream.js 文件,上面分析了,这个文件继承了 events 事件,此时也就拥有了 events 在原型中定义的属性,例如 on、emit 等方法。
1 | const Stream = require('stream'); |
15.2.2.2 声明 pipe 方法,订阅 data 事件
在 Stream 的原型上声明 pipe 方法,订阅 data 事件,src 为可读流对象,dest 为可写流对象。
我们在使用 pipe 方法的时候也是监听的 data 事件,一边读取数据一边写入数据。
看下 ondata() 方法里的几个核心实现:
- dest.write(chunk)**:接收 chunk 写入数据,如果内部的缓冲小于创建流时配置的 highWaterMark,则返回 true,否则返回 false 时应该停止向流写入数据,直到 ‘drain’ 事件被触发**。
- **src.pause()**:可读流会停止 data 事件,意味着此时暂停数据写入了。
之所以调用 src.pause() 是为了防止读入数据过快来不及写入,什么时候知道来不及写入呢,要看 dest.write(chunk) 什么时候返回 false,是根据创建流时传的 highWaterMark 属性,默认为 16384 (16kb),对象模式的流默认为 16。
1 | Readable.prototype.pipe = function(dest, options) { |
15.2.2.3 订阅 drain 事件,继续流动数据
上面提到在 data 事件里,如果调用 dest.write(chunk) 返回 false,就会调用 src.pause() 停止数据流动,什么时候再次开启呢?
如果说可以继续写入事件到流时会触发 drain 事件,也是在 dest.write(chunk) 等于 false 时,如果 ondrain 不存在则注册 drain 事件。
1 | Readable.prototype.pipe = function(dest, options) { |
15.2.2.4 触发 data 事件
调用 readable 的 resume() 方法,触发可读流的 ‘data’ 事件,进入流动模式。
1 | Readable.prototype.pipe = function(dest, options) { |
然后实例上的 resume(Readable 原型上定义的)会在调用 resume() 方法,在该方法内部又调用了 resume_(),最终执行了 stream.read(0) 读取了一次空数据(size 设置的为 0),将会触发实例上的 _read() 方法,之后会在触发 data 事件。
1 | function resume(stream, state) { |
15.2.2.5 订阅 end 事件
end 事件:当可读流中没有数据可供消费时触发,调用 onend 函数,执行 dest.end() 方法,表明已没有数据要被写入可写流,进行关闭(关闭可写流的 fd),之后再调用 stream.write() 会导致错误。
1 | Readable.prototype.pipe = function(dest, options) { |
15.2.2.6 触发 pipe 事件
在 pipe 方法里面最后还会触发一个 pipe 事件,传入可读流对象
1 | Readable.prototype.pipe = function(dest, options) { |
在应用层使用的时候可以在可写流上订阅 pipe 事件,做一些判断,具体可参考官网给的这个示例 stream_event_pipe
15.2.2.7 支持链式调用
最后返回 dest,支持类似 unix 的用法:A.pipe(B).pipe(C)
1 | Stream.prototype.pipe = function(dest, options) { |
15.3 总结
本文总体分为两部分:
- 第一部分相对较基础,讲解了 Nodejs Stream 的 pipe 方法在 Koa2 中是怎么去应用的。
- 第二部分仍以 Nodejs Stream pipe 方法为题,查找它的实现,以及对源码的一个简单分析,其实 pipe 方法核心还是要去监听 data 事件,向可写流写入数据,如果内部缓冲大于创建流时配置的 highWaterMark,则要停止数据流动,直到 drain 事件触发或者结束,当然还要监听 end、error 等事件做一些处理。
15.4 Reference
