计算机网络的相关内容,这部分上过专业课的,只是电院的专业课讲得不是太深,还是需要自己买书重学,这也是前端必备的计算机基础了,这一块内容要背的有点多
1.OSI 7层模型和TCP/IP 4层模型
1.1 OSI
全称是 open system interconnection 开放式系统互联参考模型
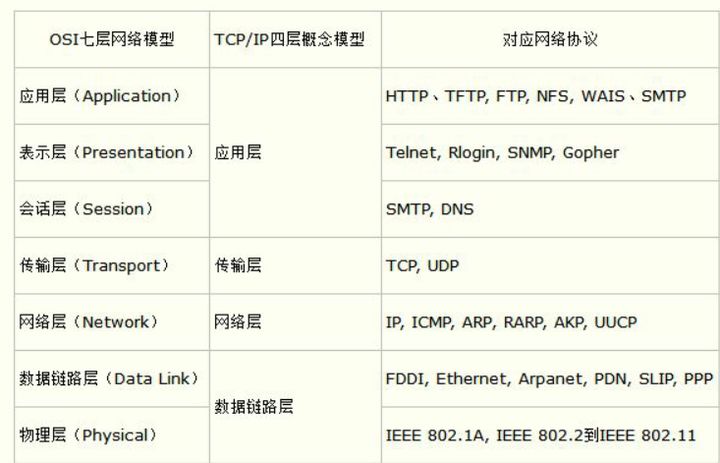
1.1.1 OSI 和TCP/IP 的对应关系和协议
1.1.2 OSI模型各层的基本作用

1.2 OSI模型的详解
OSI的会话层、表示层、应用层合并为TCP/IP的应用层
大纲
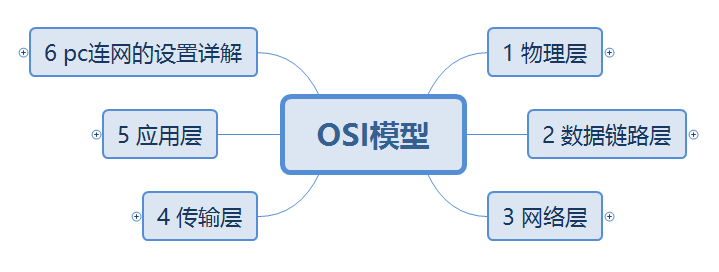
1.2.1 物理层

1.2.2 数据链路层

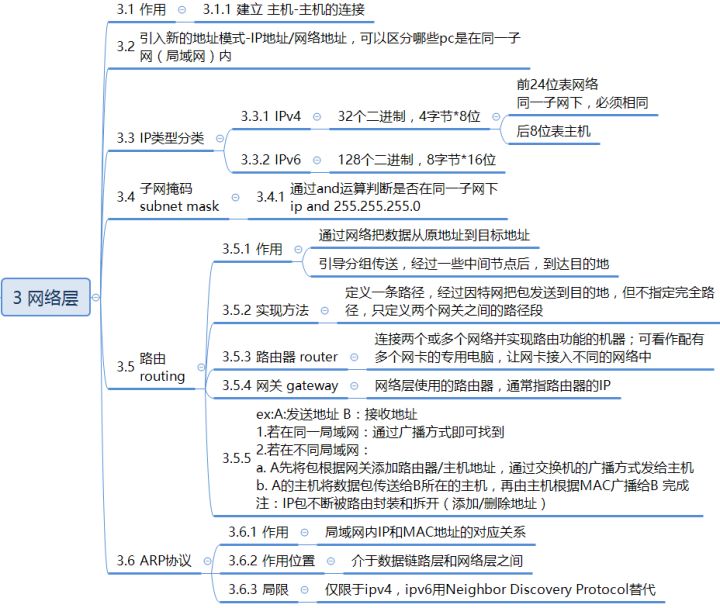
1.2.3 网络层
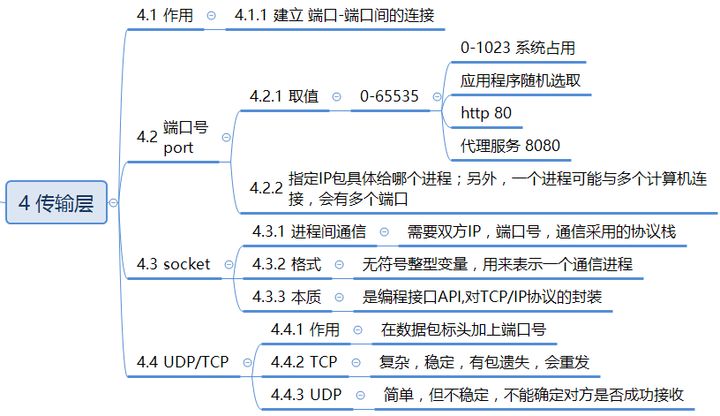
1.2.4 传输层
1.2.5 应用层