- nodejs.cn/api/stream.html
- cnodejs.org/topic/56ba030271204e03637a3870
- github.com/nodejs/node/blob/master/lib/_stream_readable.js
16.守护进程
16.1 Nodejs编写守护进程
目前Nodejs编写一个守护进程非常简单,在6.3.1版本中已经存在非常方便的API,这些API可以帮助我们更方便的创建一个守护进程。本文仅在描述守护进程的创建方式,而不会对守护进程所要执行的任务做任何描述。
16.2 守护进程的启动方式
如果不在Nodejs环境中,我们如何创建守护进程?过程如下:
- 创建一个进程A。
- 在进程A中创建进程B,我们可以使用fork方式,或者其他方法。
- 对进程B执行
setsid方法。 - 进程A退出,进程B由init进程接管。此时进程B为守护进程。
16.3 setsid详解
setsid 主要完成三件事:
- 该进程变成一个新会话的会话领导。
- 该进程变成一个新进程组的组长。
- 该进程没有控制终端。
然而,Nodejs中并没有对 setsid 方法的直接封装,翻阅文档发现有一个地方是可以调用该方法的。
16.4 Nodejs中启动子进程方法
借助 clild_process 中的 spawn 即可创建子进程,方法如下:
1 | ar spawn = require('child_process').spawn; |
注意,这里只打印当前进程的PID和子进程的PID,同时为了观察效果,我并没有将父进程退出。
b.js 中代码很简单,打开一个资源,并不停的写入数据。
1 | var fs = require('fs'); |
运行后的效果如图:

我们来看以下 top 命令下的进程情况。

看一看到,此时父进程PID为17055,子进程的PPID为17055,PID为17056.
16.5 Nodejs中setsid的调用
到此为止,守护进程已经完成一半,下面要调用setsid方法,并且退出父进程。
代码修改如下:
1 | var spawn = require('child_process').spawn; |
在 spawn 的第三个参数中,可以设置 detached 属性,如果该属性为true,则会调用 setsid 方法。这样就满足我们对守护进程的要求。
在此运行命令。

查看 top 命令

可以看到,当前仅存在一个PID为17062的进程,这个进程就是我们要的守护进程。
由于每次运行PID都不同,所以此次子进程的PID于第一次不同。
总结
守护进程最重要的是稳定,如果守护进程挂掉,那么其管理的子进程都将变为孤儿进程,同时被init进程接管,这是我们不愿意看到的。于此同时,守护进程对于子进程的管理也是有非常多的发挥余地的,例如PM2中,将一个进程同时启动4次,达到CPU多核使用的目的(很有可能你的进程在同一核中运行),进程挂掉后自动重启等等,这些事情等着我们去造轮子。
总体来说,Nodejs启动守护进程方式比较简单,默认所暴露的API也屏蔽了很多系统级别API,使得大家使用上更加方便,但没有接触过Linux的人在理解上有一些复杂。推荐大家学习Nodejs的同时,多学习Linux系统调用的和系统内核的一些东西。
17.Nodejs进程间通信
17.1 场景
Node运行在单线程下,但这并不意味着无法利用多核/多机下多进程的优势
事实上,Node最初从设计上就考虑了分布式网络场景:
Node is a single-threaded, single-process system which enforces shared-nothing design with OS process boundaries. It has rather good libraries for networking. I believe this to be a basis for designing very large distributed programs. The “nodes” need to be organized: given a communication protocol, told how to connect to each other. In the next couple months we are working on libraries for Node that allow these networks.
P.S.关于Node之所以叫Node,见Why is Node.js named Node.js?
17.2 创建进程
通信方式与进程产生方式有关,而Node有4种创建进程的方式:spawn(),exec(),execFile()和fork()
spawn
1 | const { spawn } = require('child_process'); |
spawn()返回ChildProcess实例,ChildProcess同样基于事件机制(EventEmitter API),提供了一些事件:
exit:子进程退出时触发,可以得知进程退出状态(code和signal)disconnect:父进程调用child.disconnect()时触发error:子进程创建失败,或被kill时触发close:子进程的stdio流(标准输入输出流)关闭时触发message:子进程通过process.send()发送消息时触发,父子进程之间可以通过这种内置的消息机制通信
可以通过child.stdin,child.stdout和child.stderr访问子进程的stdio流,这些流被关闭的时,子进程会触发close事件
P.S.close与exit的区别主要体现在多进程共享同一stdio流的场景,某个进程退出了并不意味着stdio流被关闭了
在子进程中,stdout/stderr具有Readable特性,而stdin具有Writable特性,与主进程的情况正好相反:
1 | child.stdout.on('data', (data) => { |
利用进程stdio流的管道特性,就可以完成更复杂的事情,例如:
1 | const { spawn } = require('child_process'); |
作用等价于find . -type f | wc -l,递归统计当前目录文件数量
IPC选项
另外,通过spawn()方法的stdio选项可以建立IPC机制:
1 | const { spawn } = require('child_process'); |
关于spawn()的IPC选项的详细信息,请查看options.stdio
exec
spawn()方法默认不会创建shell去执行传入的命令(所以性能上稍微好一点),而exec()方法会创建一个shell。另外,exec()不是基于stream的,而是把传入命令的执行结果暂存到buffer中,再整个传递给回调函数
exec()方法的特点是完全支持shell语法,可以直接传入任意shell脚本,例如:
1 | const { exec } = require('child_process'); |
但exec()方法也因此存在命令注入的安全风险,在含有用户输入等动态内容的场景要特别注意。所以,exec()方法的适用场景是:希望直接使用shell语法,并且预期输出数据量不大(不存在内存压力)
那么,有没有既支持shell语法,还具有stream IO优势的方式?
有。两全其美的方式如下:
1 | const { spawn } = require('child_process'); |
开启spawn()的shell选项,并通过pipe()方法把子进程的标准输出简单地接到当前进程的标准输入上,以便看到命令执行结果。实际上还有更容易的方式:
1 | const { spawn } = require('child_process'); |
stdio: 'inherit'允许子进程继承当前进程的标准输入输出(共享stdin,stdout和stderr),所以上例能够通过监听当前进程process.stdout的data事件拿到子进程的输出结果
另外,除了stdio和shell选项,spawn()还支持一些其它选项,如:
1 | const child = spawn('find . -type f | wc -l', { |
注意,env选项除了以环境变量形式向子进程传递数据外,还可以用来实现沙箱式的环境变量隔离,默认把process.env作为子进程的环境变量集,子进程与当前进程一样能够访问所有环境变量,如果像上例中指定自定义对象作为子进程的环境变量集,子进程就无法访问其它环境变量
所以,想要增/删环境变量的话,需要这样做:
1 | var spawn_env = JSON.parse(JSON.stringify(process.env)); |
detached选项更有意思:
1 | const { spawn } = require('child_process'); |
以这种方式创建的独立进程行为取决于操作系统,Windows上detached子进程将拥有自己的console窗口,而Linux上该进程会创建新的process group(这个特性可以用来管理子进程族,实现类似于tree-kill的特性)
unref()方法用来断绝关系,这样“父”进程可以独立退出(不会导致子进程跟着退出),但要注意这时子进程的stdio也应该独立于“父”进程,否则“父”进程退出后子进程仍会受到影响
execFile
1 | const { execFile } = require('child_process'); |
与exec()方法类似,但不通过shell来执行(所以性能稍好一点),所以要求传入可执行文件。Windows下某些文件无法直接执行,比如.bat和.cmd,这些文件就不能用execFile()来执行,只能借助exec()或开启了shell选项的spawn()
P.S.与exec()一样也不是基于stream的,同样存在输出数据量风险
xxxSync
spawn,exec和execFile都有对应的同步阻塞版本,一直等到子进程退出
1 | const { |
同步方法用来简化脚本任务,比如启动流程,其它时候应该避免使用这些方法
fork
fork()是spawn()的变体,用来创建Node进程,最大的特点是父子进程自带通信机制(IPC管道):
The child_process.fork() method is a special case of child_process.spawn() used specifically to spawn new Node.js processes. Like child_process.spawn(), a ChildProcess object is returned. The returned ChildProcess will have an additional communication channel built-in that allows messages to be passed back and forth between the parent and child. See subprocess.send() for details.