1.2.6 补充内容
可以帮助理解
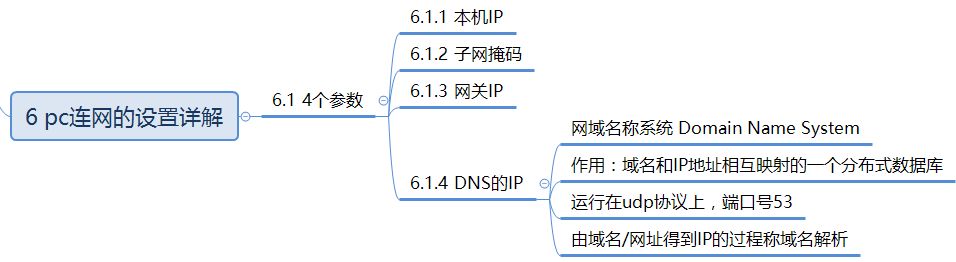
- pc连网的设置详解
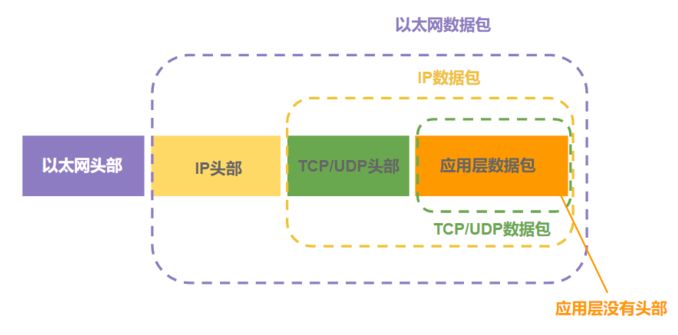
- 数据链路层数据包(以太网数据包)格式,除了应用层没有头部,其他都有
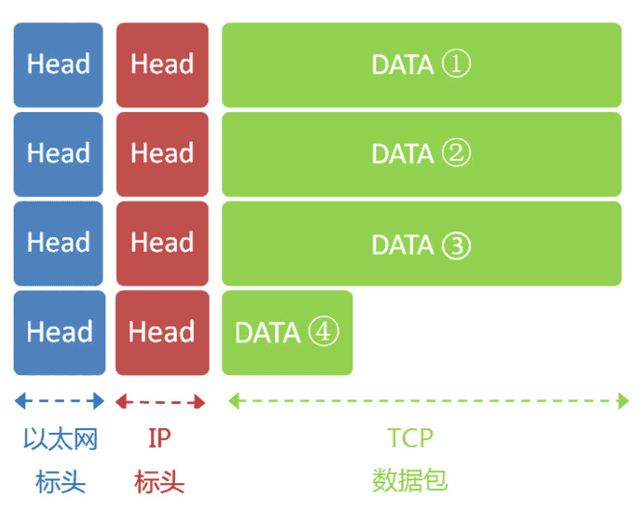
- 由于以太网数据包的数据部分,最大长度为1500字节,当IP包过大时,会分割下来,但是每个分割包的头部都一样
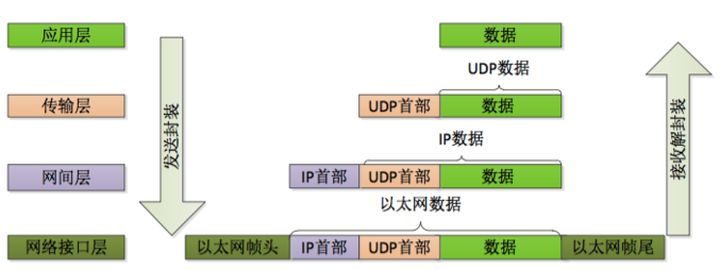
数据包在传送时的封装和解封装如下所示
2.HTTP
HTTP (Hypertext transfer protocol) 翻译成中文是超文本传输协议,是互联网上重要的一个协议,由欧洲核子研究委员会CERN的英国工程师 Tim Berners-Lee v发明的,同时,他也是WWW的发明人,最初的主要是用于传递通过HTML封装过的数据。在1991年发布了HTTP 0.9版,在1996年发布1.0版,1997年是1.1版,1.1版也是到今天为止传输最广泛的版本(初始RFC 2068 在1997年发布, 然后在1999年被 RFC 2616 取代,再在2014年被 RFC 7230 /7231/7232/7233/7234/7235取代),2015年发布了2.0版,其极大的优化了HTTP 1.1的性能和安全性,而2018年发布的3.0版,继续优化HTTP 2.0,激进地使用UDP取代TCP协议,目前,HTTP 3.0 在2019年9月26日 被 Chrome,Firefox,和Cloudflare支持。
2.1 HTTP 0.9 / 1.0
0.9和1.0这两个版本,就是最传统的 request – response的模式了,HTTP 0.9版本的协议简单到极点,请求时,不支持请求头,只支持 GET 方法,HTTP 1.0 扩展了0.9版,其中主要增加了几个变化:
- 在请求中加入了HTTP版本号,如:
GET /coolshell/index.html HTTP/1.0 - HTTP 开始有 header了,不管是request还是response 都有header了。
- 增加了HTTP Status Code 标识相关的状态码。
- 还有
Content-Type可以传输其它的文件了。
我们可以看到,HTTP 1.0 开始让这个协议变得很文明了,一种工程文明。因为:
- 一个协议有没有版本管理,是一个工程化的象征。
- header是协议可以说是把元数据和业务数据解耦,也可以说是控制逻辑和业务逻辑的分离。
- Status Code 的出现可以让请求双方以及第三方的监控或管理程序有了统一的认识。最关键是还是控制错误和业务错误的分离。
(注:国内很多公司HTTP无论对错只返回200,这种把HTTP Status Code 全部抹掉完全是一种工程界的倒退)
但是,HTTP1.0性能上有一个很大的问题,那就是每请求一个资源都要新建一个TCP链接,而且是串行请求,所以,就算网络变快了,打开网页的速度也还是很慢。所以,HTTP 1.0 应该是一个必需要淘汰的协议了。
2.2 HTTP 1.1
HTTP 1.1 主要解决了HTTP 1.0的网络性能的问题,以及增加了一些新的东西:
- 可以设置
keep-alive来让HTTP重用TCP链接,重用TCP链接可以省了每次请求都要在广域网上进行的TCP的三次握手的巨大开销。这是所谓的“HTTP 长链接” 或是 “请求响应式的HTTP 持久链接”。英文叫 HTTP Persistent connection. - 然后支持pipeline网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。(注:非幂等的POST 方法或是有依赖的请求是不能被pipeline化的)
- 支持 Chunked Responses ,也就是说,在Response的时候,不必说明
Content-Length这样,客户端就不能断连接,直到收到服务端的EOF标识。这种技术又叫 “服务端Push模型”,或是 “服务端Push式的HTTP 持久链接” - 还增加了 cache control 机制。
- 协议头注增加了 Language, Encoding, Type 等等头,让客户端可以跟服务器端进行更多的协商。
- 还正式加入了一个很重要的头——
HOST这样的话,服务器就知道你要请求哪个网站了。因为可以有多个域名解析到同一个IP上,要区分用户是请求的哪个域名,就需要在HTTP的协议中加入域名的信息,而不是被DNS转换过的IP信息。 - 正式加入了
OPTIONS方法,其主要用于 CORS – Cross Origin Resource Sharing 应用。
HTTP 1.1应该分成两个时代,一个是2014年前,一个是2014年后,因为2014年HTTP/1.1有了一组RFC(7230 /7231/7232/7233/7234/7235),这组RFC又叫“HTTP/2 预览版”。其中影响HTTP发展的是两个大的需求:
- 一个需要是加大了HTTP的安全性,这样就可以让HTTP应用得广泛,比如,使用TLS协议。
- 另一个是让HTTP可以支持更多的应用,在HTTP/1.1 下,HTTP已经支持四种网络协议:
- 传统的短链接。
- 可重用TCP的的长链接模型。
- 服务端push的模型。
- WebSocket模型。
自从2005年以来,整个世界的应用API越来多,这些都造就了整个世界在推动HTTP的前进,我们可以看到,自2014的HTTP/1.1 以来,这个世界基本的应用协议的标准基本上都是向HTTP看齐了,也许2014年前,还有一些专用的RPC协议,但是2014年以后,HTTP协议的增强,让我们实在找不出什么理由不向标准靠拢,还要重新发明轮子了。
2.3 HTTP 2.0
虽然 HTTP 1.1 已经开始变成应用层通讯协议的一等公民了,但是还是有性能问题,虽然HTTP 1.1 可以重用TCP链接,但是请求还是一个一个串行发的,需要保证其顺序。然而,大量的网页请求中都是些资源类的东西,这些东西占了整个HTTP请求中最多的传输数据量。所以,理论上来说,如果能够并行这些请求,那就会增加更大的网络吞吐和性能。
另外,HTTP 1.1传输数据时,是以文本的方式,借助耗CPU的zip压缩的方式减少网络带宽,但是耗了前端和后端的CPU。这也是为什么很多RPC协议诟病HTTP的一个原因,就是数据传输的成本比较大。
其实,在2010年时,Google 就在搞一个实验型的协议,这个协议叫SPDY,这个协议成为了HTTP 2.0的基础(也可以说成HTTP 2.0就是SPDY的复刻)。HTTP 2.0基本上解决了之前的这些性能问题,其和HTTP 1.1最主要的不同是:
- HTTP 2.0是一个二进制协议,增加了数据传输的效率。
- HTTP 2.0是可以在一个TCP链接中并发请求多个HTTP请求,移除了HTTP 1.1中的串行请求。
- HTTP 2.0会压缩头部,如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。这就是所谓的HPACK算法(参看RFC 7541 附录A)
- HTTP 2.0允许服务端在客户端放cache,又叫服务端push,也就是说,你没有请求的东西,我服务端可以先送给你放在你的本地缓存中。比如,你请求X,我服务端知道X依赖于Y,虽然你没有的请求Y,但我把把Y跟着X的请求一起返回客户端。
对于这些性能上的改善,在Medium上有篇文章你可看一下相关的细节说明和测试“HTTP/2: the difference between HTTP/1.1, benefits and how to use it”
HTTP 2 是2015年推出的,其发布后,Google 宣布移除对SPDY的支持,拥抱标准的 HTTP/2。过了一年后,就有8.7%的网站开启了HTTP 2.0,根据 这份报告 ,截止至2021年5月18日, 在全世界范围内已经有46.6%的网站开启了HTTP 2.0。
HTTP 2.0的官方组织在 Github 上维护了一份各种语言对HTTP 2.0的实现列表,大家可以去看看。
我们可以看到,HTTP 在性能上对HTTP有质的提高,所以,HTTP 2.0被采用的也很快,所以,如果你在你的公司内负责架构的话,HTTP 2.0是你一个非常重要的需要推动的一个事,除了因为性能上的问题,推动标准落地也是架构师的主要职责,因为,你企业内部的架构越标准,你可以使用到开源软件,或是开发方式就会越有效率,跟随着工业界的标准的发展,你的企业会非常自然的享受到标准所带来的红利。
2.4 HTTP 3.0
然而,这个世界没有完美的解决方案,HTTP 2.0也不例外,其主要的问题是:若干个HTTP的请求在复用一个TCP的连接,底层的TCP协议是不知道上层有多少个HTTP的请求的,所以,一旦发生丢包,造成的问题就是所有的HTTP请求都必需等待这个丢了的包被重传回来,哪怕丢的那个包不是我这个HTTP请求的。因为TCP底层是没有这个知识了。
这个问题又叫Head-of-Line Blocking问题,这也是一个比较经典的流量调度的问题。这个问题最早主要的发生的交换机上。下图来自Wikipedia。
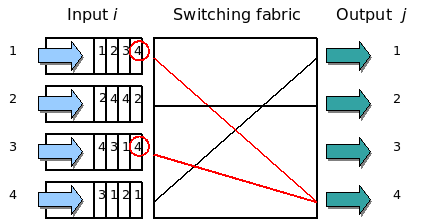
图中,左边的是输入队列,其中的1,2,3,4表示四个队列,四个队列中的1,2,3,4要去的右边的output的端口号。此时,第一个队列和第三个队列都要写右边的第四个端口,然后,一个时刻只能处理一个包,所以,一个队列只能在那等另一个队列写完后。然后,其此时的3号或1号端口是空闲的,而队列中的要去1和3号端号的数据,被第四号端口给block住了。这就是所谓的HOL blocking问题。
HTTP 1.1中的pipeline中如果有一个请求block了,那么队列后请求也统统被block住了;HTTP 2.0多请求复用一个TCP连接,一旦发生丢包,就会block住所有的HTTP请求。这样的问题很讨厌。好像基本无解了。
是的TCP是无解了,但是UDP是有解的 !于是HTTP 3.0破天荒地把HTTP底层的TCP协议改成了UDP!
然后又是Google 家的协议进入了标准 – QUIC (Quick UDP Internet Connections)。接下来是QUIC协议的几个重要的特性,为了讲清楚这些特性,我需要带着问题来讲(注:下面的网络知识,如果你看不懂的话,你需要学习一下《TCP/IP详解》一书,或是看一下本站的《TCP的那些事》。):
- 首先是上面的Head-of-Line blocking问题,在UDP的世界中,这个就没了。这个应该比较好理解,因为UDP不管顺序,不管丢包(当然,QUIC的一个任务是要像TCP的一个稳定,所以QUIC有自己的丢包重传的机制)
- TCP是一个无私的协议,也就是说,如果网络上出现拥塞,大家都会丢包,于是大家都会进入拥塞控制的算法中,这个算法会让所有人都“冷静”下来,然后进入一个“慢启动”的过程,包括在TCP连接建立时,这个慢启动也在,所以导致TCP性能迸发地比较慢。QUIC基于UDP,使用更为激进的方式。同时,QUIC有一套自己的丢包重传和拥塞控制的协,一开始QUIC是重新实现一TCP 的 CUBIC算法,但是随着BBR算法的成熟(BBR也在借鉴CUBIC算法的数学模型),QUIC也可以使用BBR算法。这里,多说几句,从模型来说,以前的TCP的拥塞控制算法玩的是数学模型,而新型的TCP拥塞控制算法是以BBR为代表的测量模型,理论上来说,后者会更好,但QUIC的团队在一开始觉得BBR不如CUBIC的算法好,所以没有用。现在的BBR 2.x借鉴了CUBIC数学模型让拥塞控制更公平。这里有文章大家可以一读“TCP BBR : Magic dust for network performance.”
- 接下来,现在要建立一个HTTPS的连接,先是TCP的三次握手,然后是TLS的三次握手,要整出六次网络交互,一个链接才建好,虽说HTTP 1.1和HTTP 2.0的连接复用解决这个问题,但是基于UDP后,UDP也得要实现这个事。于是QUIC直接把TCP的和TLS的合并成了三次握手(对此,HTTP 2.0是否默认开启TLS业内是有争议的,反对派说,TLS在一些情况下是不需要的,比如企业内网的时候,而支持派则说,TLS的那些开销,什么也不算了)。
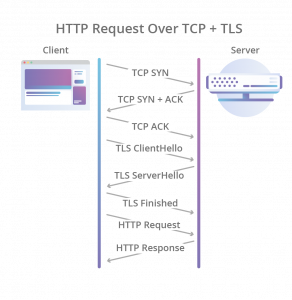 |
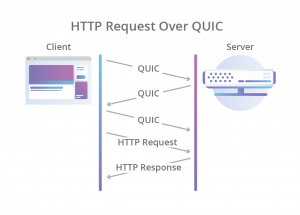 |
|---|---|
所以,QUIC是一个在UDP之上的伪TCP +TLS +HTTP 2.0的多路复用的协议。
但是对于UDP还是有一些挑战的,这个挑战主要来自互联网上的各种网络设备,这些设备根本不知道是什么QUIC,他们看QUIC就只能看到的就是UDP,所以,在一些情况下,UDP就是有问题的,
比如在NAT的环境下,如果是TCP的话,NAT路由或是代理服务器,可以通过记录TCP的四元组(源地址、源端口,目标地址,目标端口)来做连接映射的,然而,在UDP的情况下不行了。于是,QUIC引入了个叫connection id的不透明的ID来标识一个链接,用这种业务ID很爽的一个事是,如果你从你的3G/4G的网络切到WiFi网络(或是反过来),你的链接不会断,因为我们用的是connection id,而不是四元组。
然而就算引用了connection id,也还是会有问题 ,比如一些不够“聪明”的等价路由交换机,这些交换机会通过四元组来做hash把你的请求的IP转到后端的实际的服务器上,然而,他们不懂connection id,只懂四元组,这么导致属于同一个connection id但是四元组不同的网络包就转到了不同的服务器上,这就是导致数据不能传到同一台服务器上,数据不完整,链接只能断了。所以,你需要更聪明的算法(可以参看 Facebook 的 Katran 开源项目 )
好了,就算搞定上面的东西,还有一些业务层的事没解,这个事就是 HTTP 2.0的头压缩算法 HPACK,HPACK需要维护一个动态的字典表来分析请求的头中哪些是重复的,HPACK的这个数据结构需要在encoder和decoder端同步这个东西。在TCP上,这种同步是透明的,然而在UDP上这个事不好干了。所以,这个事也必需要重新设计了,基于QUIC的QPACK就出来了,利用两个附加的QUIC steam,一个用来发送这个字典表的更新给对方,另一个用来ack对方发过来的update。
目前看下来,HTTP 3.0目前看上去没有太多的协议业务逻辑上的东西,更多是HTTP 2.0 + QUIC协议。但,HTTP 3.0因为动到了底层协议,所以,在普及方面上可能会比 HTTP 2要慢的多的多。
3.HTTPS
引言
HTTP是不安全的,只需要设定相应的DNS,做一个中间人攻击,再将修改后的数据返回,可能泄露用户隐私数据。然而,当我们切换HTTPS时候,服务端认证不通过,浏览器不会展示相应的页面数据;运营商实施搞的这一套东东也就不能在用户不知情的情况下搞起来了,解决办法是去除相应的受污染的DNS。
3.1 安全的HTTP的需求
对HTTP的安全需求:
- 加密(客户端和服务器的对话是私密的,无须担心被窃听)
- 服务端认证(客户端知道它们是在与真正的而不是伪造的服务器通信)
- 客户端认证(服务器知道它们是在与真正的而不是伪造的客户端通信)
- 完整性(客户端和服务器的数据不会被修改)
- 效率(一个运行足够快的算法,一遍低端的客户端和服务器使用)
- 普适性(基本上所有的客户端和服务器都支持这些协议)
- 管理的可扩展性(在任何地方的任何人都可以立即进行安全通信)
- 适应性(能够支持当前最知名的安全方法)
- 在社会上的可行性(满足社会的政治文化需要),要有公众受信能力
在这里面最重要的是前面几条
- 数据加密 传输内容进行混淆
- 身份验证 通信双方验证对方的身份真实性
- 数据完整性保护 检测传输的内容是否被篡改或伪造
3.2 安全HTTP的实现
3.2.1 加密方式的选择
共享密钥加密 对称密钥加密
共享密钥加密方式使用相同的密钥进行加密解密,通信双方都需要接收对方的加密密钥进行数据解密,这种方式在通信过程中必须交互共享的密钥,同样无法避免被网络监听泄漏密钥的问题;同时对于众多客户端的服务器来说还需要分配和管理密钥,对于客户端来说也需要管理密钥,增加设计和实现的复杂度,同时也降低了通信的效率;不用看都不靠谱。
公开密钥加密
公开密钥加密方式使用一对非对称的密钥对(私钥和公钥),不公开的作为私钥,随意分发的作为公钥;公钥和私钥都能进行数据加密和解密,公钥能解密私钥加密的数据,私钥也能解密公钥加密的数据;这样只需要一套密钥就能处理服务端和众多客户端直接的通信被网络监听泄漏密钥的问题,同时没有额外的管理成本;看起来挺合适。
没那么简单
公开密钥加密安全性高,伴随着加密方式复杂,处理速度慢的问题。如果我们的通信都是用公开密钥的方式加密,那么通信效率会很低。
HTTPS采用共享密钥加密和公开密钥加密混合的加密方式,在交换密钥对环节使用公开密钥加密方式(防止被监听泄漏密钥)加密共享的密钥,在随后的通信过程中使用共享密钥的方式使用共享的密钥进行加解密。
3.2.2 认证方式实现
数字证书
数字签名是附加在报文上的特殊加密校验码,可以证明是作者编写了这条报文,前提是作者才会有私钥,才能算出这些校验码。如果传输的报文被篡改,则校验码不会匹配,因为校验码只有作者保存的私钥才能产生,所以前面可以保证报文的完整性。
数字证书认证机构(Certificate Authority CA)是客户端和服务器双方都可信赖的第三方机构。
服务器的运营人员向数字证书认证机构提出证书认证申请,数字证书认证机构在判明申请者的身份之后,会对已申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将该公开密钥放入公钥证书(也叫数字证书或证书)后绑定在一起。服务器将这份有数字认证机构颁发的公钥证书发总给客户端,以进行公开密钥加密方式通信。
EV SSL(Extended Validation SSL Certificate)证书是基于国际标准的认证指导方针办法的证书,通过认证的Web网站能获得更高的认可度。持有EV SSL证书的Web网站的浏览器地址栏的背景色是绿色的,同时在地址栏的左侧显示了SSL证书中记录的组织名称及办法证书的认证机构的名称。
使用OpenSSL,每个人都可以构建一套认证机构文件,同时可以用来给自己的证书请求进行签名,这种方式产生的证书称为自签名证书,这种证书通常是CA自己的证书,用户开发测试的正式,也可以像12306这样的,信不信由你。
证书信任的方式
操作系统和浏览器内置
每个操作系统和大多数浏览器都会内置一个知名证书颁发机构的名单。因此,你也会信任操作系统及浏览器提供商提供和维护的可信任机构。
受信认证机构(也有不受信的,比如赛门铁克,沃通,或者像2011年被入侵的DigiNotar等)的证书一般会被操作系统或者浏览器在发行或者发布时内置。
证书颁发机构
CA( Certificate Authority,证书颁发机构)是被证书接受者(拥有者)和依赖证书的一方共同信任的第三方。
手动指定证书
所有浏览器和操作系统都提供了一种手工导入信任证书的机制。至于如何获得证书和验证完整性则完全由你自己来定。
PKI(Public Key Infrastructure),即公开密钥基础设施,是国际上解决开放式互联网络信息安全需求的一套体系。PKI支持身份认证,信息传输,存储的完整性,消息传输,存储的机密性以及操作的不可否认性。
3.2.3 数据完整性
数字签名是只有信息发送者才能产生的别人无法伪造的一段文本,这段文本是对信息发送者发送信息真实性的一个有效证明,具有不可抵赖性。
报文的发送方从报文文本生成一个128位的散列值(或称为报文摘要活哈希值),发送方使用自己的私钥对这个摘要值进行加密来形成发送方的数字签名。然后这个数字签名将作为报文的附件一起发送给报文的接收方。报文的接收方首先从接收到的原始报文中计算出128位的散列值,再用发送方的公钥来对报文附加的数字签名进行解密。如果两次得到的结果是一致的那么接收方可以确认该数字签名是发送方的,同时确认信息是真实的 。
3.3 HTTPS数据交互过程
HTTP中没有加密机制,可以通过SSL(Secure Socket Layer 安全套接层)或TLS(Transport Layer Security 安全层传输协议)的组合使用,加密HTTP的通信内容。
HTTPS是 HTTP Secure 或 HTTP over SSL。
SSL(Security Socket Layer)是最初由网景公司(NetScape)为了保障网上交易安全而开发的协议,该协议通过加密来保护客户个人资料,通过认证和完整性检查来确保交易安全。网景公司开发过SSL3.0之前的版本;目前主导权已转移给IETF(Internet Engineering Task Force),IETF以SSL3.0为原型,标准化并制定了TSL1.0,TLS1.1,TLS1.2。但目前主流的还是SSL3.0和TSL1.0。
SSL工作在OSI七层模型中的表示层,TCP/IP 四层模型的应用层。
SSL 和 TLS 可以作为基础协议的一部分(对应用透明),也可以嵌入在特定的软件包中(比如Web服务器中的实现)。
SSL 基于TCP,SSL不是简单地单个协议,而是两层协议;SSL记录协议(SSL Record Protocol)为多种高层协议(SSL握手协议,SSL修改密码参数协议,SSL报警协议)提供基本的安全服务。HTTP是为Web客户端/服务器交互提供传输服务的,它可以在SSL的顶层运行;SSL记录协议为SSL链接提供两种服务,机密性:握手协议定义了一个共享密钥,用于SSL载荷的对称加密。 消息完整性:握手协议还定义了一个共享密钥,它用来产生一个消息认证码(Message Authentication Code,MAC)。
3.3.1 SSL记录协议操作
- 分段 将每个上层消息分解成不大于2^14(16384)位,然后有选择的进行压缩
- 添加MAC 在压缩数据的基础上计算MAC
- 加密 消息加上MAC用对称加密方法加密
- 添加SSL记录头 内容类型(8位),主版本(8位),副版本(8位),压缩长度(16位)
3.3.2 SSL握手过程
- 第一阶段 建立安全能力 包括协议版本 会话Id 密码构件 压缩方法和初始随机数
- 第二阶段 服务器发送证书 密钥交换数据和证书请求,最后发送请求-相应阶段的结束信号
- 第三阶段 如果有证书请求客户端发送此证书 之后客户端发送密钥交换数据 也可以发送证书验证消息
- 第四阶段 变更密码构件和结束握手协议
SSL协议两个重要概念,SSL会话,SSL连接;SSL连接是点到点的连接,而且每个连接都是瞬态的,每一个链接都与一个会话关联。SSL会话是一个客户端和一个服务器之间的一种关联,会话由握手协议(Handshake Protocol)创建,所有会话都定义了一组密码安全参数,这些安全参数可以在多个连接之间共享,会话可以用来避免每一个链接需要进行的代价高昂的新的安全参数协商过程。
1 | Client Server |
参考资料
- 《深入理解HTTPS原理、过程与实践》
- 《Web性能权威指南》
- 《RFC 2246》
- 《图解HTTP》
- 《HTTP权威指南》
- 《HTTPS权威指南 在服务器和Web应用上部署SSL/TLS和PKI》
- 《计算机网络系统方法》
- 《计算机网络自上而下方法》
- 《计算机安全原理与实践》
- 《网络安全基础-应用与标准》
- 《PKI/CA与数字证书技术大全》
- 《SSL与TLS》
- 《OpenSSL官方命令文档》
- 《OpenSSL与网络信息安全-基础、结构和指令》
- 《OpenSSL攻略》
- Wireshark Doc SSL
4.HTTP 2.0
导读
HTTP 2.0是一种安全高效的下一代http传输协议。安全是因为HTTP 2.0建立在HTTPS协议的基础上,高效是因为它是通过二进制分帧来进行数据传输。正因为这些特性,HTTP 2.0协议也在被越来越多的网站支持。
4.1 什么是HTTP 2.0协议?
在HTTP 2.0官网①的描述是:
http/2 is a replacement for how http is expressed “on the wire.” It is not a ground-up rewrite of the protocol; http methods, status codes and semantics are the same, and it should be possible to use the same APIs as http/1.x (possibly with some small additions) to represent the protocol.
The focus of the protocol is on performance; specifically, end-user perceived latency, network and server resource usage. One major goal is to allow the use of a single connection from browsers to a Web site.
The basis of the work was SPDY, but http/2 has evolved to take the community’s input into account, incorporating several improvements in the process.
中文总结一下就是:
4.1.1 对1.x协议语意的完全兼容
2.0协议是在1.x基础上的升级而不是重写,1.x协议的方法,状态及api在2.0协议里是一样的。
4.1.2 性能的大幅提升
2.0协议重点是对终端用户的感知延迟、网络及服务器资源的使用等性能的优化。
4.2 HTTP 2.0优化内容
4.2.1 二进制分帧(Binary Format)- HTTP 2.0的基石
HTTP 2.0之所以能够突破http1.X标准的性能限制,改进传输性能,实现低延迟和高吞吐量,就是因为其新增了二进制分帧层。
帧(frame)包含部分:类型Type, 长度Length, 标记Flags, 流标识Stream和frame payload有效载荷。
消息(message):一个完整的请求或者响应,比如请求、响应等,由一个或多个 Frame 组成。
流是连接中的一个虚拟信道,可以承载双向消息传输。每个流有唯一整数标识符。为了防止两端流ID冲突,客户端发起的流具有奇数ID,服务器端发起的流具有偶数ID。
流标识是描述二进制frame的格式,使得每个frame能够基于HTTP 2.0发送,与流标识联系的是一个流,每个流是一个逻辑联系,一个独立的双向的frame存在于客户端和服务器端之间的HTTP 2.0连接中。一个HTTP 2.0连接上可包含多个并发打开的流,这个并发流的数量能够由客户端设置。
在二进制分帧层上,HTTP 2.0会将所有传输信息分割为更小的消息和帧,并对它们采用二进制格式的编码将其封装,新增的二进制分帧层同时也能够保证http的各种动词,方法,首部都不受影响,兼容上一代http标准。其中,HTTP 1.X中的首部信息header封装到Headers帧中,而request body将被封装到Data帧中。
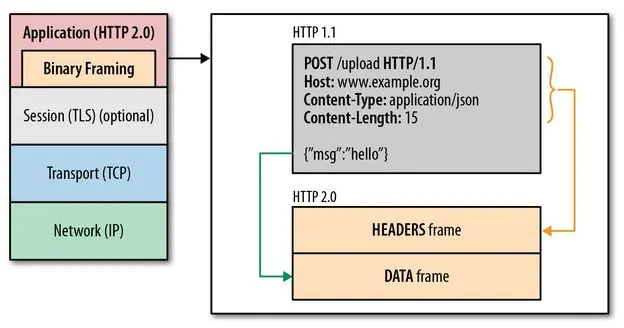
4.2.2 多路复用 (Multiplexing) / 连接共享
在HTTP 1.1中,浏览器客户端在同一时间,针对同一域名下的请求有一定数量的限制,超过限制数目的请求会被阻塞。这也是为何一些站点会有多个静态资源 CDN 域名的原因之一。
而HTTP 2.0中的多路复用优化了这一性能。多路复用允许同时通过单一的HTTP 2.0连接发起多重的请求-响应消息。有了新的分帧机制后,HTTP 2.0不再依赖多个TCP连接去实现多流并行了。每个数据流都拆分成很多互不依赖的帧,而这些帧可以交错(乱序发送),还可以分优先级,最后再在另一端把它们重新组合起来。
HTTP 2.0连接都是持久化的,而且客户端与服务器之间也只需要一个连接(每个域名一个连接)即可。http2连接可以承载数十或数百个流的复用,多路复用意味着来自很多流的数据包能够混合在一起通过同样连接传输。当到达终点时,再根据不同帧首部的流标识符重新连接将不同的数据流进行组装。
上图展示了一个连接上的多个传输数据流:客户端向服务端传输数据帧stream5,同时服务端向客户端乱序发送stream1和stream3。这次连接上有三个响应请求乱序并行交换。
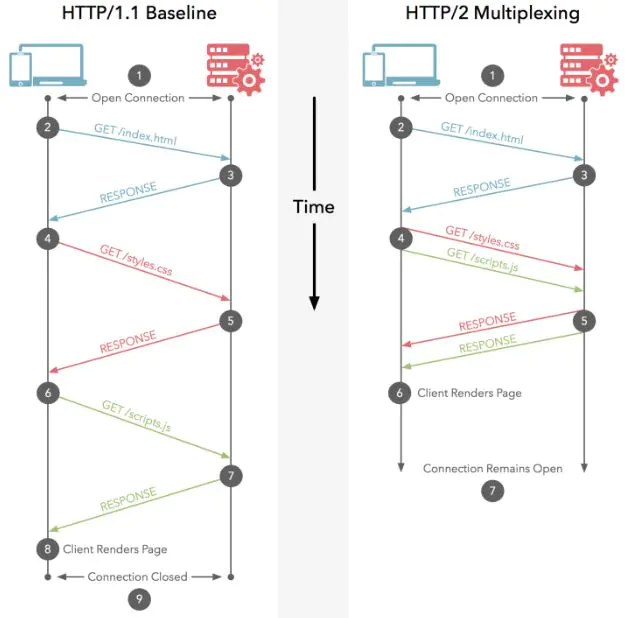
上图就是HTTP 1.X和HTTP 2.0在传输数据时的区别。以货物运输为例再现http1.1与HTTP 2.0的场景:
HTTP 1.1过程:货轮1从A地到B地去取货物,取到货物后,从B地返回,然后货轮2在A返回并卸下货物后才开始再从A地出发取货返回,如此有序往返。
HTTP 2.0过程:货轮1、2、3、4、5从A地无序全部出发,取货后返回,然后根据货轮号牌卸载对应货物。
显然,第二种方式运输货物多,河道的利用率高。
4.2.3 头部压缩(Header Compression)
HTTP 1.x的头带有大量信息,而且每次都要重复发送。HTTP 2.0使用encoder来减少需要传输的header大小,通讯双方各自缓存一份头部字段表,既避免了重复header的传输,又减小了需要传输的大小。
对于相同的数据,不再通过每次请求和响应发送,通信期间几乎不会改变通用键-值对(用户代理、可接受的媒体类型,等等)只需发送一次。
事实上,如果请求中不包含首部(例如对同一资源的轮询请求),那么,首部开销就是零字节,此时所有首部都自动使用之前请求发送的首部。
如果首部发生了变化,则只需将变化的部分加入到header帧中,改变的部分会加入到头部字段表中,首部表在 HTTP 2.0的连接存续期内始终存在,由客户端和服务器共同渐进地更新。
需要注意的是,HTTP 2.0关注的是首部压缩,而我们常用的gzip等是报文内容(body)的压缩,二者不仅不冲突,且能够一起达到更好的压缩效果。
HTTP 2.0使用的是专门为首部压缩而设计的HPACK②算法。

从上图可以看到HTTP 1.X不支持首部压缩,而HTTP 2.0的压缩算法效果最好,发送和接受的数据量都是最少的。
4.2.4 压缩原理
用header字段表里的索引代替实际的header。
HTTP 2.0的HPACK算法使用一份索引表来定义常用的HTTP Header,把常用的 HTTP Header 存放在表里,请求的时候便只需要发送在表里的索引位置即可。
例如 :method=GET 使用索引值 2 表示,:path=/index.html 使用索引值 5 表示,如下图:
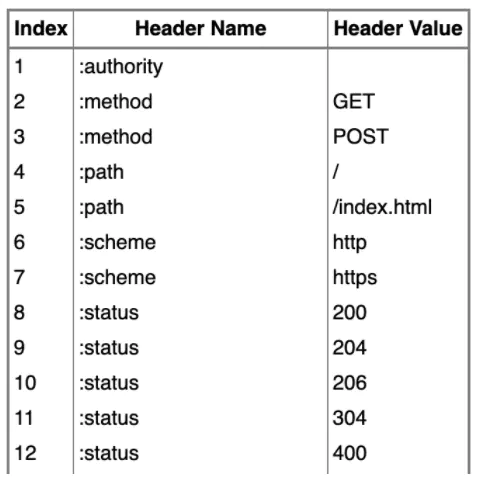
完整的列表参考:HPACK Static Table③ 。
只要给服务端发送一个 Frame,该 Frame 的 Payload 部分存储 0x8285,Frame 的 Type 设置为 Header 类型,便可表示这个 Frame 属于 http Header,请求的内容是:
1 | 1GET /index.html |
为什么是 0x8285,而不是 0x0205?这是因为高位设置为 1 表示这个字节是一个完全索引值(key 和 value 都在索引中)。
类似的,通过高位的标志位可以区分出这个字节是属于一个完全索引值,还是仅索引了 key,还是 key和value 都没有索引。
因为索引表的大小的是有限的,它仅保存了一些常用的 HTTP Header,同时每次请求还可以在表的末尾动态追加新的 HTTP Header 缓存,动态部分称之为 Dynamic Table。Static Table 和 Dynamic Table 在一起组合成了索引表:

HPACK 不仅仅通过索引键值对来降低数据量,同时还会将字符串进行霍夫曼编码来压缩字符串大小。
以常用的 User-Agent 为例,它在静态表中的索引值是 58,它的值是不存在表中的,因为它的值是多变的。第一次请求的时候它的 key 用 58 表示,表示这是一个 User-Agent ,它的值部分会进行霍夫曼编码(如果编码后的字符串变更长了,则不采用霍夫曼编码)。
服务端收到请求后,会将这个 User-Agent 添加到 Dynamic Table 缓存起来,分配一个新的索引值。客户端下一次请求时,假设上次请求User-Agent的在表中的索引位置是 62, 此时只需要发送 0xBE(同样的,高位置 1),便可以代表:User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36。
其过程如下图所示:
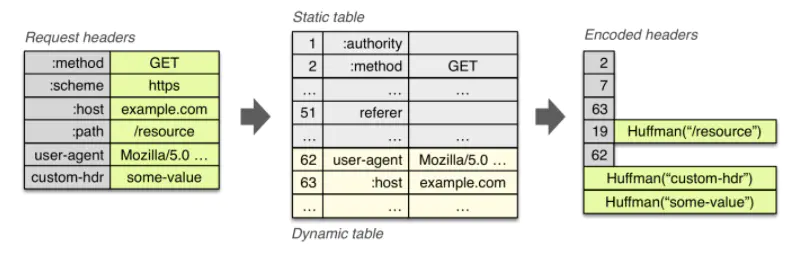
最终,相同的 Header 只需要发送索引值,新的 Header 会重新加入 Dynamic Table。
4.2.5 请求优先级(Request Priorities)
把HTTP消息分为很多独立帧之后,就可以通过优化这些帧的交错和传输顺序进一步优化性能。每个流都可以带有一个31比特的优先值:0 表示最高优先级;2的31次方-1 表示最低优先级。
服务器可以根据流的优先级,控制资源分配(CPU、内存、带宽),而在响应数据准备好之后,优先将最高优先级的帧发送给客户端。高优先级的流都应该优先发送,但又不会绝对的。绝对地准守,可能又会引入首队阻塞的问题:高优先级的请求慢导致阻塞其他资源交付。
分配处理资源和客户端与服务器间的带宽,不同优先级的混合也是必须的。客户端会指定哪个流是最重要的,有一些依赖参数,这样一个流可以依赖另外一个流。优先级别可以在运行时动态改变,当用户滚动页面时,可以告诉浏览器哪个图像是最重要的,你也可以在一组流中进行优先筛选,能够突然抓住重点流。
●优先级最高:主要的html
●优先级高:CSS文件
●优先级中:js文件
●优先级低:图片
4.2.6 服务端推送(Server Push)
服务器可以对一个客户端请求发送多个响应,服务器向客户端推送资源无需客户端明确地请求。并且,服务端推送能把客户端所需要的资源伴随着index.html一起发送到客户端,省去了客户端重复请求的步骤。
正因为没有发起请求,建立连接等操作,所以静态资源通过服务端推送的方式可以极大地提升速度。Server Push 让 HTTP 1.x 时代使用内嵌资源的优化手段变得没有意义;如果一个请求是由你的主页发起的,服务器很可能会响应主页内容、logo 以及样式表,因为它知道客户端会用到这些东西,这相当于在一个 HTML 文档内集合了所有的资源。
不过与之相比,服务器推送还有一个很大的优势:可以缓存!也让在遵循同源的情况下,不同页面之间可以共享缓存资源成为可能。
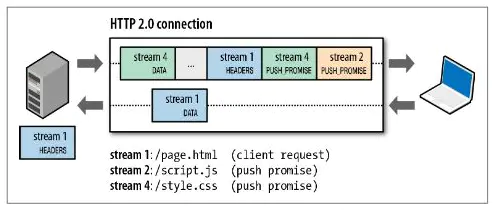
注意两点:
1、推送遵循同源策略;
2、这种服务端的推送是基于客户端的请求响应来确定的。
当服务端需要主动推送某个资源时,便会发送一个 Frame Type 为 PUSH_PROMISE 的 Frame,里面带了 PUSH 需要新建的 Stream ID。意思是告诉客户端:接下来我要用这个 ID 向你发送东西,客户端准备好接着。客户端解析 Frame 时,发现它是一个 PUSH_PROMISE 类型,便会准备接收服务端要推送的流。
4.3 HTTP 2.0性能瓶颈
启用HTTP 2.0后会给性能带来很大的提升,但同时也会带来新的性能瓶颈。因为现在所有的压力集中在底层一个TCP连接之上,TCP很可能就是下一个性能瓶颈,比如TCP分组的队首阻塞问题,单个TCP packet丢失导致整个连接阻塞,无法逃避,此时所有消息都会受到影响。未来,服务器端针对HTTP 2.0下的TCP配置优化至关重要。
4.3.1 如何升级HTTP 2.0协议
nginx服务器升级HTTP 2.0协议需要满足如下条件:
1、nginx版本高于1.9.5;
2、–with-http_ssl_module 跟 –with-http_v2_module
–with-http_ssl_module模块是因为HTTP 2.0协议是一种HTTPS协议。
4.3.2 查看你的nginx配置
1 | nginx -V |

这个是已经添加了对应模块。没有这两个模块的需要手动编译安装。
4.3.3 找到nginx文件目录
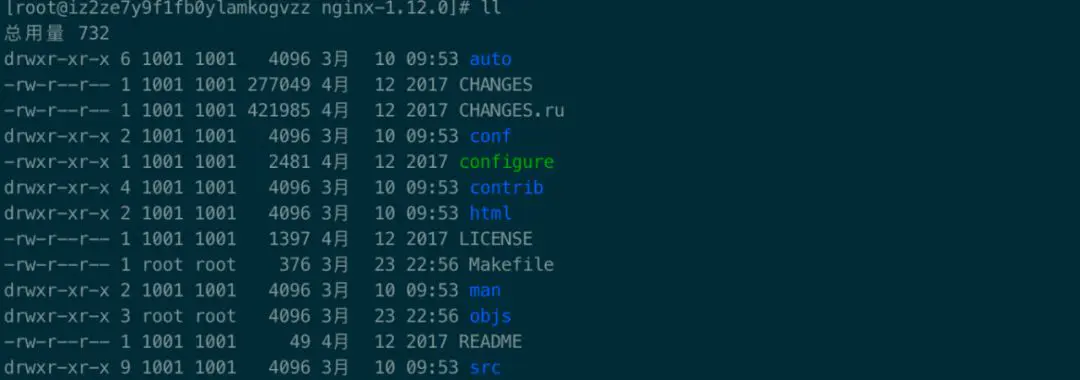
4.3.4 编译安装nginx文件
1 | 1./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module --with-http_v2_module |
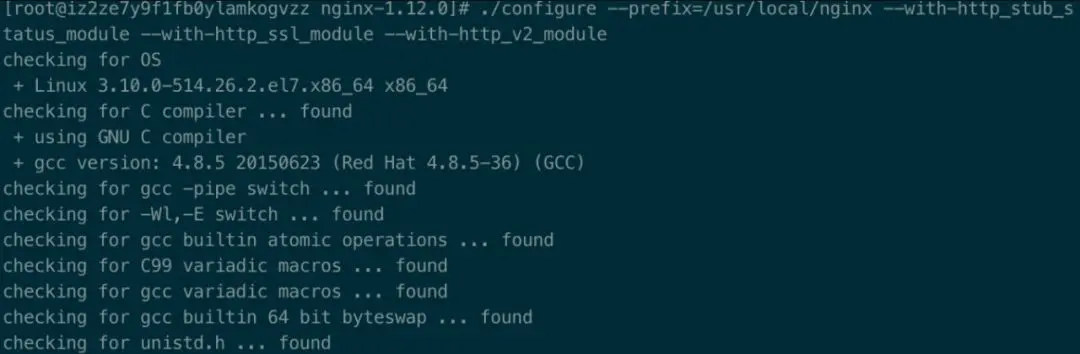
然后执行如下命令,进行编译安装。
1 | 1make2make install |
4.3.5 更改nginx配置
安装结束后将nginx.config文件中443端口添加HTTP 2.0

4.3.6 启动nginx
最后一步,重启nginx nginx restart(注意不要直接 nginx -s reload )。这时候你的站点就升级为了HTTP 2.0协议了。
检测
升级完成后,怎么确定自己的站点是HTTP 2.0协议呢?一般有如下几种方法:
chrome devtool
打开chrome调试工具,在network勾选protocol项,h2代表的是HTTP 2.0协议;
网站
SSL lab⑤ 一个SSL服务器检测的网站,对网站进行安全评级,并将检测结果自动生成一个详细的评价报告;
插件
http/2 and SPDY indicator 这是一款检测HTTP 2.0和SPDY协议(Google开发的基于TCP的会话层协议)的插件。
参考资料:
[2].http://http2.github.io/http2-spec/compression.html
[3].http://http2.github.io/http2-spec/compression.html#rfc.section.A
[4].https://neyoufan.github.io/2017/01/06/android/OkHttp3中的HTTP2首部压缩
[5].https://www.ssllabs.com/ssltest/analyze.html
5.HTTP 3.0
写在前面
如果你的 App,在不需要任何修改的情况下就能提升 15% 以上的访问速度。特别是弱网络的时候能够提升 20% 以上的访问速度。
如果你的 App,在频繁切换 4G 和 WIFI 网络的情况下,不会断线,不需要重连,用户无任何感知。如果你的 App,既需要 TLS 的安全,也想实现 HTTP 2.0 多路复用的强大。
如果你刚刚才听说 HTTP 2.0 是下一代互联网协议,如果你刚刚才关注到 TLS1.3 是一个革命性具有里程碑意义的协议,但是这两个协议却一直在被另一个更新兴的协议所影响和挑战。
5.1 HTTP 2.0和HTTP 3.0
我们都知道互联网中业务是不断迭代前进的,像HTTP这种重要的网络协议也是如此,新版本是对旧版本的扬弃。
5.1.1 HTTP 2.0和TCP的爱恨纠葛
HTTP 2.0是2015年推出的,还是比较年轻的,其重要的二进制分帧协议、多路复用、头部压缩、服务端推送等重要优化使HTTP协议真正上了一个新台阶。
像谷歌这种重要的公司并没有满足于此,而且想继续提升HTTP的性能,花最少的时间和资源获取极致体验。
HTTP 2.0有什么不足吗? 建立连接时间长(本质上是TCP的问题) ,队头阻塞问题,移动互联网领域表现不佳(弱网环境) …
这些缺点基本都是由于TCP协议引起的,水能载舟亦能覆舟,其实TCP也很无辜呀!

在我们眼里,TCP是面向连接、可靠的传输层协议,当前几乎所有重要的协议和应用都是基于TCP来实现的。
网络环境的改变速度很快,但是TCP协议相对缓慢,正是这种矛盾促使谷歌做出了一个看似出乎意料的决定-基于UDP来开发新一代HTTP协议。
5.1.2 谷歌为什么选择UDP
上面提到,谷歌选择UDP是看似出乎意料的,仔细想一想其实很有道理。
我们单纯地看看TCP协议的不足和UDP的一些优点:
基于TCP开发的设备和协议非常多,兼容困难
TCP协议栈是Linux内部的重要部分,修改和升级成本很大
UDP本身是无连接的、没有建链和拆链成本
UDP的数据包无队头阻塞问题
UDP改造成本小
从上面的对比可以知道,谷歌要想从TCP上进行改造升级绝非易事,但是UDP虽然没有TCP为了保证可靠连接而引发的问题,但是UDP本身不可靠,又不能直接用
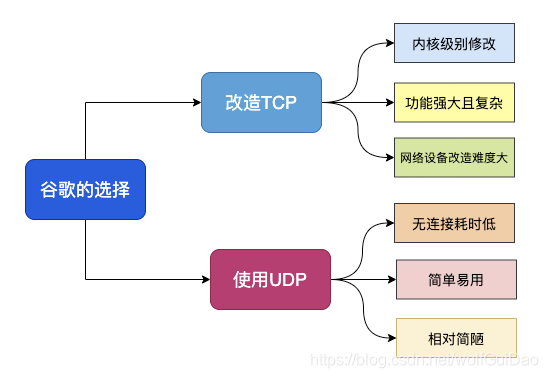
综合而知,谷歌决定在UDP基础上改造一个具备TCP协议优点的新协议也就顺理成章了,这个新协议就是QUIC协议。
5.1.3 QUIC协议和HTTP 3.0
QUIC其实是Quick UDP Internet Connections的缩写,直译为快速UDP互联网连接。

我们来看看维基百科对于QUIC协议的一些介绍:
QUIC协议最初由Google的Jim Roskind设计,实施并于2012年部署,在2013年随着实验的扩大而公开宣布,并向IETF进行了描述。
QUIC提高了当前正在使用TCP的面向连接的Web应用程序的性能。它在两个端点之间使用用户数据报协议(UDP)建立多个复用连接来实现此目的。
QUIC的次要目标包括减少连接和传输延迟,在每个方向进行带宽估计以避免拥塞。它还将拥塞控制算法移动到用户空间,而不是内核空间,此外使用前向纠错(FEC)进行扩展,以在出现错误时进一步提高性能。
HTTP3.0又称为HTTP Over QUIC,其弃用TCP协议,改为使用基于UDP协议的QUIC协议来实现。

5.2 QUIC详解
择其善者而从之,其不善者而改之。
HTTP 3.0既然选择了QUIC协议,也就意味着HTTP3.0基本继承了HTTP2.0的强大功能,并且进一步解决了HTTP 2.0存在的一些问题,同时必然引入了新的问题
QUIC协议必须要实现HTTP 2.0在TCP协议上的重要功能,同时解决遗留问题,我们来看看QUIC是如何实现的。
5.2.1 队头阻塞问题
队头阻塞 Head-of-line blocking(缩写为HOL blocking)是计算机网络中是一种性能受限的现象,通俗来说就是:一个数据包影响了一堆数据包,它不来大家都走不了。
队头阻塞问题可能存在于HTTP层和TCP层,在HTTP 1.x时两个层次都存在该问题。
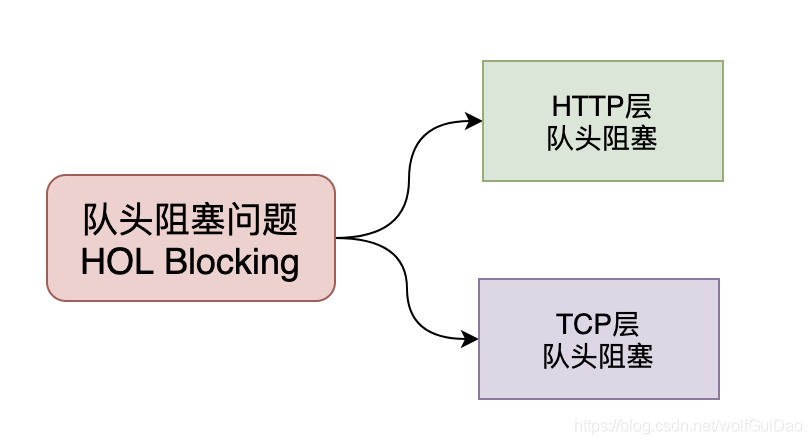
HTTP 2.0协议的多路复用机制解决了HTTP层的队头阻塞问题,但是在TCP层仍然存在队头阻塞问题。
TCP协议在收到数据包之后,这部分数据可能是乱序到达的,但是TCP必须将所有数据收集排序整合后给上层使用,如果其中某个包丢失了,就必须等待重传,从而出现某个丢包数据阻塞整个连接的数据使用。
多路复用是 HTTP 2.0 最强大的特性 ,能够将多条请求在一条 TCP 连接上同时发出去。但也恶化了 TCP 的一个问题,队头阻塞 ,如下图示:
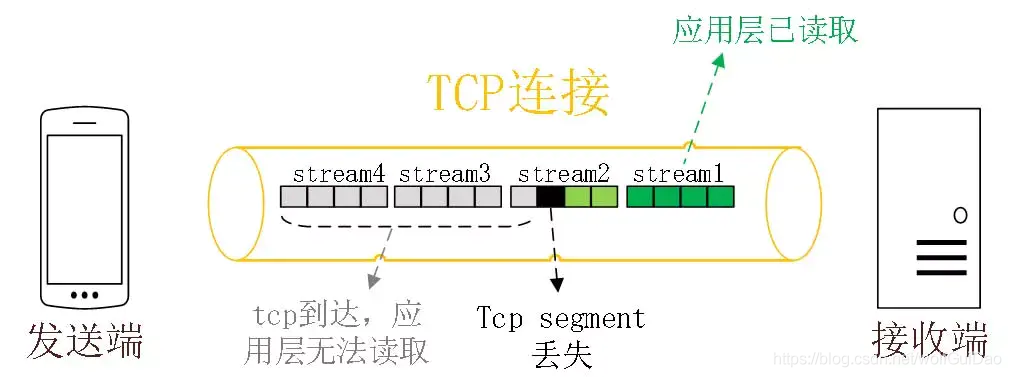
HTTP 2.0 在一个 TCP 连接上同时发送 4 个 Stream。其中 Stream1 已经正确到达,并被应用层读取。
但是 Stream2 的第三个 tcp segment 丢失了,TCP 为了保证数据的可靠性,需要发送端重传第 3 个 segment 才能通知应用层读取接下去的数据,虽然这个时候 Stream3 和 Stream4 的全部数据已经到达了接收端,但都被阻塞住了。
不仅如此,由于 HTTP 2.0 强制使用 TLS,还存在一个 TLS 协议层面的队头阻塞
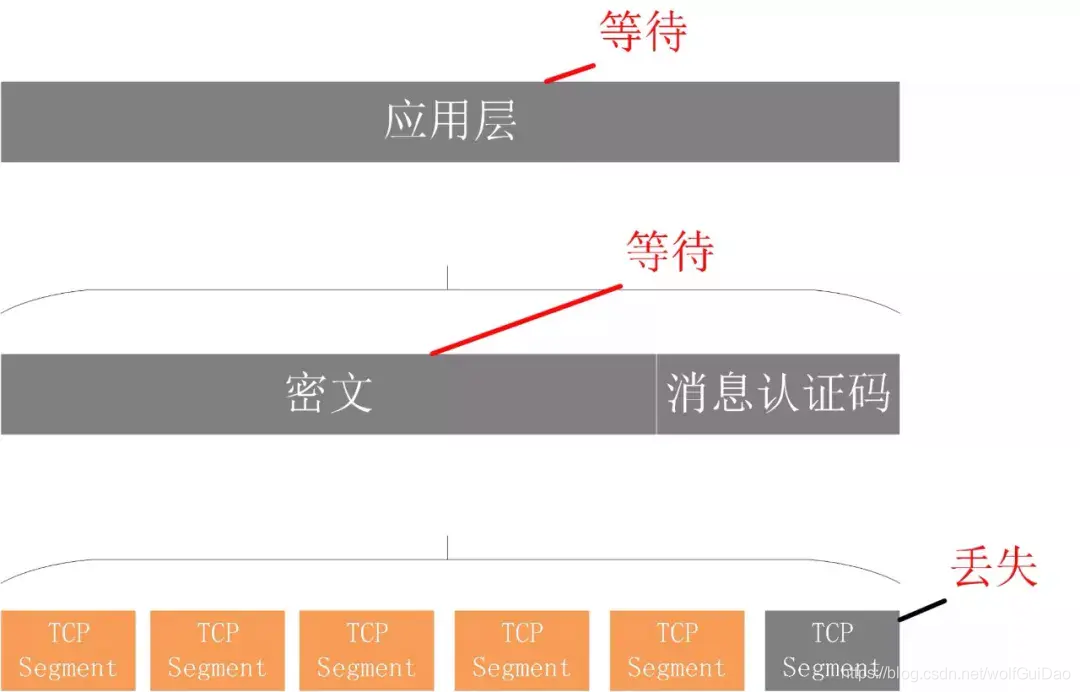
QUIC 的多路复用和 HTTP 2.0 类似。在一条 QUIC 连接上可以并发发送多个 HTTP 请求 (stream)。但是 QUIC 的多路复用相比 HTTP 2.0 有一个很大的优势。
QUIC 一个连接上的多个 stream 之间没有依赖。这样假如 stream2 丢了一个 udp packet,也只会影响 stream2 的处理。不会影响 stream2 之前及之后的 stream 的处理。
这也就在很大程度上缓解甚至消除了队头阻塞的影响。
QUIC协议是基于UDP协议实现的,在一条链接上可以有多个流,流与流之间是互不影响的,当一个流出现丢包影响范围非常小,从而解决队头阻塞问题
5.2.2 0RTT 建链
衡量网络建链的常用指标是RTT Round-Trip Time,也就是数据包一来一回的时间消耗。
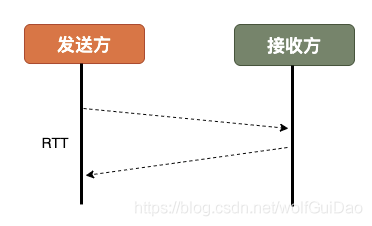
RTT包括三部分:往返传播时延、网络设备内排队时延、应用程序数据处理时延。
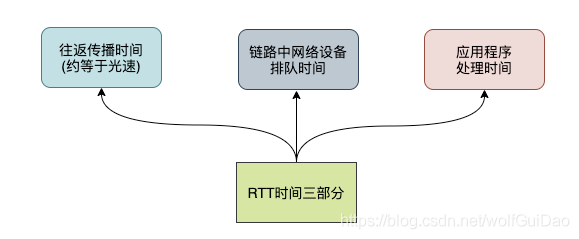
一般来说HTTPS协议要建立完整链接包括:TCP握手和TLS握手,总计需要至少2-3个RTT,普通的HTTP协议也需要至少1个RTT才可以完成握手。
然而,QUIC协议可以实现在第一个包就可以包含有效的应用数据,从而实现0RTT,但这也是有条件的。
0RTT 建连可以说是 QUIC 相比 HTTP2 最大的性能优势。那什么是 0RTT 建连呢?这里面有两层含义。
传输层 0RTT 就能建立连接
加密层 0RTT 就能建立加密连接
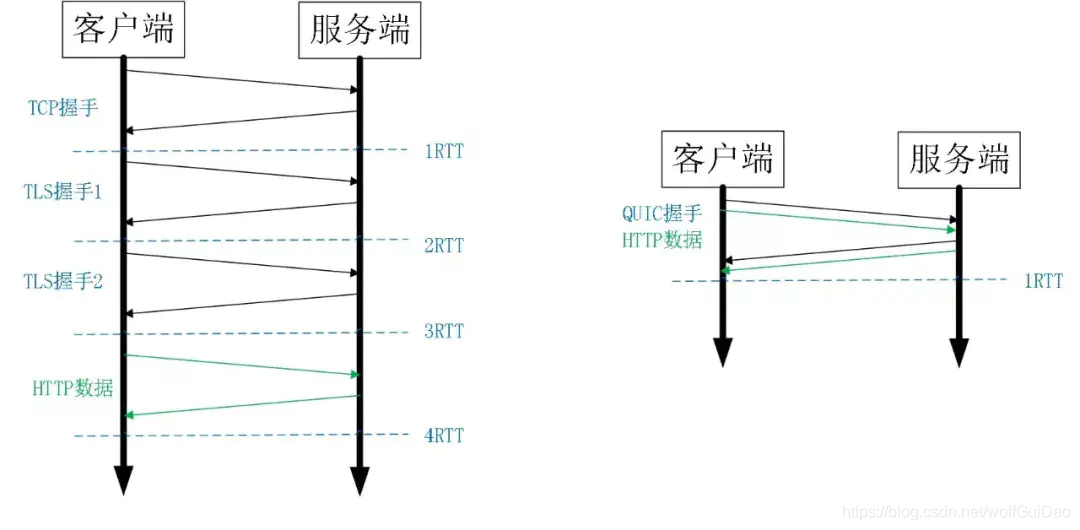
比如上图左边是 HTTPS 的一次完全握手的建连过程,需要 3 个 RTT。就算是 Session Resumption,也需要至少 2 个 RTT。
而 QUIC 呢?由于建立在 UDP 的基础上,同时又实现了 0RTT 的安全握手,所以在大部分情况下,只需要 0 个 RTT 就能实现数据发送,在实现前向加密 的基础上,并且 0RTT 的成功率相比 TLS 的 Sesison Ticket 要高很多。
简单来说,基于TCP协议和TLS协议的HTTP2.0在真正发送数据包之前需要花费一些时间来完成握手和加密协商,完成之后才可以真正传输业务数据。
但是QUIC则第一个数据包就可以发业务数据,从而在连接延时有很大优势,可以节约数百毫秒的时间。
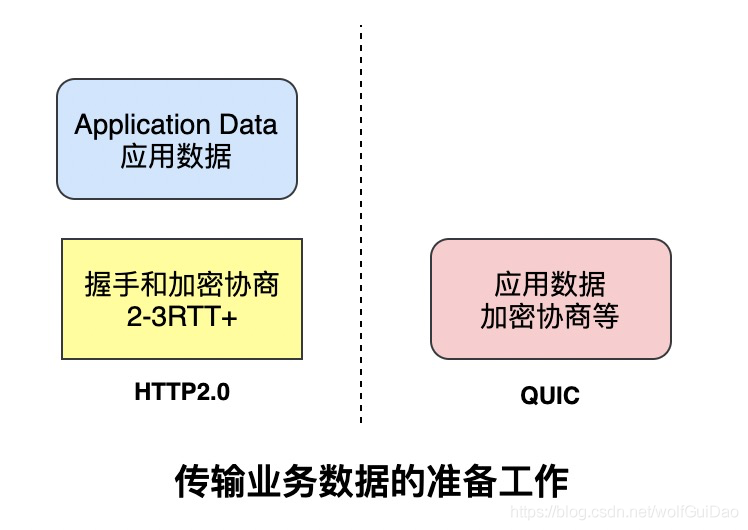
QUIC的0RTT也是需要条件的,对于第一次交互的客户端和服务端0RTT也是做不到的,毕竟双方完全陌生。
因此,QUIC协议可以分为首次连接和非首次连接,两种情况进行讨论。
5.2.2.1 首次连接和非首次连接
使用QUIC协议的客户端和服务端要使用1RTT进行密钥交换,使用的交换算法是DH(Diffie-Hellman)迪菲-赫尔曼算法。
5.2.2.2 首次连接
简单来说一下,首次连接时客户端和服务端的密钥协商和数据传输过程,其中涉及了DH算法的基本过程:

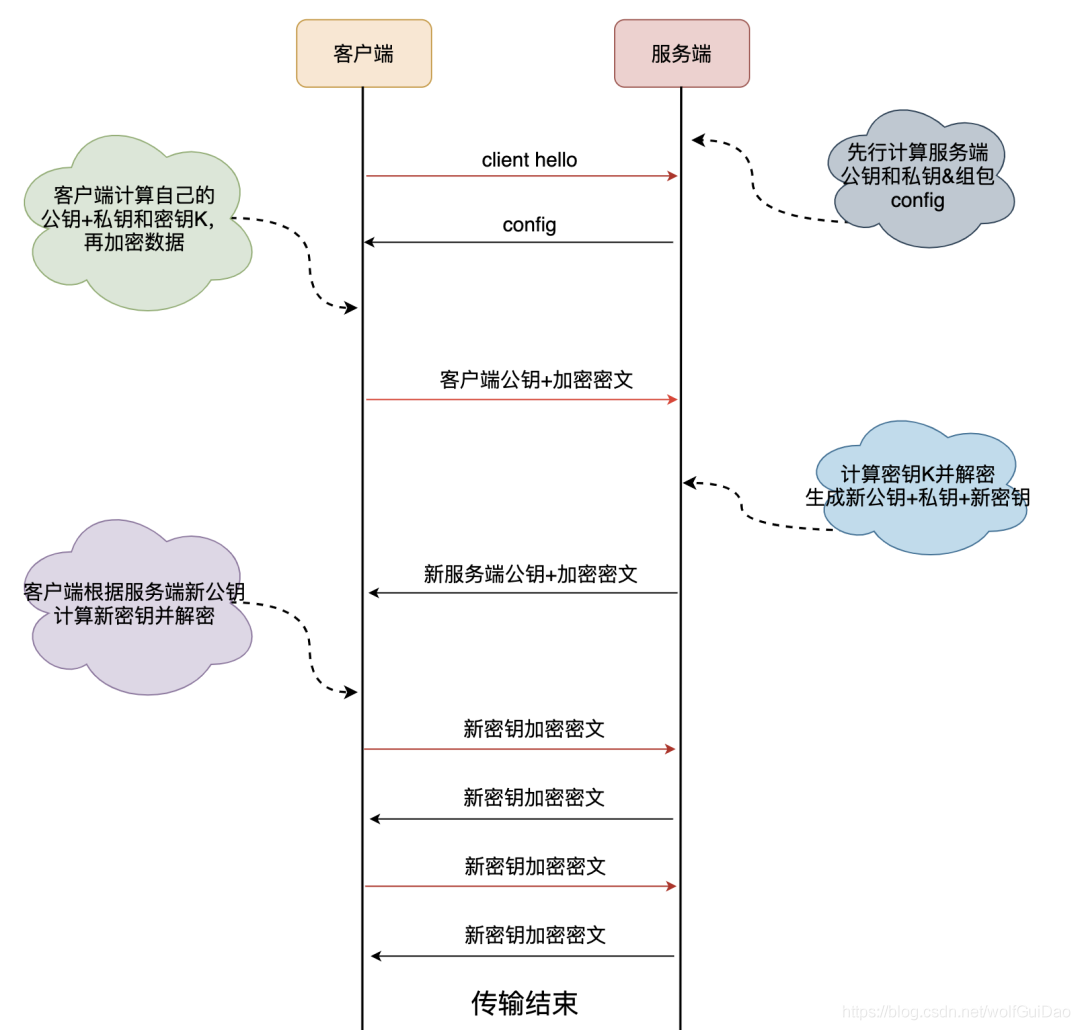
5.2.2.3 非首次连接
前面提到客户端和服务端首次连接时服务端传递了config包,里面包含了服务端公钥和两个随机数,客户端会将config存储下来,后续再连接时可以直接使用,从而跳过这个1RTT,实现0RTT的业务数据交互。
客户端保存config是有时间期限的,在config失效之后仍然需要进行首次连接时的密钥交换。
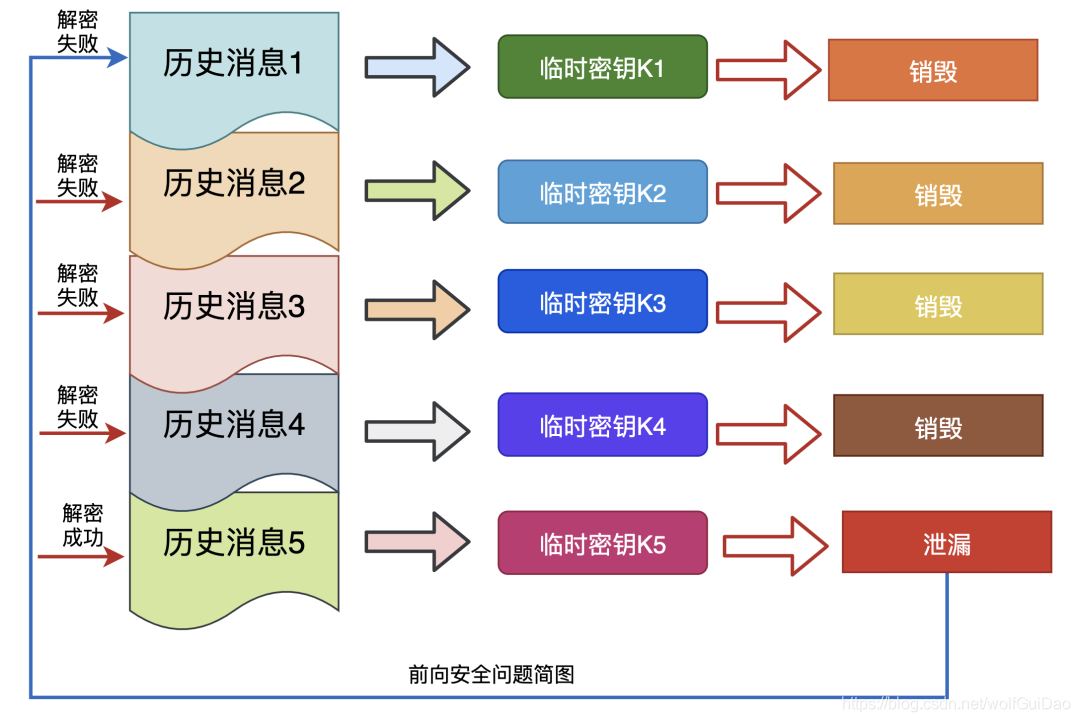
5.2.3 前向安全问题
前向安全是密码学领域的专业术语,看下百度上的解释:
前向安全或前向保密Forward Secrecy是密码学中通讯协议的安全属性,指的是长期使用的主密钥泄漏不会导致过去的会话密钥泄漏。
前向安全能够保护过去进行的通讯不受密码或密钥在未来暴露的威胁,如果系统具有前向安全性,就可以保证在主密钥泄露时历史通讯的安全,即使系统遭到主动攻击也是如此
通俗来说,前向安全指的是密钥泄漏也不会让之前加密的数据被泄漏,影响的只有当前,对之前的数据无影响。
5.2.4 前向纠错
前向纠错是通信领域的术语,看下百科的解释:
前向纠错也叫前向纠错码Forward Error Correction 简称FEC;是增加数据通讯可信度的方法,在单向通讯信道中,一旦错误被发现,其接收器将无权再请求传输。
FEC是利用数据进行传输冗余信息的方法,当传输中出现错误,将允许接收器再建数据。
听这段描述就是做校验的,看看QUIC协议是如何实现的:
QUIC每发送一组数据就对这组数据进行异或运算,并将结果作为一个FEC包发送出去,接收方收到这一组数据后根据数据包和FEC包即可进行校验和纠错。
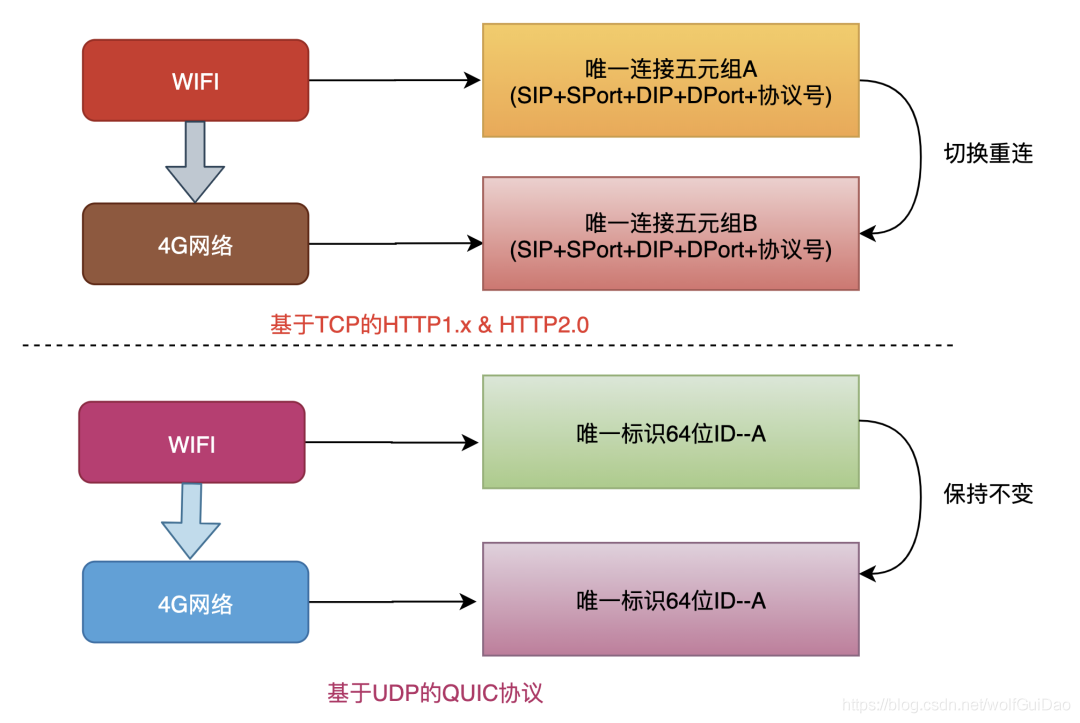
5.2.5 连接迁移
网络切换几乎无时无刻不在发生。
TCP协议使用五元组来表示一条唯一的连接,当我们从4G环境切换到wifi环境时,手机的IP地址就会发生变化,这时必须创建新的TCP连接才能继续传输数据。
QUIC协议基于UDP实现摒弃了五元组的概念,使用64位的随机数作为连接的ID,并使用该ID表示连接。
基于QUIC协议之下,我们在日常wifi和4G切换时,或者不同基站之间切换都不会重连,从而提高业务层的体验。
5.2.6 改进的拥塞控制
TCP 的拥塞控制实际上包含了四个算法:慢启动,拥塞避免,快速重传,快速恢复
QUIC 协议当前默认使用了 TCP 协议的 Cubic 拥塞控制算法 ,同时也支持 CubicBytes, Reno, RenoBytes, BBR, PCC 等拥塞控制算法。
从拥塞算法本身来看,QUIC 只是按照 TCP 协议重新实现了一遍,那么 QUIC 协议到底改进在哪些方面呢?主要有如下几点:
5.2.6.1 可插拔
什么叫可插拔呢?就是能够非常灵活地生效,变更和停止,体现在如下方面:
应用程序层面就能实现不同的拥塞控制算法,不需要操作系统,不需要内核支持。这是一个飞跃,因为传统的 TCP 拥塞控制,必须要端到端的网络协议栈支持,才能实现控制效果。而内核和操作系统的部署成本非常高,升级周期很长,这在产品快速迭代,网络爆炸式增长的今天,显然有点满足不了需求。
即使是单个应用程序的不同连接也能支持配置不同的拥塞控制。就算是一台服务器,接入的用户网络环境也千差万别,结合大数据及人工智能处理,我们能为各个用户提供不同的但又更加精准更加有效的拥塞控制。比如 BBR 适合,Cubic 适合。
应用程序不需要停机和升级就能实现拥塞控制的变更,我们在服务端只需要修改一下配置,reload 一下,完全不需要停止服务就能实现拥塞控制的切换。STGW 在配置层面进行了优化,我们可以针对不同业务,不同网络制式,甚至不同的 RTT,使用不同的拥塞控制算法。
5.2.6.2 单调递增的 Packet Number
TCP 为了保证可靠性,使用了基于字节序号的 Sequence Number 及 Ack 来确认消息的有序到达。
QUIC 同样是一个可靠的协议,它使用 Packet Number 代替了 TCP 的 sequence number,并且每个 Packet Number 都严格递增,也就是说就算 Packet N 丢失了,重传的 Packet N 的 Packet Number 已经不是 N,而是一个比 N 大的值。
而 TCP 呢,重传 segment 的 sequence number 和原始的 segment 的 Sequence Number 保持不变,也正是由于这个特性,引入了 Tcp 重传的歧义问题
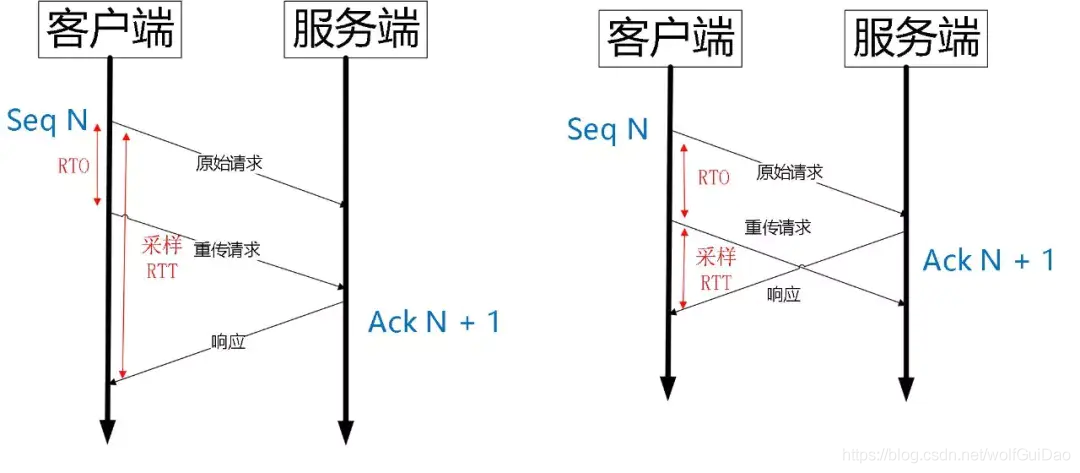
如上图所示,超时事件 RTO 发生后,客户端发起重传,然后接收到了 Ack 数据。由于序列号一样,这个 Ack 数据到底是原始请求的响应还是重传请求的响应呢?不好判断。
如果算成原始请求的响应,但实际上是重传请求的响应(上图左),会导致采样 RTT 变大。如果算成重传请求的响应,但实际上是原始请求的响应,又很容易导致采样 RTT 过小。
由于 Quic 重传的 Packet 和原始 Packet 的 Pakcet Number 是严格递增的,所以很容易就解决了这个问题。
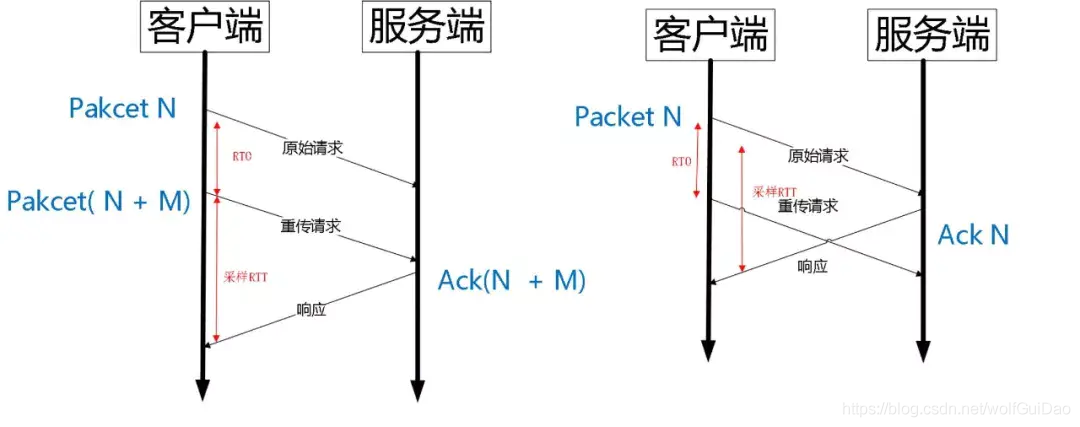
如上图所示,RTO 发生后,根据重传的 Packet Number 就能确定精确的 RTT 计算。如果 Ack 的 Packet Number 是 N+M,就根据重传请求计算采样 RTT。如果 Ack 的 Pakcet Number 是 N,就根据原始请求的时间计算采样 RTT,没有歧义性。
但是单纯依靠严格递增的 Packet Number 肯定是无法保证数据的顺序性和可靠性。QUIC 又引入了一个 Stream Offset 的概念。
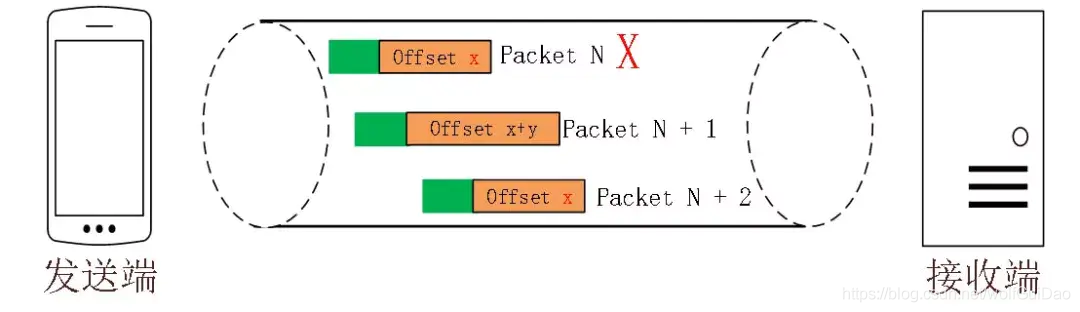
即一个 Stream 可以经过多个 Packet 传输,Packet Number 严格递增,没有依赖。
Packet 里的 Payload 如果是 Stream 的话,就需要依靠 Stream 的 Offset
来保证应用数据的顺序。
如图所示,发送端先后发送了 Pakcet N 和 Pakcet N+1,Stream 的Offset 分别是 x 和 x+y。
假设 Packet N 丢失了,发起重传,重传的 Packet Number 是 N+2,但是它的 Stream 的 Offset 依然是 x,这样就算 Packet N + 2 是后到的,依然可以将 Stream x 和 Stream x+y 按照顺序组织起来,交给应用程序处理。
5.2.6.3 不允许 Reneging
什么叫 Reneging 呢?就是接收方丢弃已经接收并且上报给 SACK 选项的内容 。TCP 协议不鼓励这种行为,但是协议层面允许这样的行为。主要是考虑到服务器资源有限,比如 Buffer 溢出,内存不够等情况。
Reneging 对数据重传会产生很大的干扰。因为 Sack 都已经表明接收到了,但是接收端事实上丢弃了该数据。
QUIC 在协议层面禁止 Reneging,一个 Packet 只要被 Ack,就认为它一定被正确接收,减少了这种干扰。
5.2.6.4 更多的 Ack 块
TCP 的 Sack 选项能够告诉发送方已经接收到的连续 Segment 的范围,方便发送方进行选择性重传。
由于 TCP 头部最大只有 60 个字节,标准头部占用了 20 字节,所以 Tcp Option 最大长度只有 40 字节,再加上 Tcp Timestamp option 占用了 10 个字节 ,所以留给 Sack 选项的只有 30 个字节。
每一个 Sack Block 的长度是 8 个,加上 Sack Option 头部 2 个字节,也就意味着 Tcp Sack Option 最大只能提供 3 个 Block。
但是 Quic Ack Frame 可以同时提供 256 个 Ack Block,在丢包率比较高的网络下,更多的 Sack Block 可以提升网络的恢复速度,减少重传量。
5.2.6.5 Ack Delay 时间
Tcp 的 Timestamp 选项存在一个问题 ,它只是回显了发送方的时间戳,但是没有计算接收端接收到 segment 到发送 Ack 该 segment 的时间。这个时间可以简称为 Ack Delay。
这样就会导致 RTT 计算误差。如下图:
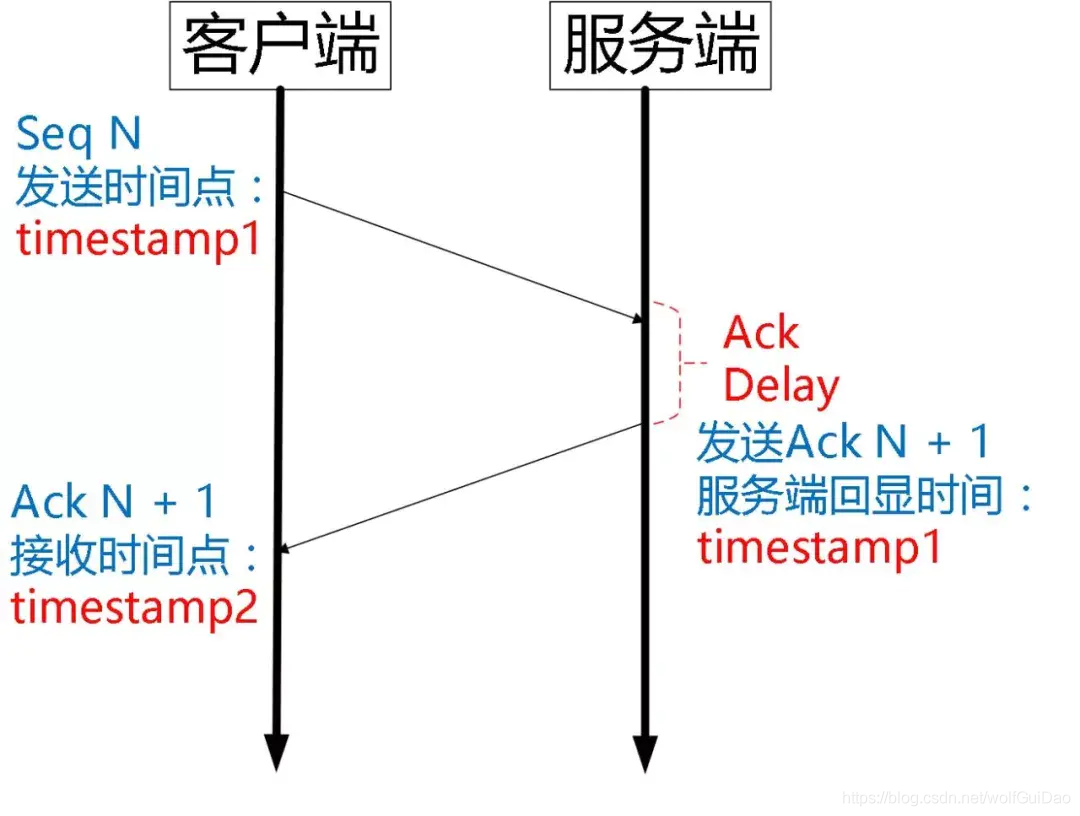
可以认为 TCP 的 RTT 计算:
而 Quic 计算如下: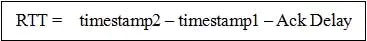
当然 RTT 的具体计算没有这么简单,需要采样,参考历史数值进行平滑计算,参考如下公式:
5.2.6.6 基于 stream 和 connecton 级别的流量控制
QUIC 的流量控制 类似 HTTP 2.0,即在 Connection 和 Stream 级别提供了两种流量控制。为什么需要两类流量控制呢?主要是因为 QUIC 支持多路复用。
Stream 可以认为就是一条 HTTP 请求。
Connection 可以类比一条 TCP 连接。
多路复用意味着在一条 Connetion 上会同时存在多条 Stream。既需要对单个 Stream 进行控制,又需要针对所有 Stream 进行总体控制。
QUIC 实现流量控制的原理比较简单:
通过 window_update 帧告诉对端自己可以接收的字节数,这样发送方就不会发送超过这个数量的数据。
通过 BlockFrame 告诉对端由于流量控制被阻塞了,无法发送数据。
QUIC 的流量控制和 TCP 有点区别,TCP 为了保证可靠性,窗口左边沿向右滑动时的长度取决于已经确认的字节数。如果中间出现丢包,就算接收到了更大序号的 Segment,窗口也无法超过这个序列号。
但 QUIC 不同,就算此前有些 packet 没有接收到,它的滑动只取决于接收到的最大偏移字节数。
针对 Stream:
针对 Connection:
同样地,STGW 也在连接和 Stream 级别设置了不同的窗口数。
最重要的是,我们可以在内存不足或者上游处理性能出现问题时,通过流量控制来限制传输速率,保障服务可用性。
5.3 总结
QUIC协议 存在的意义在于解决 TCP 协议的一些无法解决的痛点
- 多次握手:TCP 协议需要三次握手建立连接,而如果需要 TLS 证书的交换,那么则需要更多次的握手才能建立可靠连接,这在如今长肥网络的趋势下是一个巨大的痛点
- 队头阻塞:TCP 协议下,如果出现丢包,则一条连接将一直被阻塞等待该包的重传,即使后来的数据包可以被缓存,但也无法被递交给应用层去处理。
- 无法判断一个 ACK 是重传包的 ACK 还是原本包的 ACK:比如 一个包 seq=1, 超时重传的包同样是 seq=1,这样在收到一个 ack=1 之后,我们无法判断这个 ack 是对之前的包的 ack 还是对重传包的 ack,这会导致我们对 RTT 的估计出现误差,无法提供更准确的拥塞控制
- 无法进行连接迁移:一条连接由一个四元组标识,在当今移动互联网的时代,如果一台手机从一个 wifi 环境切换到另一个 wifi 环境,ip 发生变化,那么连接必须重新建立,inflight 的包全部丢失。
现在我们给出一个 QUIC 协议的 Overview - 更好的连接建立方式
- 更好的拥塞控制
- 没有队头阻塞的多路复用
- 前向纠错
- 连接迁移
6.WebSocket协议
前言
相较于HTTP协议,HTTP协议有一个的缺陷为:通信只能由客户端发起。在一些场景下,这种单向请求的特点,注定了如果服务器有连续的状态变化,客户端要获知就非常麻烦。我们只能使用轮询:每隔一段时候,就发出一个询问,了解服务器有没有新的信息。最典型的场景就是聊天室。轮询的效率低,非常浪费资源(因为必须不停连接,或者 HTTP 连接始终打开)。因此,工程师们一直在思考,有没有更好的方法。WebSocket 就是这样发明的。
6.1 WebSocket 协议概述
WebSocket是Web浏览器和服务器之间的一种全双工通信协议,其中WebSocket协议由IETF定为标准,WebSocket API由W3C定为标准。一旦Web客户端与服务器建立起连接,之后的全部数据通信都通过这个连接进行。通信过程中,可互相发送JSON、XML、HTML或图片等任意格式的数据。
WS(WebSocket)与HTTP协议相比,
相同点主要有:
都是基于TCP的应用层协议;
都使用Request/Response模型进行连接的建立;
在连接的建立过程中对错误的处理方式相同,在这个阶段WS可能返回和HTTP相同的返回码;
都可以在网络中传输数据。
不同之处在于:
- WS使用HTTP来建立连接,但是定义了一系列新的header域,这些域在HTTP中并不会使用;
- WS的连接不能通过中间人来转发,它必须是一个直接连接;
- WS连接建立之后,通信双方都可以在任何时刻向另一方发送数据;
- WS连接建立之后,数据的传输使用帧来传递,不再需要Request消息;
- WS的数据帧有序。
- WebSocket通信过程及对应报文分析
WS整个通信过程如下图所示:
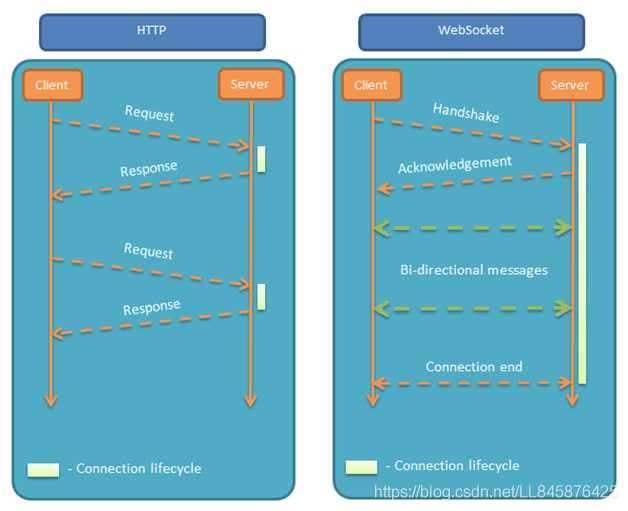
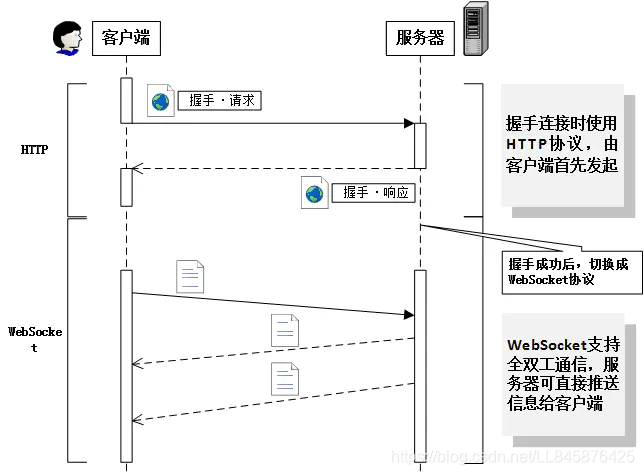
WebSocket是基于TCP的一个应用协议,与HTTP协议的关联之处在于WebSocket的握手数据被HTTP服务器当作HTTP包来处理,主要通过Update request HTTP包建立起连接,之后的通信全部使用WebSocket自己的协议。
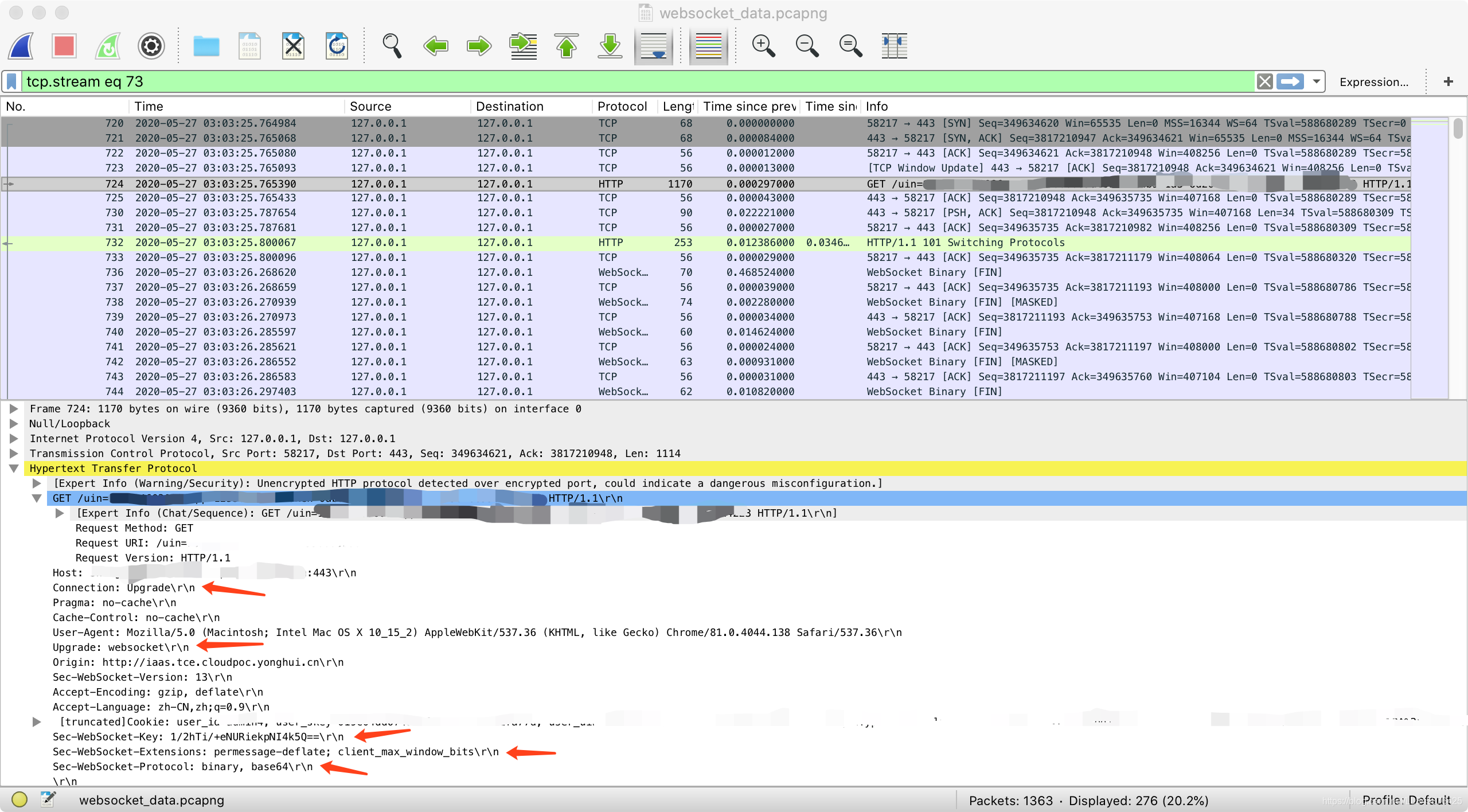
请求:TCP连接建立后,客户端发送WebSocket的握手请求,请求报文头部如下:
1 | GET /uin=xxxxxxxx&app=xxxxxxxxx&token=XXXXXXXXXXXX HTTP/1.1 |
- 第一行为为请求的方法,类型必须为GET,协议版本号必须大于1.1
- Upgrade字段必须包含,值为websocket
- Connection字段必须包含,值为Upgrade
- Sec-WebSocket-Key字段必须包含 ,记录着握手过程中必不可少的键值。
- Sec-WebSocket-Protocol字段必须包含 ,记录着使用的子协议
- Origin(请求头):Origin用来指明请求的来源,Origin头部主要用于保护Websocket服务器免受非授权的跨域脚本调用Websocket API的请求。也就是不想没被授权的跨域访问与服务器建立连接,服务器可以通过这个字段来判断来源的域并有选择的拒绝。
第一行为为请求的方法,类型必须为GET,协议版本号必须大于1.1
Upgrade字段必须包含,值为websocket
Connection字段必须包含,值为Upgrade
Sec-WebSocket-Key字段必须包含 ,记录着握手过程中必不可少的键值。
Sec-WebSocket-Protocol字段必须包含 ,记录着使用的子协议
Origin(请求头):Origin用来指明请求的来源,Origin头部主要用于保护Websocket服务器免受非授权的跨域脚本调用Websocket API的请求。也就是不想没被授权的跨域访问与服务器建立连接,服务器可以通过这个字段来判断来源的域并有选择的拒绝。
响应:服务器接收到请求后,返回状态码为101 Switching Protocols 的响应。
1 | HTTP/1.1 101 Switching Protocols |
Sec-WebSocket-Accept字段是由握手请求中的Sec-WebSocket-Key字段生层的。
握手成功后,通信不再使用HTTP协议,而采用WebSocket独立的数据帧。如下图所示,为协议帧格式:

1 | FIN,指明Frame是否是一个Message里最后Frame(之前说过一个Message可能又多个Frame组成);1bit,是否为信息的最后一帧 |
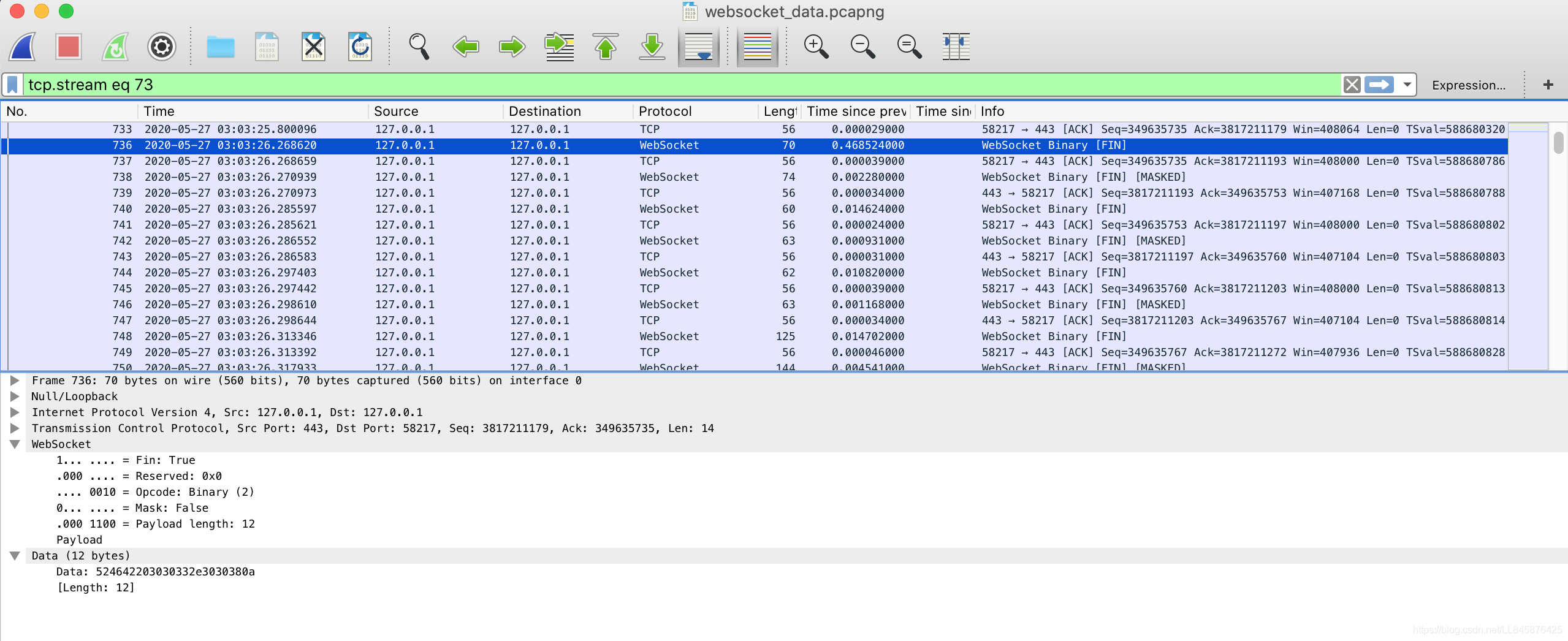
websocket 报文细节,这里由于client 和 server 端的 ip 都是127.0.0.1 :
6.2 Nginx 支持WebSocket 配置
由于HTTP请求 涉及 反向代理 所以就涉及 Nginx 配置需要支持WebSocket 需要做一些特殊的配置;
1 | # 配置Nginx支持WebSocket开始 |

其他通过代码模拟WebSocket 的代码可以查阅其他博客内容,这里就不赘述;
https://www.tutorialspoint.com/websockets/websockets_send_receive_messages.htm
http://www.ruanyifeng.com/blog/2017/05/websocket.html
7.TCP
TCP是一个巨复杂的协议,因为他要解决很多问题,而这些问题又带出了很多子问题和阴暗面。所以学习TCP本身是个比较痛苦的过程,但对于学习的过程却能让人有很多收获。关于TCP这个协议的细节,我还是推荐你去看W.Richard Stevens的《TCP/IP 详解 卷1:协议》(当然,你也可以去读一下RFC793以及后面N多的RFC)。另外,本文我会使用英文术语,这样方便你通过这些英文关键词来查找相关的技术文档。
首先,我们需要知道TCP在网络OSI的七层模型中的第四层——Transport层(传输层),IP在第三层——Network层(网络层),ARP在第二层——Data Link层(数据链路层),在第二层上的数据,我们叫Frame(帧),在第三层上的数据叫Packet(数据包),第四层的数据叫Segment(片段)。
首先,我们需要知道,我们程序的数据首先会打到TCP的Segment中,然后TCP的Segment会打到IP的Packet中,然后再打到以太网Ethernet的Frame中,传到对端后,各个层解析自己的协议,然后把数据交给更高层的协议处理。
7.1 TCP头格式
接下来,我们来看一下TCP头的格式
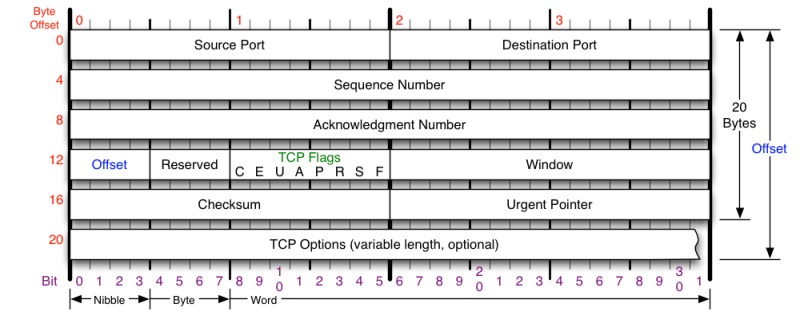 TCP头格式(图片来源)
TCP头格式(图片来源)
你需要注意这么几点:
- TCP的包是没有IP地址的,那是IP层上的事。但是有源端口和目标端口。
- 一个TCP连接需要四个元组来表示是同一个连接(src_ip, src_port, dst_ip, dst_port)准确说是五元组,还有一个是协议。但因为这里只是说TCP协议,所以,这里我只说四元组。
- 注意上图中的四个非常重要的东西:
- Sequence Number是包的序号,用来解决网络包乱序(reordering)问题。
- Acknowledgement Number就是ACK——用于确认收到,用来解决不丢包的问题。
- Window又叫Advertised-Window,也就是著名的滑动窗口(Sliding Window),用于解决流控的。
- TCP Flag ,也就是包的类型,主要是用于操控TCP的状态机的。
关于其它的东西,可以参看下面的图示
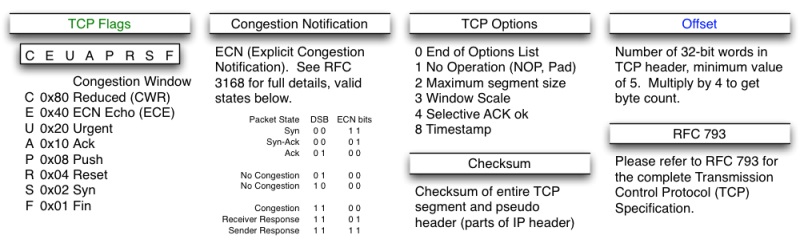
(图片来源)
7.2 TCP的状态机
其实,网络上的传输是没有连接的,包括TCP也是一样的。而TCP所谓的“连接”,其实只不过是在通讯的双方维护一个“连接状态”,让它看上去好像有连接一样。所以,TCP的状态变换是非常重要的。
下面是:“TCP协议的状态机”(图片来源) 和 “TCP建链接”、“TCP断链接”、“传数据” 的对照图,我把两个图并排放在一起,这样方便在你对照着看。另外,下面这两个图非常非常的重要,你一定要记牢。(吐个槽:看到这样复杂的状态机,就知道这个协议有多复杂,复杂的东西总是有很多坑爹的事情,所以TCP协议其实也挺坑爹的)
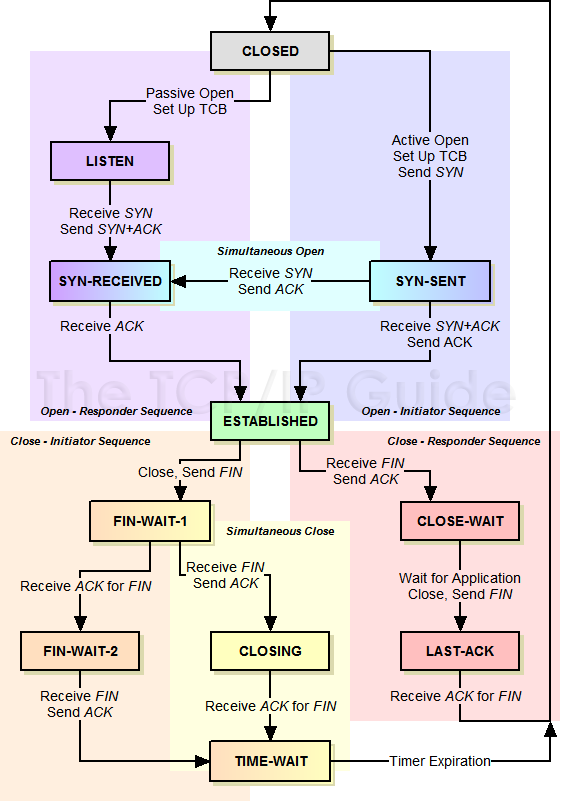 !
!
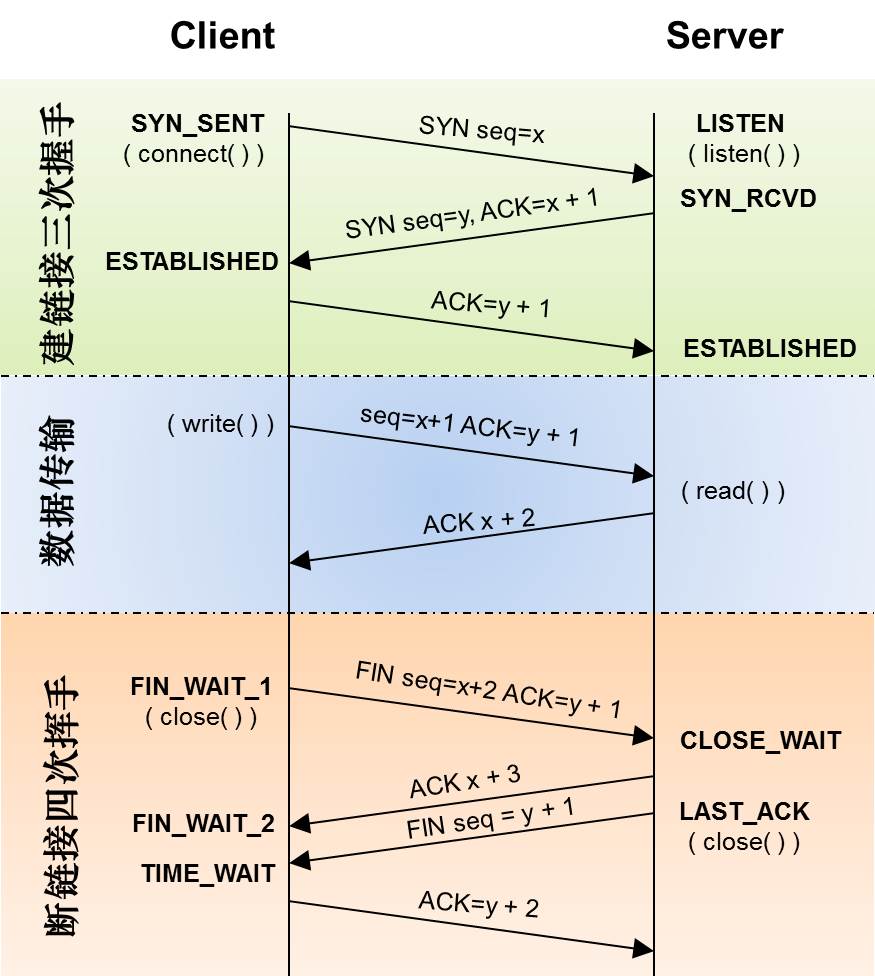
很多人会问,为什么建立链接要3次握手,断链接需要4次挥手?
对于建链接的3次握手,主要是要初始化Sequence Number 的初始值。通信的双方要互相通知对方自己的初始化的Sequence Number(缩写为ISN:Inital Sequence Number)——所以叫SYN,全称Synchronize Sequence Numbers。也就上图中的 x 和 y。这个号要作为以后的数据通信的序号,以保证应用层接收到的数据不会因为网络上的传输的问题而乱序(TCP会用这个序号来拼接数据)。
对于4次挥手,其实你仔细看是2次,因为TCP是全双工的,所以,发送方和接收方都需要Fin和Ack。只不过,有一方是被动的,所以看上去就成了所谓的4次挥手。如果两边同时断连接,那就会就进入到CLOSING状态,然后到达TIME_WAIT状态。下图是双方同时断连接的示意图(你同样可以对照着TCP状态机看):
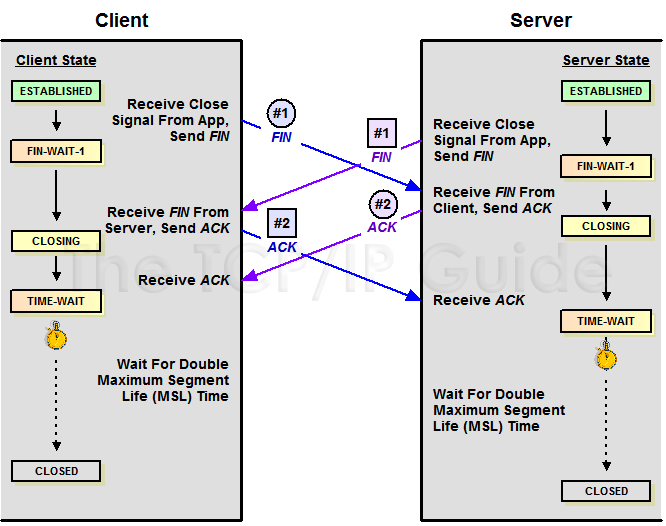
两端同时断连接(图片来源)
另外,有几个事情需要注意一下:
关于建连接时SYN超时。试想一下,如果server端接到了clien发的SYN后回了SYN-ACK后client掉线了,server端没有收到client回来的ACK,那么,这个连接处于一个中间状态,即没成功,也没失败。于是,server端如果在一定时间内没有收到的TCP会重发SYN-ACK。在Linux下,默认重试次数为5次,重试的间隔时间从1s开始每次都翻售,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s,总共31s,第5次发出后还要等32s都知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 2^6 -1 = 63s,TCP才会把断开这个连接。
关于SYN Flood攻击。一些恶意的人就为此制造了SYN Flood攻击——给服务器发了一个SYN后,就下线了,于是服务器需要默认等63s才会断开连接,这样,攻击者就可以把服务器的syn连接的队列耗尽,让正常的连接请求不能处理。于是,Linux下给了一个叫tcp_syncookies的参数来应对这个事——当SYN队列满了后,TCP会通过源地址端口、目标地址端口和时间戳打造出一个特别的Sequence Number发回去(又叫cookie),如果是攻击者则不会有响应,如果是正常连接,则会把这个 SYN Cookie发回来,然后服务端可以通过cookie建连接(即使你不在SYN队列中)。请注意,请先千万别用tcp_syncookies来处理正常的大负载的连接的情况。因为,synccookies是妥协版的TCP协议,并不严谨。对于正常的请求,你应该调整三个TCP参数可供你选择,第一个是:tcp_synack_retries 可以用他来减少重试次数;第二个是:tcp_max_syn_backlog,可以增大SYN连接数;第三个是:tcp_abort_on_overflow 处理不过来干脆就直接拒绝连接了。
关于ISN的初始化。ISN是不能hard code的,不然会出问题的——比如:如果连接建好后始终用1来做ISN,如果client发了30个segment过去,但是网络断了,于是 client重连,又用了1做ISN,但是之前连接的那些包到了,于是就被当成了新连接的包,此时,client的Sequence Number 可能是3,而Server端认为client端的这个号是30了。全乱了。RFC793中说,ISN会和一个假的时钟绑在一起,这个时钟会在每4微秒对ISN做加一操作,直到超过2^32,又从0开始。这样,一个ISN的周期大约是4.55个小时。因为,我们假设我们的TCP Segment在网络上的存活时间不会超过Maximum Segment Lifetime(缩写为MSL – Wikipedia语条),所以,只要MSL的值小于4.55小时,那么,我们就不会重用到ISN。
关于 MSL 和 TIME_WAIT。通过上面的ISN的描述,相信你也知道MSL是怎么来的了。我们注意到,在TCP的状态图中,从TIME_WAIT状态到CLOSED状态,有一个超时设置,这个超时设置是 2*MSL(RFC793定义了MSL为2分钟,Linux设置成了30s)为什么要这有TIME_WAIT?为什么不直接给转成CLOSED状态呢?主要有两个原因:1)TIME_WAIT确保有足够的时间让对端收到了ACK,如果被动关闭的那方没有收到Ack,就会触发被动端重发Fin,一来一去正好2个MSL,2)有足够的时间让这个连接不会跟后面的连接混在一起(你要知道,有些自做主张的路由器会缓存IP数据包,如果连接被重用了,那么这些延迟收到的包就有可能会跟新连接混在一起)。你可以看看这篇文章《TIME_WAIT and its design implications for protocols and scalable client server systems》
关于TIME_WAIT数量太多。从上面的描述我们可以知道,TIME_WAIT是个很重要的状态,但是如果在大并发的短链接下,TIME_WAIT 就会太多,这也会消耗很多系统资源。只要搜一下,你就会发现,十有八九的处理方式都是教你设置两个参数,一个叫tcp_tw_reuse,另一个叫tcp_tw_recycle的参数,这两个参数默认值都是被关闭的,后者recyle比前者resue更为激进,resue要温柔一些。另外,如果使用tcp_tw_reuse,必需设置tcp_timestamps=1,否则无效。这里,你一定要注意,打开这两个参数会有比较大的坑——可能会让TCP连接出一些诡异的问题(因为如上述一样,如果不等待超时重用连接的话,新的连接可能会建不上。正如官方文档上说的一样“It should not be changed without advice/request of technical experts”)。
关于tcp_tw_reuse。官方文档上说tcp_tw_reuse 加上tcp_timestamps(又叫PAWS, for Protection Against Wrapped Sequence Numbers)可以保证协议的角度上的安全,但是你需要tcp_timestamps在两边都被打开(你可以读一下tcp_twsk_unique的源码 )。我个人估计还是有一些场景会有问题。
关于tcp_tw_recycle。如果是tcp_tw_recycle被打开了话,会假设对端开启了tcp_timestamps,然后会去比较时间戳,如果时间戳变大了,就可以重用。但是,如果对端是一个NAT网络的话(如:一个公司只用一个IP出公网)或是对端的IP被另一台重用了,这个事就复杂了。建链接的SYN可能就被直接丢掉了(你可能会看到connection time out的错误)(如果你想观摩一下Linux的内核代码,请参看源码 tcp_timewait_state_process)。
关于tcp_max_tw_buckets。这个是控制并发的TIME_WAIT的数量,默认值是180000,如果超限,那么,系统会把多的给destory掉,然后在日志里打一个警告(如:time wait bucket table overflow),官网文档说这个参数是用来对抗DDoS攻击的。也说的默认值180000并不小。这个还是需要根据实际情况考虑。
Again,使用tcp_tw_reuse和tcp_tw_recycle来解决TIME_WAIT的问题是非常非常危险的,因为这两个参数违反了TCP协议(RFC 1122)
其实,TIME_WAIT表示的是你主动断连接,所以,这就是所谓的“不作死不会死”。试想,如果让对端断连接,那么这个破问题就是对方的了,呵呵。另外,如果你的服务器是于HTTP服务器,那么设置一个HTTP的KeepAlive有多重要(浏览器会重用一个TCP连接来处理多个HTTP请求),然后让客户端去断链接(你要小心,浏览器可能会非常贪婪,他们不到万不得已不会主动断连接)。
7.3 数据传输中的Sequence Number
下图是我从Wireshark中截了个我在访问coolshell.cn时的有数据传输的图给你看一下,SeqNum是怎么变的。(使用Wireshark菜单中的Statistics ->Flow Graph… )
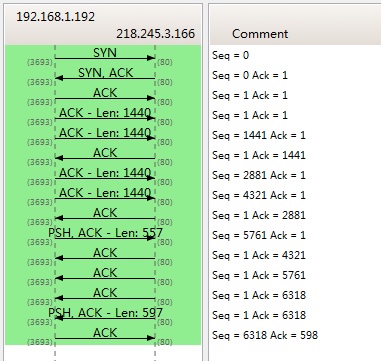
你可以看到,SeqNum的增加是和传输的字节数相关的。上图中,三次握手后,来了两个Len:1440的包,而第二个包的SeqNum就成了1441。然后第一个ACK回的是1441,表示第一个1440收到了。
注意:如果你用Wireshark抓包程序看3次握手,你会发现SeqNum总是为0,不是这样的,Wireshark为了显示更友好,使用了Relative SeqNum——相对序号,你只要在右键菜单中的protocol preference 中取消掉就可以看到“Absolute SeqNum”了
7.4 TCP重传机制
TCP要保证所有的数据包都可以到达,所以,必需要有重传机制。
注意,接收端给发送端的Ack确认只会确认最后一个连续的包,比如,发送端发了1,2,3,4,5一共五份数据,接收端收到了1,2,于是回ack 3,然后收到了4(注意此时3没收到),此时的TCP会怎么办?我们要知道,因为正如前面所说的,SeqNum和Ack是以字节数为单位,所以ack的时候,不能跳着确认,只能确认最大的连续收到的包,不然,发送端就以为之前的都收到了。
7.4.1 超时重传机制
一种是不回ack,死等3,当发送方发现收不到3的ack超时后,会重传3。一旦接收方收到3后,会ack 回 4——意味着3和4都收到了。
但是,这种方式会有比较严重的问题,那就是因为要死等3,所以会导致4和5即便已经收到了,而发送方也完全不知道发生了什么事,因为没有收到Ack,所以,发送方可能会悲观地认为也丢了,所以有可能也会导致4和5的重传。
对此有两种选择:
- 一种是仅重传timeout的包。也就是第3份数据。
- 另一种是重传timeout后所有的数据,也就是第3,4,5这三份数据。
这两种方式有好也有不好。第一种会节省带宽,但是慢,第二种会快一点,但是会浪费带宽,也可能会有无用功。但总体来说都不好。因为都在等timeout,timeout可能会很长(在下篇会说TCP是怎么动态地计算出timeout的)
7.4.2 快速重传机制
于是,TCP引入了一种叫Fast Retransmit 的算法,不以时间驱动,而以数据驱动重传。也就是说,如果,包没有连续到达,就ack最后那个可能被丢了的包,如果发送方连续收到3次相同的ack,就重传。Fast Retransmit的好处是不用等timeout了再重传。
比如:如果发送方发出了1,2,3,4,5份数据,第一份先到送了,于是就ack回2,结果2因为某些原因没收到,3到达了,于是还是ack回2,后面的4和5都到了,但是还是ack回2,因为2还是没有收到,于是发送端收到了三个ack=2的确认,知道了2还没有到,于是就马上重转2。然后,接收端收到了2,此时因为3,4,5都收到了,于是ack回6。示意图如下:
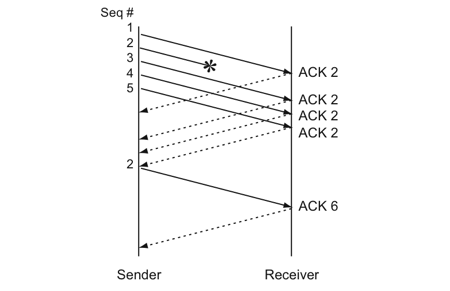
Fast Retransmit只解决了一个问题,就是timeout的问题,它依然面临一个艰难的选择,就是,是重传之前的一个还是重传所有的问题。对于上面的示例来说,是重传#2呢还是重传#2,#3,#4,#5呢?因为发送端并不清楚这连续的3个ack(2)是谁传回来的?也许发送端发了20份数据,是#6,#10,#20传来的呢。这样,发送端很有可能要重传从2到20的这堆数据(这就是某些TCP的实际的实现)。可见,这是一把双刃剑。
7.4.3 SACK 方法
另外一种更好的方式叫:**Selective Acknowledgment (SACK)**(参看RFC 2018),这种方式需要在TCP头里加一个SACK的东西,ACK还是Fast Retransmit的ACK,SACK则是汇报收到的数据碎版。参看下图:
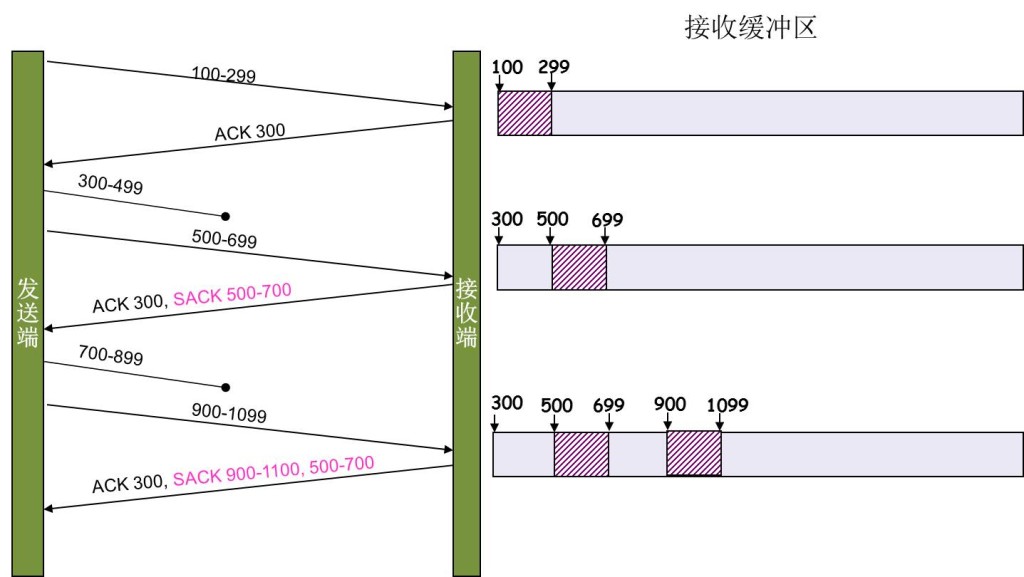
这样,在发送端就可以根据回传的SACK来知道哪些数据到了,哪些没有到。于是就优化了Fast Retransmit的算法。当然,这个协议需要两边都支持。在 Linux下,可以通过tcp_sack参数打开这个功能(Linux 2.4后默认打开)。
这里还需要注意一个问题——接收方Reneging,所谓Reneging的意思就是接收方有权把已经报给发送端SACK里的数据给丢了。这样干是不被鼓励的,因为这个事会把问题复杂化了,但是,接收方这么做可能会有些极端情况,比如要把内存给别的更重要的东西。所以,发送方也不能完全依赖SACK,还是要依赖ACK,并维护Time-Out,如果后续的ACK没有增长,那么还是要把SACK的东西重传,另外,接收端这边永远不能把SACK的包标记为Ack。
注意:SACK会消费发送方的资源,试想,如果一个攻击者给数据发送方发一堆SACK的选项,这会导致发送方开始要重传甚至遍历已经发出的数据,这会消耗很多发送端的资源。详细的东西请参看《TCP SACK的性能权衡》
7.4.4 Duplicate SACK – 重复收到数据的问题
Duplicate SACK又称D-SACK,其主要使用了SACK来告诉发送方有哪些数据被重复接收了。RFC-2883 里有详细描述和示例。下面举几个例子(来源于RFC-2883)
D-SACK使用了SACK的第一个段来做标志,
如果SACK的第一个段的范围被ACK所覆盖,那么就是D-SACK
如果SACK的第一个段的范围被SACK的第二个段覆盖,那么就是D-SACK
示例一:ACK丢包
下面的示例中,丢了两个ACK,所以,发送端重传了第一个数据包(3000-3499),于是接收端发现重复收到,于是回了一个SACK=3000-3500,因为ACK都到了4000意味着收到了4000之前的所有数据,所以这个SACK就是D-SACK——旨在告诉发送端我收到了重复的数据,而且我们的发送端还知道,数据包没有丢,丢的是ACK包。
1 | Transmitted Received ACK Sent |
示例二,网络延误
下面的示例中,网络包(1000-1499)被网络给延误了,导致发送方没有收到ACK,而后面到达的三个包触发了“Fast Retransmit算法”,所以重传,但重传时,被延误的包又到了,所以,回了一个SACK=1000-1500,因为ACK已到了3000,所以,这个SACK是D-SACK——标识收到了重复的包。
这个案例下,发送端知道之前因为“Fast Retransmit算法”触发的重传不是因为发出去的包丢了,也不是因为回应的ACK包丢了,而是因为网络延时了。
1 | Transmitted Received ACK Sent |
可见,引入了D-SACK,有这么几个好处:
1)可以让发送方知道,是发出去的包丢了,还是回来的ACK包丢了。
2)是不是自己的timeout太小了,导致重传。
3)网络上出现了先发的包后到的情况(又称reordering)
4)网络上是不是把我的数据包给复制了。
知道这些东西可以很好得帮助TCP了解网络情况,从而可以更好的做网络上的流控。
Linux下的tcp_dsack参数用于开启这个功能(Linux 2.4后默认打开)
7.5 TCP的RTT算法
从前面的TCP重传机制我们知道Timeout的设置对于重传非常重要。
- 设长了,重发就慢,丢了老半天才重发,没有效率,性能差;
- 设短了,会导致可能并没有丢就重发。于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
而且,这个超时时间在不同的网络的情况下,根本没有办法设置一个死的值。只能动态地设置。 为了动态地设置,TCP引入了RTT——Round Trip Time,也就是一个数据包从发出去到回来的时间。这样发送端就大约知道需要多少的时间,从而可以方便地设置Timeout——RTO(Retransmission TimeOut),以让我们的重传机制更高效。 听起来似乎很简单,好像就是在发送端发包时记下t0,然后接收端再把这个ack回来时再记一个t1,于是RTT = t1 – t0。没那么简单,这只是一个采样,不能代表普遍情况。
7.5.1 经典算法
RFC793 中定义的经典算法是这样的:
1)首先,先采样RTT,记下最近好几次的RTT值。
2)然后做平滑计算SRTT( Smoothed RTT)。公式为:(其中的 α 取值在0.8 到 0.9之间,这个算法英文叫Exponential weighted moving average,中文叫:加权移动平均)
SRTT = ( α * SRTT ) + ((1- α) * RTT)
3)开始计算RTO。公式如下:
RTO = min [ UBOUND, max [ LBOUND, (β * SRTT) ] ]
其中:
- UBOUND是最大的timeout时间,上限值
- LBOUND是最小的timeout时间,下限值
- β 值一般在1.3到2.0之间。
7.5.2 Karn / Partridge 算法
但是上面的这个算法在重传的时候会出有一个终极问题——你是用第一次发数据的时间和ack回来的时间做RTT样本值,还是用重传的时间和ACK回来的时间做RTT样本值?
这个问题无论你选那头都是按下葫芦起了瓢。 如下图所示:
- 情况(a)是ack没回来,所以重传。如果你计算第一次发送和ACK的时间,那么,明显算大了。
- 情况(b)是ack回来慢了,但是导致了重传,但刚重传不一会儿,之前ACK就回来了。如果你是算重传的时间和ACK回来的时间的差,就会算短了。
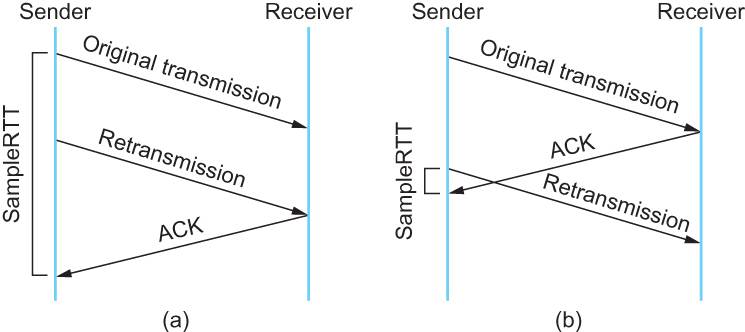
所以1987年的时候,搞了一个叫Karn / Partridge Algorithm,这个算法的最大特点是——忽略重传,不把重传的RTT做采样(你看,你不需要去解决不存在的问题)。
但是,这样一来,又会引发一个大BUG——如果在某一时间,网络闪动,突然变慢了,产生了比较大的延时,这个延时导致要重转所有的包(因为之前的RTO很小),于是,因为重转的不算,所以,RTO就不会被更新,这是一个灾难。 于是Karn算法用了一个取巧的方式——只要一发生重传,就对现有的RTO值翻倍(这就是所谓的 Exponential backoff),很明显,这种死规矩对于一个需要估计比较准确的RTT也不靠谱。
7.5.3 Jacobson / Karels 算法
前面两种算法用的都是“加权移动平均”,这种方法最大的毛病就是如果RTT有一个大的波动的话,很难被发现,因为被平滑掉了。所以,1988年,又有人推出来了一个新的算法,这个算法叫Jacobson / Karels Algorithm(参看RFC6289)。这个算法引入了最新的RTT的采样和平滑过的SRTT的差距做因子来计算。 公式如下:(其中的DevRTT是Deviation RTT的意思)
SRTT= SRTT + α(RTT – SRTT) —— 计算平滑RTT
DevRTT = (1-β)DevRTT + β(|RTT-SRTT|) ——计算平滑RTT和真实的差距(加权移动平均)
RTO= µ * SRTT + ∂ *DevRTT —— 神一样的公式
(其中:在Linux下,α = 0.125,β = 0.25, μ = 1,∂ = 4 ——这就是算法中的“调得一手好参数”,nobody knows why, it just works…) 最后的这个算法在被用在今天的TCP协议中(Linux的源代码在:tcp_rtt_estimator)。
7.6 TCP滑动窗口
需要说明一下,如果你不了解TCP的滑动窗口这个事,你等于不了解TCP协议。我们都知道,TCP必需要解决的可靠传输以及包乱序(reordering)的问题,所以,TCP必需要知道网络实际的数据处理带宽或是数据处理速度,这样才不会引起网络拥塞,导致丢包。
所以,TCP引入了一些技术和设计来做网络流控,Sliding Window是其中一个技术。 前面我们说过,TCP头里有一个字段叫Window,又叫Advertised-Window,这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。 为了说明滑动窗口,我们需要先看一下TCP缓冲区的一些数据结构:
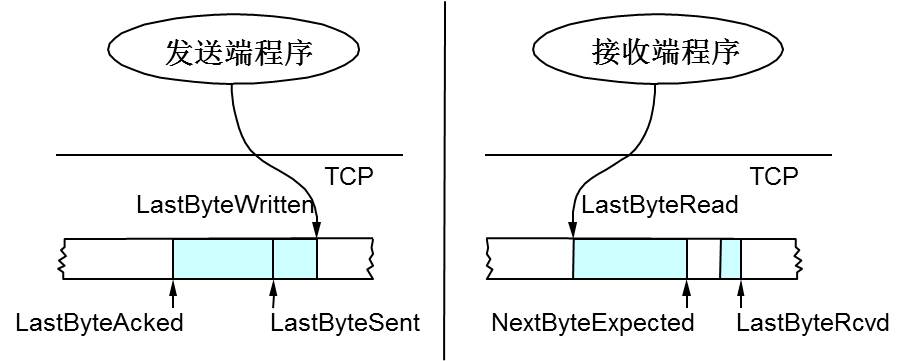
上图中,我们可以看到:
接收端LastByteRead指向了TCP缓冲区中读到的位置,NextByteExpected指向的地方是收到的连续包的最后一个位置,LastByteRcved指向的是收到的包的最后一个位置,我们可以看到中间有些数据还没有到达,所以有数据空白区。
发送端的LastByteAcked指向了被接收端Ack过的位置(表示成功发送确认),LastByteSent表示发出去了,但还没有收到成功确认的Ack,LastByteWritten指向的是上层应用正在写的地方。
于是:
接收端在给发送端回ACK中会汇报自己的AdvertisedWindow = MaxRcvBuffer – LastByteRcvd – 1;
而发送方会根据这个窗口来控制发送数据的大小,以保证接收方可以处理。
下面我们来看一下发送方的滑动窗口示意图:
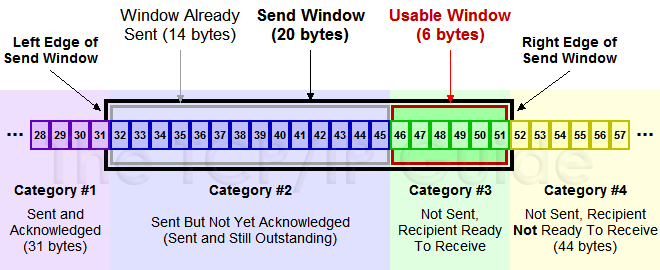
(图片来源)
上图中分成了四个部分,分别是:(其中那个黑模型就是滑动窗口)
- #1已收到ack确认的数据。
- #2发还没收到ack的。
- #3在窗口中还没有发出的(接收方还有空间)。
- #4窗口以外的数据(接收方没空间)
下面是个滑动后的示意图(收到36的ack,并发出了46-51的字节):
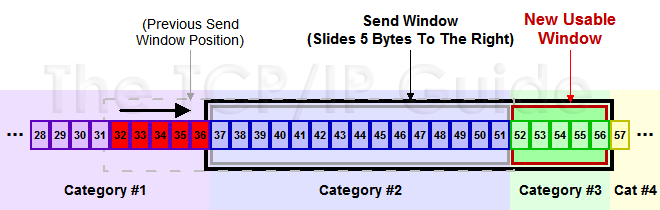
下面我们来看一个接受端控制发送端的图示:
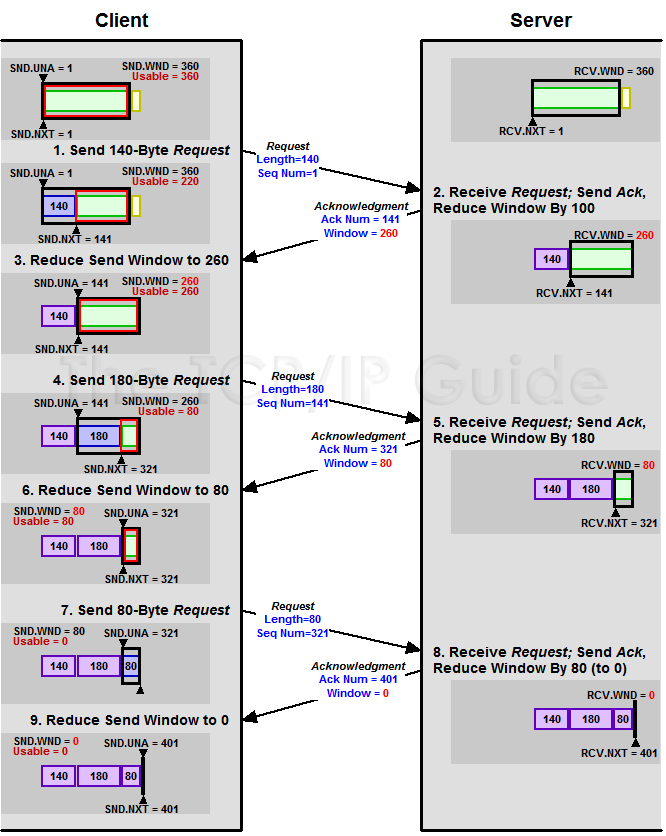
(图片来源)
7.6.1 Zero Window
上图,我们可以看到一个处理缓慢的Server(接收端)是怎么把Client(发送端)的TCP Sliding Window给降成0的。此时,你一定会问,如果Window变成0了,TCP会怎么样?是不是发送端就不发数据了?是的,发送端就不发数据了,你可以想像成“Window Closed”,那你一定还会问,如果发送端不发数据了,接收方一会儿Window size 可用了,怎么通知发送端呢?
解决这个问题,TCP使用了Zero Window Probe技术,缩写为ZWP,也就是说,发送端在窗口变成0后,会发ZWP的包给接收方,让接收方来ack他的Window尺寸,一般这个值会设置成3次,第次大约30-60秒(不同的实现可能会不一样)。如果3次过后还是0的话,有的TCP实现就会发RST把链接断了。
注意:只要有等待的地方都可能出现DDoS攻击,Zero Window也不例外,一些攻击者会在和HTTP建好链发完GET请求后,就把Window设置为0,然后服务端就只能等待进行ZWP,于是攻击者会并发大量的这样的请求,把服务器端的资源耗尽。(关于这方面的攻击,大家可以移步看一下Wikipedia的SockStress词条)
另外,Wireshark中,你可以使用tcp.analysis.zero_window来过滤包,然后使用右键菜单里的follow TCP stream,你可以看到ZeroWindowProbe及ZeroWindowProbeAck的包。
7.6.2 Silly Window Syndrome
Silly Window Syndrome翻译成中文就是“糊涂窗口综合症”。正如你上面看到的一样,如果我们的接收方太忙了,来不及取走Receive Windows里的数据,那么,就会导致发送方越来越小。到最后,如果接收方腾出几个字节并告诉发送方现在有几个字节的window,而我们的发送方会义无反顾地发送这几个字节。
要知道,我们的TCP+IP头有40个字节,为了几个字节,要达上这么大的开销,这太不经济了。
另外,你需要知道网络上有个MTU,对于以太网来说,MTU是1500字节,除去TCP+IP头的40个字节,真正的数据传输可以有1460,这就是所谓的MSS(Max Segment Size)注意,TCP的RFC定义这个MSS的默认值是536,这是因为 RFC 791里说了任何一个IP设备都得最少接收576尺寸的大小(实际上来说576是拨号的网络的MTU,而576减去IP头的20个字节就是536)。
如果你的网络包可以塞满MTU,那么你可以用满整个带宽,如果不能,那么你就会浪费带宽。(大于MTU的包有两种结局,一种是直接被丢了,另一种是会被重新分块打包发送) 你可以想像成一个MTU就相当于一个飞机的最多可以装的人,如果这飞机里满载的话,带宽最高,如果一个飞机只运一个人的话,无疑成本增加了,也而相当二。
所以,Silly Windows Syndrome这个现像就像是你本来可以坐200人的飞机里只做了一两个人。 要解决这个问题也不难,就是避免对小的window size做出响应,直到有足够大的window size再响应,这个思路可以同时实现在sender和receiver两端。
如果这个问题是由Receiver端引起的,那么就会使用 David D Clark’s 方案。在receiver端,如果收到的数据导致window size小于某个值,可以直接ack(0)回sender,这样就把window给关闭了,也阻止了sender再发数据过来,等到receiver端处理了一些数据后windows size 大于等于了MSS,或者,receiver buffer有一半为空,就可以把window打开让send 发送数据过来。
如果这个问题是由Sender端引起的,那么就会使用著名的 Nagle’s algorithm。这个算法的思路也是延时处理,他有两个主要的条件:1)要等到 Window Size>=MSS 或是 Data Size >=MSS,2)收到之前发送数据的ack回包,他才会发数据,否则就是在攒数据。
另外,Nagle算法默认是打开的,所以,对于一些需要小包场景的程序——比如像telnet或ssh这样的交互性比较强的程序,你需要关闭这个算法。你可以在Socket设置TCP_NODELAY选项来关闭这个算法(关闭Nagle算法没有全局参数,需要根据每个应用自己的特点来关闭)
1 | setsockopt(sock_fd, IPPROTO_TCP, TCP_NODELAY, (**char** *)&value,sizeof(**int**)); |
另外,网上有些文章说TCP_CORK的socket option是也关闭Nagle算法,这不对。TCP_CORK其实是更新激进的Nagle算法,完全禁止小包发送,而Nagle算法没有禁止小包发送,只是禁止了大量的小包发送。最好不要两个选项都设置。
7.7 TCP的拥塞处理 – Congestion Handling
上面我们知道了,TCP通过Sliding Window来做流控(Flow Control),但是TCP觉得这还不够,因为Sliding Window需要依赖于连接的发送端和接收端,其并不知道网络中间发生了什么。TCP的设计者觉得,一个伟大而牛逼的协议仅仅做到流控并不够,因为流控只是网络模型4层以上的事,TCP的还应该更聪明地知道整个网络上的事。
具体一点,我们知道TCP通过一个timer采样了RTT并计算RTO,但是,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,但是,重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,于是,这个情况就会进入恶性循环被不断地放大。试想一下,如果一个网络内有成千上万的TCP连接都这么行事,那么马上就会形成“网络风暴”,TCP这个协议就会拖垮整个网络。这是一个灾难。
所以,TCP不能忽略网络上发生的事情,而无脑地一个劲地重发数据,对网络造成更大的伤害。对此TCP的设计理念是:TCP不是一个自私的协议,当拥塞发生的时候,要做自我牺牲。就像交通阻塞一样,每个车都应该把路让出来,而不要再去抢路了。
关于拥塞控制的论文请参看《Congestion Avoidance and Control》(PDF)
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。这四个算法不是一天都搞出来的,这个四算法的发展经历了很多时间,到今天都还在优化中。 备注:
- 1988年,TCP-Tahoe 提出了1)慢启动,2)拥塞避免,3)拥塞发生时的快速重传
- 1990年,TCP Reno 在Tahoe的基础上增加了4)快速恢复
7.7.1 慢热启动算法 – Slow Start
首先,我们来看一下TCP的慢热启动。慢启动的意思是,刚刚加入网络的连接,一点一点地提速,不要一上来就像那些特权车一样霸道地把路占满。新同学上高速还是要慢一点,不要把已经在高速上的秩序给搞乱了。
慢启动的算法如下(cwnd全称Congestion Window):
1)连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
2)每当收到一个ACK,cwnd++; 呈线性上升
3)每当过了一个RTT,cwnd = cwnd*2; 呈指数上升
4)还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”(后面会说这个算法)
所以,我们可以看到,如果网速很快的话,ACK也会返回得快,RTT也会短,那么,这个慢启动就一点也不慢。下图说明了这个过程。
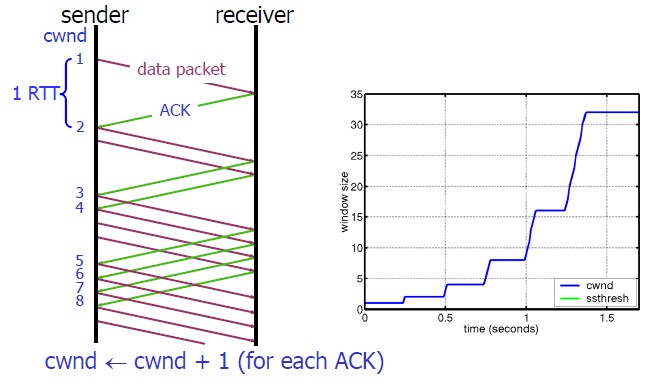
这里,我需要提一下的是一篇Google的论文《An Argument for Increasing TCP’s Initial Congestion Window》Linux 3.0后采用了这篇论文的建议——把cwnd 初始化成了 10个MSS。 而Linux 3.0以前,比如2.6,Linux采用了RFC3390,cwnd是跟MSS的值来变的,如果MSS< 1095,则cwnd = 4;如果MSS>2190,则cwnd=2;其它情况下,则是3。
7.7.2 拥塞避免算法 – Congestion Avoidance
前面说过,还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”。一般来说ssthresh的值是65535,单位是字节,当cwnd达到这个值时后,算法如下:
1)收到一个ACK时,cwnd = cwnd + 1/cwnd
2)当每过一个RTT时,cwnd = cwnd + 1
这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。很明显,是一个线性上升的算法。
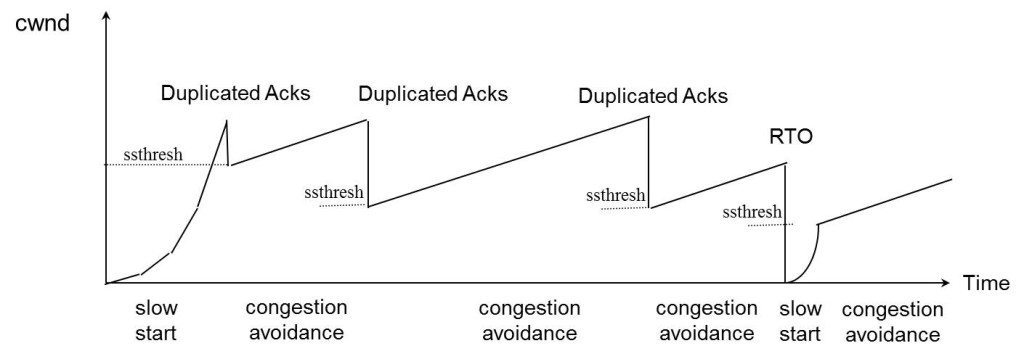
7.7.3 拥塞状态时的算法
前面我们说过,当丢包的时候,会有两种情况:
1)等到RTO超时,重传数据包。TCP认为这种情况太糟糕,反应也很强烈。
- sshthresh = cwnd /2
- cwnd 重置为 1
- 进入慢启动过程
2)Fast Retransmit算法,也就是在收到3个duplicate ACK时就开启重传,而不用等到RTO超时。
TCP Tahoe的实现和RTO超时一样。
TCP Reno的实现是:
- cwnd = cwnd /2
- sshthresh = cwnd
- 进入快速恢复算法——Fast Recovery
上面我们可以看到RTO超时后,sshthresh会变成cwnd的一半,这意味着,如果cwnd<=sshthresh时出现的丢包,那么TCP的sshthresh就会减了一半,然后等cwnd又很快地以指数级增涨爬到这个地方时,就会成慢慢的线性增涨。我们可以看到,TCP是怎么通过这种强烈地震荡快速而小心得找到网站流量的平衡点的。
7.7.4 快速恢复算法 – Fast Recovery
TCP Reno
这个算法定义在RFC5681。快速重传和快速恢复算法一般同时使用。快速恢复算法是认为,你还有3个Duplicated Acks说明网络也不那么糟糕,所以没有必要像RTO超时那么强烈。 注意,正如前面所说,进入Fast Recovery之前,cwnd 和 sshthresh已被更新:
- cwnd = cwnd /2
- sshthresh = cwnd
然后,真正的Fast Recovery算法如下:
- cwnd = sshthresh + 3 * MSS (3的意思是确认有3个数据包被收到了)
- 重传Duplicated ACKs指定的数据包
- 如果再收到 duplicated Acks,那么cwnd = cwnd +1
- 如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法了。
如果你仔细思考一下上面的这个算法,你就会知道,上面这个算法也有问题,那就是——它依赖于3个重复的Acks。注意,3个重复的Acks并不代表只丢了一个数据包,很有可能是丢了好多包。但这个算法只会重传一个,而剩下的那些包只能等到RTO超时,于是,进入了恶梦模式——超时一个窗口就减半一下,多个超时会超成TCP的传输速度呈级数下降,而且也不会触发Fast Recovery算法了。
通常来说,正如我们前面所说的,SACK或D-SACK的方法可以让Fast Recovery或Sender在做决定时更聪明一些,但是并不是所有的TCP的实现都支持SACK(SACK需要两端都支持),所以,需要一个没有SACK的解决方案。而通过SACK进行拥塞控制的算法是FACK(后面会讲)
TCP New Reno
于是,1995年,TCP New Reno(参见 RFC 6582 )算法提出来,主要就是在没有SACK的支持下改进Fast Recovery算法的——
当sender这边收到了3个Duplicated Acks,进入Fast Retransimit模式,开发重传重复Acks指示的那个包。如果只有这一个包丢了,那么,重传这个包后回来的Ack会把整个已经被sender传输出去的数据ack回来。如果没有的话,说明有多个包丢了。我们叫这个ACK为Partial ACK。
一旦Sender这边发现了Partial ACK出现,那么,sender就可以推理出来有多个包被丢了,于是乎继续重传sliding window里未被ack的第一个包。直到再也收不到了Partial Ack,才真正结束Fast Recovery这个过程
我们可以看到,这个“Fast Recovery的变更”是一个非常激进的玩法,他同时延长了Fast Retransmit和Fast Recovery的过程。
算法示意图
下面我们来看一个简单的图示以同时看一下上面的各种算法的样子:
FACK算法
FACK全称Forward Acknowledgment 算法,论文地址在这里(PDF)Forward Acknowledgement: Refining TCP Congestion Control 这个算法是其于SACK的,前面我们说过SACK是使用了TCP扩展字段Ack了有哪些数据收到,哪些数据没有收到,他比Fast Retransmit的3 个duplicated acks好处在于,前者只知道有包丢了,不知道是一个还是多个,而SACK可以准确的知道有哪些包丢了。 所以,SACK可以让发送端这边在重传过程中,把那些丢掉的包重传,而不是一个一个的传,但这样的一来,如果重传的包数据比较多的话,又会导致本来就很忙的网络就更忙了。所以,FACK用来做重传过程中的拥塞流控。
这个算法会把SACK中最大的Sequence Number 保存在snd.fack这个变量中,snd.fack的更新由ack带秋,如果网络一切安好则和snd.una一样(snd.una就是还没有收到ack的地方,也就是前面sliding window里的category #2的第一个地方)
然后定义一个awnd = snd.nxt – snd.fack(snd.nxt指向发送端sliding window中正在要被发送的地方——前面sliding windows图示的category#3第一个位置),这样awnd的意思就是在网络上的数据。(所谓awnd意为:actual quantity of data outstanding in the network)
如果需要重传数据,那么,awnd = snd.nxt – snd.fack + retran_data,也就是说,awnd是传出去的数据 + 重传的数据。
然后触发Fast Recovery 的条件是: ( ( snd.fack – snd.una ) > (3*MSS) ) || (dupacks == 3) ) 。这样一来,就不需要等到3个duplicated acks才重传,而是只要sack中的最大的一个数据和ack的数据比较长了(3个MSS),那就触发重传。在整个重传过程中cwnd不变。直到当第一次丢包的snd.nxt<=snd.una(也就是重传的数据都被确认了),然后进来拥塞避免机制——cwnd线性上涨。
我们可以看到如果没有FACK在,那么在丢包比较多的情况下,原来保守的算法会低估了需要使用的window的大小,而需要几个RTT的时间才会完成恢复,而FACK会比较激进地来干这事。 但是,FACK如果在一个网络包会被 reordering的网络里会有很大的问题。
7.7.5 其它拥塞控制算法简介
TCP Vegas 拥塞控制算法
这个算法1994年被提出,它主要对TCP Reno 做了些修改。这个算法通过对RTT的非常重的监控来计算一个基准RTT。然后通过这个基准RTT来估计当前的网络实际带宽,如果实际带宽比我们的期望的带宽要小或是要多的活,那么就开始线性地减少或增加cwnd的大小。如果这个计算出来的RTT大于了Timeout后,那么,不等ack超时就直接重传。(Vegas 的核心思想是用RTT的值来影响拥塞窗口,而不是通过丢包) 这个算法的论文是《TCP Vegas: End to End Congestion Avoidance on a Global Internet》这篇论文给了Vegas和 New Reno的对比:
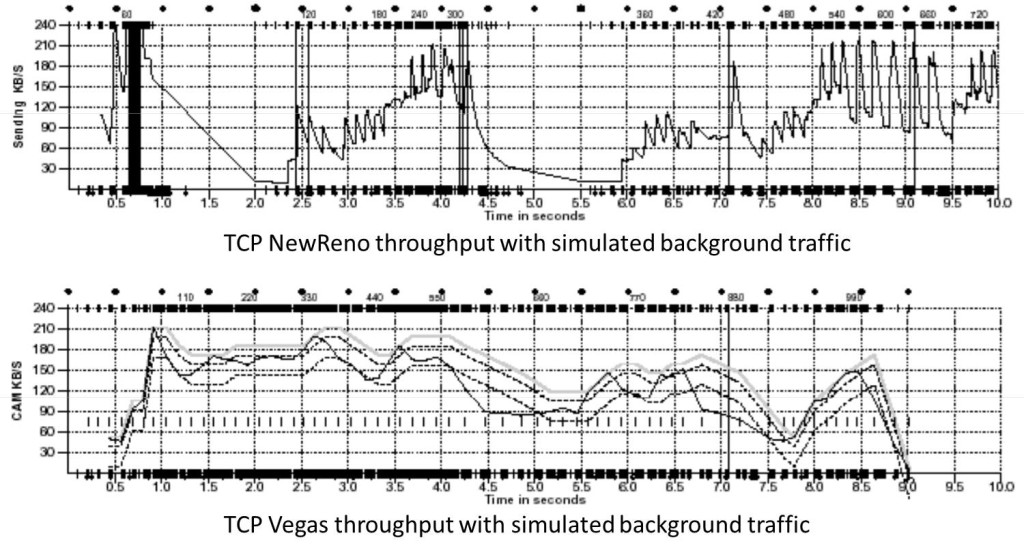
关于这个算法实现,你可以参看Linux源码:/net/ipv4/tcp_vegas.h, /net/ipv4/tcp_vegas.c
HSTCP(High Speed TCP) 算法
这个算法来自RFC 3649(Wikipedia词条)。其对最基础的算法进行了更改,他使得Congestion Window涨得快,减得慢。其中:
- 拥塞避免时的窗口增长方式: cwnd = cwnd + α(cwnd) / cwnd
- 丢包后窗口下降方式:cwnd = (1- β(cwnd))*cwnd
注:α(cwnd)和β(cwnd)都是函数,如果你要让他们和标准的TCP一样,那么让α(cwnd)=1,β(cwnd)=0.5就可以了。 对于α(cwnd)和β(cwnd)的值是个动态的变换的东西。 关于这个算法的实现,你可以参看Linux源码:/net/ipv4/tcp_highspeed.c
TCP BIC 算法
2004年,产内出BIC算法。现在你还可以查得到相关的新闻《Google:美科学家研发BIC-TCP协议 速度是DSL六千倍》 BIC全称Binary Increase Congestion control,在Linux 2.6.8中是默认拥塞控制算法。BIC的发明者发这么多的拥塞控制算法都在努力找一个合适的cwnd – Congestion Window,而且BIC-TCP的提出者们看穿了事情的本质,其实这就是一个搜索的过程,所以BIC这个算法主要用的是Binary Search——二分查找来干这个事。 关于这个算法实现,你可以参看Linux源码:/net/ipv4/tcp_bic.c
TCP WestWood算法
westwood采用和Reno相同的慢启动算法、拥塞避免算法。westwood的主要改进方面:在发送端做带宽估计,当探测到丢包时,根据带宽值来设置拥塞窗口、慢启动阈值。 那么,这个算法是怎么测量带宽的?每个RTT时间,会测量一次带宽,测量带宽的公式很简单,就是这段RTT内成功被ack了多少字节。因为,这个带宽和用RTT计算RTO一样,也是需要从每个样本来平滑到一个值的——也是用一个加权移平均的公式。 另外,我们知道,如果一个网络的带宽是每秒可以发送X个字节,而RTT是一个数据发出去后确认需要的时候,所以,X * RTT应该是我们缓冲区大小。所以,在这个算法中,ssthresh的值就是est_BD * min-RTT(最小的RTT值),如果丢包是Duplicated ACKs引起的,那么如果cwnd > ssthresh,则 cwin = ssthresh。如果是RTO引起的,cwnd = 1,进入慢启动。 关于这个算法实现,你可以参看Linux源码: /net/ipv4/tcp_westwood.c
其它
更多的算法,你可以从Wikipedia的 TCP Congestion Avoidance Algorithm 词条中找到相关的线索
8.UDP
UDP数据报
8.1 UDP的概述(User Datagram Protocol,用户数据报协议)
UDP是传输层的协议,功能即为在IP的数据报服务之上增加了最基本的服务:复用和分用以及差错检测。
UDP提供不可靠服务,具有TCP所没有的优势:
- UDP无连接,时间上不存在建立连接需要的时延。空间上,TCP需要在端系统中维护连接状态,需要一定的开销。此连接装入包括接收和发送缓存,拥塞控制参数和序号与确认号的参数。UCP不维护连接状态,也不跟踪这些参数,开销小。空间和时间上都具有优势。
举个例子:
DNS如果运行在TCP之上而不是UDP,那么DNS的速度将会慢很多。
HTTP使用TCP而不是UDP,是因为对于基于文本数据的Web网页来说,可靠性很重要。
同一种专用应用服务器在支持UDP时,一定能支持更多的活动客户机。 - 分组首部开销小**,TCP首部20字节,UDP首部8字节。
- UDP没有拥塞控制,应用层能够更好的控制要发送的数据和发送时间,网络中的拥塞控制也不会影响主机的发送速率。某些实时应用要求以稳定的速度发送,能容 忍一些数据的丢失,但是不能允许有较大的时延(比如实时视频,直播等)
- UDP提供尽最大努力的交付,不保证可靠交付。所有维护传输可靠性的工作需要用户在应用层来完成。没有TCP的确认机制、重传机制。如果因为网络原因没有传送到对端,UDP也不会给应用层返回错误信息
- UDP是面向报文的,对应用层交下来的报文,添加首部后直接乡下交付为IP层,既不合并,也不拆分,保留这些报文的边界。对IP层交上来UDP用户数据报,在去除首部后就原封不动地交付给上层应用进程,报文不可分割,是UDP数据报处理的最小单位。
正是因为这样,UDP显得不够灵活,不能控制读写数据的次数和数量。比如我们要发送100个字节的报文,我们调用一次sendto函数就会发送100字节,对端也需要用recvfrom函数一次性接收100字节,不能使用循环每次获取10个字节,获取十次这样的做法。 - UDP常用一次性传输比较少量数据的网络应用,如DNS,SNMP等,因为对于这些应用,若是采用TCP,为连接的创建,维护和拆除带来不小的开销。UDP也常用于多媒体应用(如IP电话,实时视频会议,流媒体等)数据的可靠传输对他们而言并不重要,TCP的拥塞控制会使他们有较大的延迟,也是不可容忍的
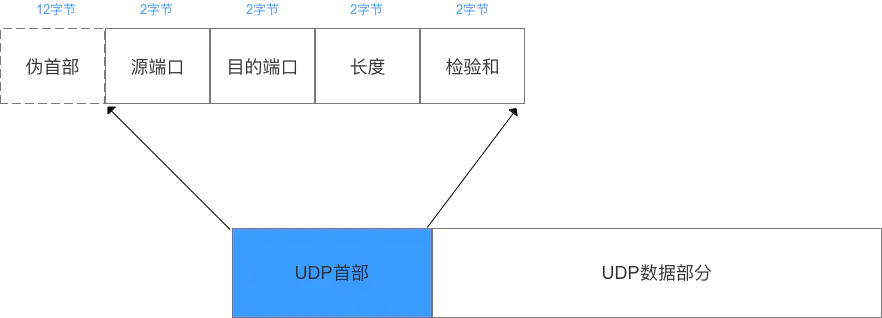
8.2 UDP的首部格式
UDP数据报分为首部和用户数据部分,整个UDP数据报作为IP数据报的数据部分封装在IP数据报中,UDP数据报文结构如图所示:
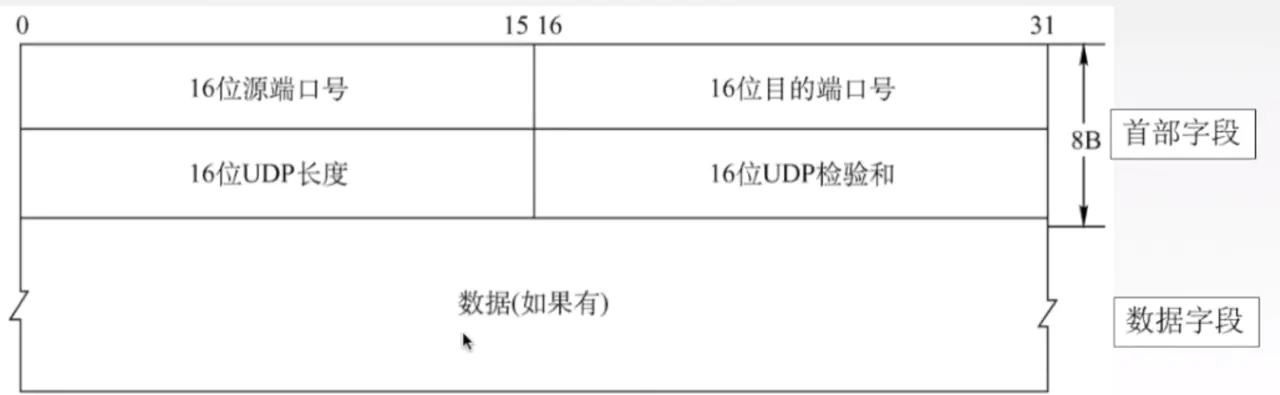
UDP首部有8个字节,由4个字段构成,每个字段都是两个字节,
1.源端口: 源端口号,需要对方回信时选用,不需要时全部置0.
2.目的端口:目的端口号,在终点交付报文的时候需要用到。
3.长度:UDP的数据报的长度(包括首部和数据)其最小值为8(只有首部)
4.校验和:检测UDP数据报在传输中是否有错,有错则丢弃。
该字段是可选的,当源主机不想计算校验和,则直接令该字段全为0.
当传输层从IP层收到UDP数据报时,就根据首部中的目的端口,把UDP数据报通过相应的端口,上交给应用进程。
如果接收方UDP发现收到的报文中的目的端口号不正确(不存在对应端口号的应用进程0,),就丢弃该报文,并由ICMP发送“端口不可达”差错报文给对方。
UDP校验
在计算校验和的时候,需要在UDP数据报之前增加12字节的伪首部,伪首部并不是UDP真正的首部。只是在计算校验和,临时添加在UDP数据报的前面,得到一个临时的UDP数据报。校验和就是按照这个临时的UDP数据报计算的。伪首部既不向下传送也不向上递交,而仅仅是为了计算校验和。这样的校验和,既检查了UDP数据报,又对IP数据报的源IP地址和目的IP地址进行了检验。
UDP校验和的计算方法和IP数据报首部校验和的计算方法相似,都使用二进制反码运算求和再取反,但不同的是:IP数据报的校验和之检验IP数据报和首部,但UDP的校验和是把首部和数据部分一起校验。
发送方,首先是把全零放入校验和字段并且添加伪首部,然后把UDP数据报看成是由许多16位的子串连接起来,若UDP数据报的数据部分不是偶数个字节,则要在数据部分末尾增加一个全零字节(此字节不发送),接下来就按照二进制反码计算出这些16位字的和。将此和的二进制反码写入校验和字段。在接收方,把收到得UDP数据报加上伪首部(如果不为偶数个字节,还需要补上全零字节)后,按二进制反码计算出这些16位字的和。当无差错时其结果全为1,。否则就表明有差错出现,接收方应该丢弃这个UDP数据报。

注意:
1.校验时,若UDP数据报部分的长度不是偶数个字节,则需要填入一个全0字节,但是次字节和伪首部一样,是不发送的。
2.如果UDP校验和校验出UDP数据报是错误的,可以丢弃,也可以交付上层,但是要附上错误报告,告诉上层这是错误的数据报。
3.通过伪首部,不仅可以检查源端口号,目的端口号和UDP用户数据报的数据部分,还可以检查IP数据报的源IP地址和目的地址。
这种差错检验的检错能力不强,但是简单,速度快