例如:
1 | var n = child_process.fork('./child.js'); |
因为fork()自带通信机制的优势,尤其适合用来拆分耗时逻辑,例如:
1 | const http = require('http'); |
这样做的致命问题是一旦有人访问/compute,后续请求都无法及时处理,因为事件循环还被longComputation阻塞着,直到耗时计算结束才能恢复服务能力
为了避免耗时操作阻塞主进程的事件循环,可以把longComputation()拆分到子进程中:
1 | // compute.js |
主进程开启子进程执行longComputation:
1 | const http = require('http'); |
主进程的事件循环不会再被耗时计算阻塞,但进程数量还需要进一步限制,否则资源被进程消耗殆尽时服务能力仍会受到影响
P.S.实际上,cluster模块就是对多进程服务能力的封装,思路与这个简单示例类似
17.3 通信方式
17.3.1 通过stdin/stdout传递json
stdin/stdout and a JSON payload
最直接的通信方式,拿到子进程的handle后,可以访问其stdio流,然后约定一种message格式开始愉快地通信:
1 | const { spawn } = require('child_process'); |
子进程与之类似:
1 | // ./stdio-child.js |
P.S.VS Code进程间通信就采用了这种方式,具体见access electron API from vscode extension
明显的限制是需要拿到“子”进程的handle,两个完全独立的进程之间无法通过这种方式来通信(比如跨应用,甚至跨机器的场景)
P.S.关于stream及pipe的详细信息,请查看Node中的流
17.3.2 原生IPC支持
如spawn()及fork()的例子,进程之间可以借助内置的IPC机制通信
父进程:
process.on('message')收child.send()发
子进程:
process.on('message')收process.send()发
限制同上,同样要有一方能够拿到另一方的handle才行
17.3.3 sockets
借助网络来完成进程间通信,不仅能跨进程,还能跨机器
node-ipc就采用这种方案,例如:
1 | // server |
P.S.更多示例见RIAEvangelist/node-ipc
当然,单机场景下通过网络来完成进程间通信有些浪费性能,但网络通信的优势在于跨环境的兼容性与更进一步的RPC场景
17.3.4 message queue
父子进程都通过外部消息机制来通信,跨进程的能力取决于MQ支持
即进程间不直接通信,而是通过中间层(MQ),加一个控制层就能获得更多灵活性和优势:
- 稳定性:消息机制提供了强大的稳定性保证,比如确认送达(消息回执ACK),失败重发/防止多发等等
- 优先级控制:允许调整消息响应次序
- 离线能力:消息可以被缓存
- 事务性消息处理:把关联消息组合成事务,保证其送达顺序及完整性
P.S.不好实现?包一层能解决吗,不行就包两层……
比较受欢迎的有smrchy/rsmq,例如:
1 | // init |
会起一个Redis server,基本原理如下:
Using a shared Redis server multiple Node.js processes can send / receive messages.
消息的收/发/缓存/持久化依靠Redis提供的能力,在此基础上实现完整的队列机制
17.3.5 Redis
基本思路与message queue类似:
Use Redis as a message bus/broker.
Redis自带Pub/Sub机制(即发布-订阅模式),适用于简单的通信场景,比如一对一或一对多并且不关注消息可靠性的场景
另外,Redis有list结构,可以用作消息队列,以此提高消息可靠性。一般做法是生产者LPUSH消息,消费者BRPOP消息。适用于要求消息可靠性的简单通信场景,但缺点是消息不具状态,且没有ACK机制,无法满足复杂的通信需求
P.S.Redis的Pub/Sub示例见What’s the most efficient node.js inter-process communication library/method?
17.4 总结
Node进程间通信有4种方式:
- 通过stdin/stdout传递json:最直接的方式,适用于能够拿到“子”进程handle的场景,适用于关联进程之间通信,无法跨机器
- Node原生IPC支持:最native(地道?)的方式,比上一种“正规”一些,具有同样的局限性
- 通过sockets:最通用的方式,有良好的跨环境能力,但存在网络的性能损耗
- 借助message queue:最强大的方式,既然要通信,场景还复杂,不妨扩展出一层消息中间件,漂亮地解决各种通信问题
参考资料
18.Node.js 捕获异常
采用事件轮训、异步 IO 等机制使得 Node.js 能够从容应对无阻塞高并发场景,令工程师很困扰的几个理解 Node.js 的地方除了它的事件(回调)机制,还有一个同样头痛的是异常代码的捕获。
18.1 try/catch 之痛
一般情况下,我们会将有可能出错的代码放到 try/catch 块里。但是到了 Node.js,由于 try/catch 无法捕捉异步回调里的异常,Node.js 原生提供 uncaughtException 事件挂到 process 对象上,用于捕获所有未处理的异常:
1 | process.on('uncaughtException', function(err) { |
执行的结果是代码进到了 uncaughtException 的回调里而不是 catch 块。 uncaughtException 虽然能够捕获异常,但是此时错误的上下文已经丢失,即使看到错误也不知道哪儿报的错,定位问题非常的不利。而且一旦 uncaughtException 事件触发,整个 node 进程将 crash 掉,如果不做一些善后处理的话会导致整个服务挂掉,这对于线上的服务来说将是非常不好的。
18.2 使用 domain 模块捕捉异常
随 Node.js v0.8 版本发布了一个 domain(域)模块,专门用于处理异步回调的异常,使用 domain 我们将很轻松的捕获异步异常:
运行上面的代码,我们会看到错误被 domain 捕获到,并且 uncaughtException 回调并不会执行,事情似乎变得稍微容易些了。
但是如果研究 domain 模块的 API 很快我们会发现,domain 提供了好几个方法,理解起来似乎不是那么直观(其实为啥这个模块叫 “域 (domain)” 呢,总感觉些许别扭),这里简单解释下:
1 | process.on('uncaughtException', function(err) { |
首先,关于 domain 模块,我们看到它的稳定性是 2,也就是不稳定,API 可能会变更。
默认情况下,domain 模块是不被引入的,当 domain.create()创建一个 domain 之后,调用 enter()方法即可 “激活” 这个 domain,具体表现为全局的进程(process)对象上会有一个 domain 属性指向之前创建的这个的 domain 实例,同时,domain 模块上有个 active 属性也指向这个的 domain 实例。、
结合 should 断言库测试下上面说的:
1 | // domain was not exists by default |
执行之后发现几个断言都能 pass。exit()方法的意思是退出当前 “域”,将会影响到后续异步异常的捕获,后面会提到。
enter 和 exit 组合调用这样会使代码有些混乱,尤其是当多个 domain 混合、嵌套使用时比较难理解。
这时候可以使用 run()方法,run()其实就是对 enter 和 exit 以及回调的简单封装,即:run() – callback() – exit() 这样,就像上面例子中的 run()一样。
还有两个方法,bind()和 intercept():
bind:
1 | fs.readFile('non_existent.js', d.bind(function(err, buf) { |
intercept:
1 | fs.readFile('non_existent.js', d.intercept(function(buf) { |
用法差不多,只是 intercept 拦截了异步回调,如果抛出异常就自己处理掉了。
18.2.1 domain 的隐式绑定
domain 主要会影响 timers 模块(包括 setTimeout, setInterval, setImmediate), 事件循环 process.nextTick,还有就是 event。
实现的思路都差不多,都是通过注入 domain 代码到 timer、nextTick、event 模块中,在创建的时候检查当前有没有激活(active)的 domain,有则记录下,如果是 timer 和 nextTick,当在事件循环中执行回调的时候,把 process.domain 设置为之前记录的 domain 并把错误交给它处理。如果是 event,多一步判断,先会把异常交给 event 自己定义的 error 事件处理。
这里要注意,如果这个 domain 没有绑定 error 事件的话,node 会直接抛出错误,即使 uncaughtException 绑定了也没有用:
1 | process.on('uncaughtException', function(err) { |
在这个例子里面,使用了 domain 捕获异常但是没有监听 domain 的 error 事件,监听了 uncaughtException,但是还是抛出了异常,个人觉得觉得这里是个 bug,domain 没有 errorHandle 应该把异常交给全局的 uncaughtException,后面有例子验证这一点。
还有一个小问题,同时监听了 uncaughtException 和 domain 的 error 事件,在 node v0.8 里有个 bug,uncaughtException 和 domain 都能捕获异常,0.10+已经修复。
18.2.2 domain 的显式绑定
上面没有提到的两个 API 是 add()和 remove(),add 作用是把 domain 创建之前创建的(EventEmitter 实例)对象添加到这个 domain 里边,然后这个对象即可使用 domain 捕捉异常了,remove 则相反。domain 对象上有个 numbers 队列专门用于管理 add 后的对象。
这里可参考官方示例。
18.2.3 domain 如何抛出异常
我们看 node 源码有这么一行:
1 | // do this good and early, since it handles errors. |
processFatal 里边调用 process._fatalException(),先判断是否存在 process.domain,尝试把错误交给 process.domain 处理,如果不存在才交给 uncaughtException 处理,所以 domain 捕获异常的关键代码在 node.js#L219。
这里尝试修改下上面的例子,在抛出异常前把 process.domain 设为 null:
1 | d.run(function() { |
这下 uncaughtException 将捕获异常!
当上面提到的异常都没被捕获,进程将直接退出 node.js#L280:
1 | // if someone handled it, then great. otherwise, die in C++ land |
另外关于 domain 如何在多个不同的事件循环中传递,可以参考下这篇文章。
值得关注的是,并不是所有在 domain 域下创建的事件分发器(EventEmitter)上面的异步异常都能捕获:
1 | var d = domain.create(); |
这个例子中,msg 对象虽然是在 domain 中实例化,但是 msg.send 里边 fs.readFile 在执行回调的时候,process.domain 是 undefined。
我们稍微改造下,把 readFile 的回调绑定到 domain 上,或者把 msg.send() 的调用放到 d.run() 包裹,结果可预知,能正常捕获抛出的异常。为了验证,尝试改造下 readFile:
1 | fs.readFile(file, function(err, buf) { |
这样亦可捕获异常,不过实际中不要这样写,还是要采用 domain 提供的方法。
更好的使用 domain
其实上,更推荐的做法是,如果在活动 domain 里面创建了事件分发器(EventEmitter)实例,我们应该尽可能的给它注册 error 事件,把错误都抛给这个 EventEmitter 实例处理,就像上面的例子,我们改造下,绑定 error 事件并把 readFile 的错误交给 Msg 实例处理:
1 | this.on('error', function(err) { |
在书写 Node.js 代码的时候,对于事件分发器,应该养成先绑定(on()或 addEventListener())后触发(emit())的习惯。在执行事件回调的时候,对于有可能抛异常的情况,应该把 emit 放到 domain 里去:
1 | var d = domain.create(); |
根据 domain#L187 可知,run 会把传进去的函数包装成另一个函数返回,并在这个返回的函数上设置 domain:
1 | b.domain = this; |
events 模块 events.js#L85 有这么一行:
1 |
当调用 e.emit() 的时候,如果回调函数上挂有 domain,则将这个 domain 激活,进而可以捕获异常。
domain 的缺陷
有了 domain,似乎异步异常捕捉已经不再是难事。Node.js 允许创建多个 domain 实例,并允许使用 add 添加多个事件分发器给 domain 管理,,而且 domain 之间可以相互嵌套,而创建 domain,是有一定的性能耗损的,这样带来了一个棘手的问题是:多个 domain 如何合理的创建与销毁,domain 的运行期应该如何维护?
还有一点,domain 并不能捕捉所有的异常,看这里。
domain 实践
关于使用 domain 到集群环境,推荐都看看官方的说明:Warning: Don’t Ignore Errors!。把每一个网络请求都包在一个 domain 里边,捕获到异常时,不要立即退出进程,应该保证进程中其他连接正常退出之后再 exit,官方推荐的是设一个定时器,过 3min 后退出进程,接下去做善后处理,然后应该返回应该有的错误(如 500)给客户端。
对于 connect 或者 express 创建的 web 服务,有一个 domain-middleware 中间件可以直接用,它会把 next 包装到一个已经定制好的 domain 里边。
在具体应用场景,应该 uncaughtException 事件配合 domain 来用。
本篇完,欢迎补充指正,所有用到的例子都在这里。
参考资料: