javascript基本知识,建议有一定基础,再阅读过《JavaScript高级程序设计》(俗称红宝书)的基础上之后进行阅读,开始准备面试吧,初战不利,更应该多刷面经,多背基础,毕竟是实习和校招,基础要夯实,推荐观看 冴羽的博客 ,内容丰富,适合有一定JS基础的人进行阅读
1.原型链
1.1 构造函数创建对象
我们先使用构造函数创建一个对象:
1 | function Person() { |
在这个例子中,Person 就是一个构造函数,我们使用 new 创建了一个实例对象 person。
1.2 prototype
每个构造函数都有一个 prototype 属性 ,比如:
1 | function Person() { |
那这个函数的 prototype 属性到底指向的是什么呢?是这个函数的原型吗?
其实,函数的 prototype 属性指向了一个对象,这个对象正是调用该构造函数而创建的实例的原型,也就是这个例子中的 person1 和 person2 的原型。
那什么是原型呢?你可以这样理解:每一个JavaScript对象(null除外)在创建的时候就会与之关联另一个对象,这个对象就是我们所说的原型,每一个对象都会从原型”继承”属性。
让我们用一张图表示构造函数和实例原型之间的关系:

在这张图中我们用 Object.prototype 表示实例原型。
那么我们该怎么表示实例与实例原型,也就是 person 和 Person.prototype 之间的关系呢,这时候我们就要讲到第二个属性:
1.3 __proto__
这是每一个JavaScript对象(除了 null )都具有的一个属性,叫__proto__,这个属性会指向该对象的原型。
为了证明这一点,我们可以在Firefox或者Chrome中控制台输入:
1 | function Person() { |
于是我们更新下关系图:

既然实例对象和构造函数都可以指向原型,那么原型是否有属性指向构造函数或者实例呢?
1.4 constructor
指向实例倒是没有,因为同一个构造函数可以生成多个实例,但是原型指向构造函数倒是有的,这就要讲到第三个属性:constructor,每个原型都有一个 constructor 属性指向关联的构造函数。
为了验证这一点,我们可以尝试:
1 | function Person() { |
所以再更新下关系图:

综上我们已经得出:
1 | function Person() { |
了解了构造函数、实例原型、和实例之间的关系,接下来我们讲讲实例和原型的关系:
1.5 实例与原型
当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止。
举个例子:
1 | function Person() { |
在这个例子中,我们给实例对象 person 添加了 name 属性,当我们打印 person.name 的时候,结果自然为 Daisy。
但是当我们删除了 person 的 name 属性时,读取 person.name,从 person 对象中找不到 name 属性就会从 person 的原型也就是 person.__proto__ ,也就是 Person.prototype中查找,幸运的是我们找到了 name 属性,结果为 Kevin。
但是万一还没有找到呢?原型的原型又是什么呢?
1.6 原型的原型
在前面,我们已经讲了原型也是一个对象,既然是对象,我们就可以用最原始的方式创建它,那就是:
1 | var obj = new Object(); |
其实原型对象就是通过 Object 构造函数生成的,结合之前所讲,实例的 proto 指向构造函数的 prototype ,所以我们再更新下关系图:

1.7 原型链
那 Object.prototype 的原型呢?
null,我们可以打印:
1 | console.log(Object.prototype.__proto__ === null) // true |
然而 null 究竟代表了什么呢?
引用阮一峰老师的 《undefined与null的区别》 就是:
null 表示“没有对象”,即该处不应该有值。
所以 Object.prototype.__proto__ 的值为 null 就是 Object.prototype 没有原型,表达了同一个意思。
所以查找属性的时候查到 Object.prototype 就可以停止查找了。
最后一张关系图也可以更新为:

顺便还要说一下,图中由相互关联的原型组成的链状结构就是原型链,也就是蓝色的这条线。
补充
最后,补充三点大家可能不会注意的地方:
constructor
首先是 constructor 属性,我们看个例子:
1 | function Person() { |
当获取 person.constructor 时,其实 person 中并没有 constructor 属性,当不能读取到constructor 属性时,会从 person 的原型也就是 Person.prototype 中读取,正好原型中有该属性,所以:
1 | person.constructor === Person.prototype.constructor |
__proto__
其次是 __proto__ ,绝大部分浏览器都支持这个非标准的方法访问原型,然而它并不存在于 Person.prototype 中,实际上,它是来自于 Object.prototype ,与其说是一个属性,不如说是一个 getter/setter,当使用 obj.proto 时,可以理解成返回了 Object.getPrototypeOf(obj)。
真的是继承吗?
最后是关于继承,前面我们讲到“每一个对象都会从原型‘继承’属性”,实际上,继承是一个十分具有迷惑性的说法,引用《你不知道的JavaScript》中的话,就是:
继承意味着复制操作,然而 JavaScript 默认并不会复制对象的属性,相反,JavaScript 只是在两个对象之间创建一个关联,这样,一个对象就可以通过委托访问另一个对象的属性和函数,所以与其叫继承,委托的说法反而更准确些。
2.继承
2.1 原型链继承
1 | function Parent () { |
缺点:
1.引用类型的属性被所有实例共享,举个例子:
1 | function Parent () { |
2.在创建 Child 的实例时,不能向Parent传参
2.2 借用构造函数(经典继承)
1 | function Parent () { |
优点:
1.避免了引用类型的属性被所有实例共享
2.可以在 Child 中向 Parent 传参
举个例子:
1 | function Parent (name) { |
缺点:
方法都在构造函数中定义每个子类实例不能共享父函数,浪费内存,开销较大。不能继承父类原型。
2.3 组合继承
原型链继承和经典继承双剑合璧。
1 | function Parent (name) { |
优点:融合原型链继承和构造函数的优点,是 JavaScript 中最常用的继承模式。
缺点:Parent的构造函数会多执行了一次
2.4 原型式继承
1 | function createObj(o) { |
就是 ES5 Object.create 的模拟实现,将传入的对象作为创建的对象的原型。
缺点:包含引用类型的属性值始终都会共享相应的值,这点跟原型链继承一样。
1 | var person = { |
注意:修改person1.name的值,person2.name的值并未发生改变,并不是因为person1和person2有独立的 name 值,而是因为person1.name = 'person1',给person1添加了 name 值,并非修改了原型上的 name 值。
2.5 寄生式继承
创建一个仅用于封装继承过程的函数,该函数在内部以某种形式来做增强对象,最后返回对象。
1 | function createObj (o) { |
缺点:跟借用构造函数模式一样,每次创建对象都会创建一遍方法。
2.6 寄生组合式继承
为了方便大家阅读,在这里重复一下组合继承的代码:
1 | function Parent (name) { |
组合继承最大的缺点是会调用两次父构造函数。
一次是设置子类型实例的原型的时候:
1 | Child.prototype = new Parent(); |
一次在创建子类型实例的时候:
1 | var child1 = new Child('kevin', '18'); |
回想下 new 的模拟实现,其实在这句中,我们会执行:
1 | Parent.call(this, name); |
在这里,我们又会调用了一次 Parent 构造函数。
所以,在这个例子中,如果我们打印 child1 对象,我们会发现 Child.prototype 和 child1 都有一个属性为colors,属性值为['red', 'blue', 'green']。
那么我们该如何精益求精,避免这一次重复调用呢?
如果我们不使用 Child.prototype = new Parent() ,而是间接的让 Child.prototype 访问到 Parent.prototype 呢?
看看如何实现:
1 | function Parent (name) { |
最后我们封装一下这个继承方法:
1 | function object(o) { |
引用《JavaScript高级程序设计》中对寄生组合式继承的夸赞就是:
这种方式的高效率体现它只调用了一次 Parent 构造函数,并且因此避免了在 Parent.prototype 上面创建不必要的、多余的属性。与此同时,原型链还能保持不变;因此,还能够正常使用 instanceof 和 isPrototypeOf。开发人员普遍认为寄生组合式继承是引用类型最理想的继承范式。
3.作用域链
3.1 定义
当查找变量的时候,会先从当前上下文的变量对象中查找,如果没有找到,就会从父级(词法层面上的父级)执行上下文的变量对象中查找,一直找到全局上下文的变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的链表就叫做作用域链。
下面,让我们以一个函数的创建和激活两个时期来讲解作用域链是如何创建和变化的。
3.2 函数创建
函数的作用域在函数定义的时候就决定了,这是因为函数有一个内部属性 [[scope]],当函数创建的时候,就会保存所有父变量对象到其中,你可以理解 [[scope]] 就是所有父变量对象的层级链,但是注意:[[scope]] 并不代表完整的作用域链!
举个例子:
1 | function foo() { |
函数创建时,各自的[[scope]]为:
1 | foo.[[scope]] = [ |
3.3 函数激活
当函数激活时,进入函数上下文,创建 VO/AO 后,就会将活动对象添加到作用链的前端。
这时候执行上下文的作用域链,我们命名为 Scope:
1 | Scope = [AO].concat([[Scope]]); |
至此,作用域链创建完毕。
3.4 按照步骤分析
以下面的例子为例,结合着之前讲的变量对象和执行上下文栈,我们来总结一下函数执行上下文中作用域链和变量对象的创建过程:
1 | var scope = "global scope"; |
执行过程如下:
1.checkscope 函数被创建,保存作用域链到 内部属性[[scope]]
1 | checkscope.[[scope]] = [ |
2.执行 checkscope 函数,创建 checkscope 函数执行上下文,checkscope 函数执行上下文被压入执行上下文栈
1 | ECStack = [ |
3.checkscope 函数并不立刻执行,开始做准备工作,第一步:复制函数[[scope]]属性创建作用域链
1 | checkscopeContext = { |
4.第二步:用 arguments 创建活动对象,随后初始化活动对象,加入形参、函数声明、变量声明
1 | checkscopeContext = { |
5.第三步:将活动对象压入 checkscope 作用域链顶端
1 | checkscopeContext = { |
6.准备工作做完,开始执行函数,随着函数的执行,修改 AO 的属性值
1 | checkscopeContext = { |
7.查找到 scope2 的值,返回后函数执行完毕,函数上下文从执行上下文栈中弹出
1 | ECStack = [ |
4.闭包
4.1 定义
MDN 对闭包的定义为:
闭包是指那些能够访问自由变量的函数。
那什么是自由变量呢?
自由变量是指在函数中使用的,但既不是函数参数也不是函数的局部变量的变量。
由此,我们可以看出闭包共有两部分组成:
闭包 = 函数 + 函数能够访问的自由变量
举个例子:
1 | var a = 1; |
foo 函数可以访问变量 a,但是 a 既不是 foo 函数的局部变量,也不是 foo 函数的参数,所以 a 就是自由变量。
那么,函数 foo + foo 函数访问的自由变量 a 不就是构成了一个闭包嘛……
还真是这样的!
所以在《JavaScript权威指南》中就讲到:从技术的角度讲,所有的JavaScript函数都是闭包。因为它们都在创建的时候就将上层上下文的数据保存起来了。哪怕是简单的全局变量也是如此,因为函数中访问全局变量就相当于是在访问自由变量,这个时候使用最外层的作用域。
这只是理论上的闭包,其实还有一个实践角度上的闭包,让我们看看汤姆大叔翻译的关于闭包的文章中的定义:
ECMAScript中,从实践角度,以下函数才算是闭包:
1.即使创建它的上下文已经销毁,它仍然存在(比如,内部函数从父函数中返回)
2.在代码中引用了自由变量
接下来就来讲讲实践上的闭包。
4.2 分析
让我们先写个例子,例子依然是来自《JavaScript权威指南》,稍微做点改动:
1 | var scope = "global scope"; |
首先我们要分析一下这段代码中执行上下文栈和执行上下文的变化情况。
这里直接给出简要的执行过程:
- 进入全局代码,创建全局执行上下文,全局执行上下文压入执行上下文栈
- 全局执行上下文初始化
- 执行 checkscope 函数,创建 checkscope 函数执行上下文,checkscope 执行上下文被压入执行上下文栈
- checkscope 执行上下文初始化,创建变量对象、作用域链、this等
- checkscope 函数执行完毕,checkscope 执行上下文从执行上下文栈中弹出
- 执行 f 函数,创建 f 函数执行上下文,f 执行上下文被压入执行上下文栈
- f 执行上下文初始化,创建变量对象、作用域链、this等
- f 函数执行完毕,f 函数上下文从执行上下文栈中弹出
了解到这个过程,我们应该思考一个问题,那就是:
当 f 函数执行的时候,checkscope 函数上下文已经被销毁了啊(即从执行上下文栈中被弹出),怎么还会读取到 checkscope 作用域下的 scope 值呢?
以上的代码,要是转换成 PHP,就会报错,因为在 PHP 中,f 函数只能读取到自己作用域和全局作用域里的值,所以读不到 checkscope 下的 scope 值。(这段我问的PHP同事……)
然而 JavaScript 却是可以的!
当我们了解了具体的执行过程后,我们知道 f 执行上下文维护了一个作用域链:
1 | fContext = { |
对的,就是因为这个作用域链,f 函数依然可以读取到 checkscopeContext.AO 的值,说明当 f 函数引用了 checkscopeContext.AO 中的值的时候,即使 checkscopeContext 被销毁了,但是 JavaScript 依然会让 checkscopeContext.AO 活在内存中,f 函数依然可以通过 f 函数的作用域链找到它,正是因为 JavaScript 做到了这一点,从而实现了闭包这个概念。
所以,让我们再看一遍实践角度上闭包的定义:
- 即使创建它的上下文已经销毁,它仍然存在(比如,内部函数从父函数中返回)
- 在代码中引用了自由变量
在这里再补充一个《JavaScript权威指南》英文原版对闭包的定义:
This combination of a function object and a scope (a set of variable bindings) in which the function’s variables are resolved is called a closure in the computer science literature.
闭包在计算机科学中也只是一个普通的概念,大家不要去想得太复杂。
4.3 必刷题
接下来,看这道刷题必刷,面试必考的闭包题:
1 | var data = []; |
答案是都是 3,让我们分析一下原因:
当执行到 data[0] 函数之前,此时全局上下文的 VO 为:
1 | globalContext = { |
当执行 data[0] 函数的时候,data[0] 函数的作用域链为:
1 | data[0]Context = { |
data[0]Context 的 AO 并没有 i 值,所以会从 globalContext.VO 中查找,i 为 3,所以打印的结果就是 3。
data[1] 和 data[2] 是一样的道理。
所以让我们改成闭包看看:
1 | var data = []; |
当执行到 data[0] 函数之前,此时全局上下文的 VO 为:
1 | globalContext = { |
跟没改之前一模一样。
当执行 data[0] 函数的时候,data[0] 函数的作用域链发生了改变:
1 | data[0]Context = { |
匿名函数执行上下文的AO为:
1 | 匿名函数Context = { |
data[0]Context 的 AO 并没有 i 值,所以会沿着作用域链从匿名函数 Context.AO 中查找,这时候就会找 i 为 0,找到了就不会往 globalContext.VO 中查找了,即使 globalContext.VO 也有 i 的值(值为3),所以打印的结果就是0。
data[1] 和 data[2] 是一样的道理。
5.变量对象
5.1 变量对象
变量对象是与执行上下文相关的数据作用域,存储了在上下文中定义的变量和函数声明。
因为不同执行上下文下的变量对象稍有不同,所以我们来聊聊全局上下文下的变量对象和函数上下文下的变量对象。
5.2 全局上下文
我们先了解一个概念,叫全局对象。在 W3School 中也有介绍:
全局对象是预定义的对象,作为 JavaScript 的全局函数和全局属性的占位符。通过使用全局对象,可以访问所有其他所有预定义的对象、函数和属性。
在顶层 JavaScript 代码中,可以用关键字 this 引用全局对象。因为全局对象是作用域链的头,这意味着所有非限定性的变量和函数名都会作为该对象的属性来查询。
例如,当JavaScript 代码引用 parseInt() 函数时,它引用的是全局对象的 parseInt 属性。全局对象是作用域链的头,还意味着在顶层 JavaScript 代码中声明的所有变量都将成为全局对象的属性。
如果看的不是很懂的话,容我再来介绍下全局对象:
1.可以通过 this 引用,在客户端 JavaScript 中,全局对象就是 Window 对象。
1 | console.log(this); |
2.全局对象是由 Object 构造函数实例化的一个对象。
1 | console.log(this instanceof Object); |
3.预定义了一堆,嗯,一大堆函数和属性。
1 | // 都能生效 |
4.作为全局变量的宿主。
1 | var a = 1; |
5.客户端 JavaScript 中,全局对象有 window 属性指向自身。
1 | var a = 1; |
花了一个大篇幅介绍全局对象,其实就想说:
全局上下文中的变量对象就是全局对象呐!
5.3 函数上下文
在函数上下文中,我们用活动对象(activation object, AO)来表示变量对象。
活动对象和变量对象其实是一个东西,只是变量对象是规范上的或者说是引擎实现上的,不可在 JavaScript 环境中访问,只有到当进入一个执行上下文中,这个执行上下文的变量对象才会被激活,所以才叫 activation object 呐,而只有被激活的变量对象,也就是活动对象上的各种属性才能被访问。
活动对象是在进入函数上下文时刻被创建的,它通过函数的 arguments 属性初始化。arguments 属性值是 Arguments 对象。
5.4 执行过程
执行上下文的代码会分成两个阶段进行处理:分析和执行,我们也可以叫做:
- 进入执行上下文
- 代码执行
5.4.1 进入执行上下文
当进入执行上下文时,这时候还没有执行代码,
变量对象会包括:
- 函数的所有形参 (如果是函数上下文)
- 由名称和对应值组成的一个变量对象的属性被创建
- 没有实参,属性值设为 undefined
- 函数声明
- 由名称和对应值(函数对象(function-object))组成一个变量对象的属性被创建
- 如果变量对象已经存在相同名称的属性,则完全替换这个属性
- 变量声明
- 由名称和对应值(undefined)组成一个变量对象的属性被创建;
- 如果变量名称跟已经声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性
举个例子:
1 | function foo(a) { |
在进入执行上下文后,这时候的 AO 是:
1 | AO = { |
5.4.2 代码执行
在代码执行阶段,会顺序执行代码,根据代码,修改变量对象的值
还是上面的例子,当代码执行完后,这时候的 AO 是:
1 | AO = { |
到这里变量对象的创建过程就介绍完了,让我们简洁的总结我们上述所说:
- 全局上下文的变量对象初始化是全局对象
- 函数上下文的变量对象初始化只包括 Arguments 对象
- 在进入执行上下文时会给变量对象添加形参、函数声明、变量声明等初始的属性值
- 在代码执行阶段,会再次修改变量对象的属性值
5.5 思考题
最后让我们看几个例子:
1.第一题
1 | function foo() { |
第一段会报错:Uncaught ReferenceError: a is not defined。
第二段会打印:1。
这是因为函数中的 “a” 并没有通过 var 关键字声明,所有不会被存放在 AO 中。
第一段执行 console 的时候, AO 的值是:
1 | AO = { |
没有 a 的值,然后就会到全局去找,全局也没有,所以会报错。
当第二段执行 console 的时候,全局对象已经被赋予了 a 属性,这时候就可以从全局找到 a 的值,所以会打印 1。
2.第二题
1 | console.log(foo); |
会打印函数,而不是 undefined 。
这是因为在进入执行上下文时,首先会处理函数声明,其次会处理变量声明,如果如果变量名称跟已经声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性。
6.从ECMAScript规范解读this
ECMAScript 5.1 规范地址:
英文版:http://es5.github.io/#x15.1
中文版:http://yanhaijing.com/es5/#115
让我们开始了解规范吧!
6.1 Types
首先是第 8 章 Types:
ECMAScript 的类型分为语言类型和规范类型。
ECMAScript 语言类型是开发者直接使用 ECMAScript 可以操作的。其实就是我们常说的Undefined, Null, Boolean, String, Number, 和 Object。
而规范类型相当于 meta-values,是用来用算法描述 ECMAScript 语言结构和 ECMAScript 语言类型的。规范类型包括:Reference, List, Completion, Property Descriptor, Property Identifier, Lexical Environment, 和 Environment Record。
没懂?没关系,我们只要知道在 ECMAScript 规范中还有一种只存在于规范中的类型,它们的作用是用来描述语言底层行为逻辑。
6.2 Reference
Reference 类型。它与 this 的指向有着密切的关联。
让我们看 8.7 章 The Reference Specification Type:
The Reference type is used to explain the behaviour of such operators as delete, typeof, and the assignment operators.
所以 Reference 类型就是用来解释诸如 delete、typeof 以及赋值等操作行为的。
抄袭尤雨溪大大的话,就是:
这里的 Reference 是一个 Specification Type,也就是 “只存在于规范里的抽象类型”。它们是为了更好地描述语言的底层行为逻辑才存在的,但并不存在于实际的 js 代码中。
再看接下来的这段具体介绍 Reference 的内容:
A Reference is a resolved name binding.
A Reference consists of three components, the base value, the referenced name and the Boolean valued strict reference flag.
The base value is either undefined, an Object, a Boolean, a String, a Number, or an environment record (10.2.1).
A base value of undefined indicates that the reference could not be resolved to a binding. The referenced name is a String.
这段讲述了 Reference 的构成,由三个组成部分,分别是:
- base value
- referenced name
- strict reference
可是这些到底是什么呢?
我们简单的理解的话:
base value 就是属性所在的对象或者就是 EnvironmentRecord,它的值只可能是 undefined, an Object, a Boolean, a String, a Number, or an environment record 其中的一种。
referenced name 就是属性的名称。
举个例子:
1 | var foo = 1; |
再举个例子:
1 | var foo = { |
而且规范中还提供了获取 Reference 组成部分的方法,比如 GetBase 和 IsPropertyReference。
这两个方法很简单,简单看一看:
1.GetBase
GetBase(V). Returns the base value component of the reference V.
返回 reference 的 base value。
2.IsPropertyReference
IsPropertyReference(V). Returns true if either the base value is an object or HasPrimitiveBase(V) is true; otherwise returns false.
简单的理解:如果 base value 是一个对象,就返回true。
6.3 GetValue
除此之外,紧接着在 8.7.1 章规范中就讲了一个用于从 Reference 类型获取对应值的方法: GetValue。
简单模拟 GetValue 的使用:
1 | var foo = 1; |
GetValue 返回对象属性真正的值,但是要注意:
调用 GetValue,返回的将是具体的值,而不再是一个 Reference
这个很重要,这个很重要,这个很重要。
6.4 如何确定this的值
关于 Reference 讲了那么多,为什么要讲 Reference 呢?到底 Reference 跟本文的主题 this 有哪些关联呢?如果你能耐心看完之前的内容,以下开始进入高能阶段:
看规范 11.2.3 Function Calls:
这里讲了当函数调用的时候,如何确定 this 的取值。
只看第一步、第六步、第七步:
1.Let ref be the result of evaluating MemberExpression.
6.If Type(ref) is Reference, then
7.Else, Type(ref) is not Reference.
让我们描述一下:
1.计算 MemberExpression 的结果赋值给 ref
2.判断 ref 是不是一个 Reference 类型
1 | 2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref) |
6.5 具体分析
让我们一步一步看:
- 计算 MemberExpression 的结果赋值给 ref
什么是 MemberExpression?看规范 11.2 Left-Hand-Side Expressions:
MemberExpression :
- PrimaryExpression // 原始表达式 可以参见《JavaScript权威指南第四章》
- FunctionExpression // 函数定义表达式
- MemberExpression [ Expression ] // 属性访问表达式
- MemberExpression . IdentifierName // 属性访问表达式
- new MemberExpression Arguments // 对象创建表达式
举个例子:
1 | function foo() { |
所以简单理解 MemberExpression 其实就是()左边的部分。
2.判断 ref 是不是一个 Reference 类型。
关键就在于看规范是如何处理各种 MemberExpression,返回的结果是不是一个Reference类型。
举最后一个例子:
1 | var value = 1; |
6.5.1 foo.bar()
在示例 1 中,MemberExpression 计算的结果是 foo.bar,那么 foo.bar 是不是一个 Reference 呢?
查看规范 11.2.1 Property Accessors,这里展示了一个计算的过程,什么都不管了,就看最后一步:
Return a value of type Reference whose base value is baseValue and whose referenced name is propertyNameString, and whose strict mode flag is strict.
我们得知该表达式返回了一个 Reference 类型!
根据之前的内容,我们知道该值为:
1 | var Reference = { |
接下来按照 2.1 的判断流程走:
2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref)
该值是 Reference 类型,那么 IsPropertyReference(ref) 的结果是多少呢?
前面我们已经铺垫了 IsPropertyReference 方法,如果 base value 是一个对象,结果返回 true。
base value 为 foo,是一个对象,所以 IsPropertyReference(ref) 结果为 true。
这个时候我们就可以确定 this 的值了:
1 | this = GetBase(ref), |
GetBase 也已经铺垫了,获得 base value 值,这个例子中就是foo,所以 this 的值就是 foo ,示例1的结果就是 2!
唉呀妈呀,为了证明 this 指向foo,真是累死我了!但是知道了原理,剩下的就更快了。
6.5.2 (foo.bar)()
看示例2:
1 | console.log((foo.bar)()); |
foo.bar 被 () 包住,查看规范 11.1.6 The Grouping Operator
直接看结果部分:
Return the result of evaluating Expression. This may be of type Reference.
NOTE This algorithm does not apply GetValue to the result of evaluating Expression.
实际上 () 并没有对 MemberExpression 进行计算,所以其实跟示例 1 的结果是一样的。
6.5.3 (foo.bar = foo.bar)()
看示例3,有赋值操作符,查看规范 11.13.1 Simple Assignment ( = ):
计算的第三步:
3.Let rval be GetValue(rref).
因为使用了 GetValue,所以返回的值不是 Reference 类型,
按照之前讲的判断逻辑:
2.3 如果 ref 不是Reference,那么 this 的值为 undefined
this 为 undefined,非严格模式下,this 的值为 undefined 的时候,其值会被隐式转换为全局对象。
6.5.4 (false || foo.bar)()
看示例4,逻辑与算法,查看规范 11.11 Binary Logical Operators:
计算第二步:
2.Let lval be GetValue(lref).
因为使用了 GetValue,所以返回的不是 Reference 类型,this 为 undefined
6.5.5 (foo.bar, foo.bar)()
看示例5,逗号操作符,查看规范11.14 Comma Operator ( , )
计算第二步:
2.Call GetValue(lref).
因为使用了 GetValue,所以返回的不是 Reference 类型,this 为 undefined
6.5.6 揭晓结果
所以最后一个例子的结果是:
1 | var value = 1; |
注意:以上是在非严格模式下的结果,严格模式下因为 this 返回 undefined,所以示例 3 会报错。
补充
最最后,忘记了一个最最普通的情况:
1 | function foo() { |
MemberExpression 是 foo,解析标识符,查看规范 10.3.1 Identifier Resolution,会返回一个 Reference 类型的值:
1 | var fooReference = { |
接下来进行判断:
2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref)
因为 base value 是 EnvironmentRecord,并不是一个 Object 类型,还记得前面讲过的 base value 的取值可能吗? 只可能是 undefined, an Object, a Boolean, a String, a Number, 和 an environment record 中的一种。
IsPropertyReference(ref) 的结果为 false,进入下个判断:
2.2 如果 ref 是 Reference,并且 base value 值是 Environment Record, 那么this的值为 ImplicitThisValue(ref)
base value 正是 Environment Record,所以会调用 ImplicitThisValue(ref)
查看规范 10.2.1.1.6,ImplicitThisValue 方法的介绍:该函数始终返回 undefined。
所以最后 this 的值就是 undefined。
6.6 多说一句
尽管我们可以简单的理解 this 为调用函数的对象,如果是这样的话,如何解释下面这个例子呢?
1 | var value = 1; |
此外,又如何确定调用函数的对象是谁呢?在写文章之初,我就面临着这些问题,最后还是放弃从多个情形下给大家讲解 this 指向的思路,而是追根溯源的从 ECMASciript 规范讲解 this 的指向,尽管从这个角度写起来和读起来都比较吃力,但是一旦多读几遍,明白原理,绝对会给你一个全新的视角看待 this 。而你也就能明白,尽管 foo() 和 (foo.bar = foo.bar)() 最后结果都指向了 undefined,但是两者从规范的角度上却有着本质的区别。
此篇讲解执行上下文的 this,即便不是很理解此篇的内容,依然不影响大家了解执行上下文这个主题下其他的内容。所以,依然可以安心的看下一篇文章。
7.立即执行函数
可能你并没有注意到,我是一个对于专业术语有一点坚持细节人。所有,当我听到流行的但是还存在误解的术语“自执行匿名函数”多次时,我最终决定将我的想法写进这篇文章里。
除了提供关于这种模式事实上是如何工作的一些全面的信息,更进一步的,实际上我建议我们应该知道我们应该叫它什么。而且,如果你想跳过这里,你可以直接跳到立即调用函数表达式进行阅读,但是我建议你读完整篇文章。
它是什么
在 JavaScript 里,每个函数,当被调用时,都会创建一个新的执行上下文。因为在函数里定义的变量和函数是唯一在内部被访问的变量,而不是在外部被访问的变量,当调用函数时,函数提供的上下文提供了一个非常简单的方法创建私有变量。
1 | function makeCounter() { |
在许多情况下,你可能并不需要makeWhatever这样的函数返回多次累加值,并且可以只调用一次得到一个单一的值,在其他一些情况里,你甚至不需要明确的知道返回值。
它的核心
现在,无论你定义一个函数像这样function foo(){}或者var foo = function(){},调用时,你都需要在后面加上一对圆括号,像这样foo()。
1 | //向下面这样定义的函数可以通过在函数名后加一对括号进行调用,像这样`foo()`, |
正如你所看到的,这里捕获了一个错误。当圆括号为了调用函数出现在函数后面时,无论在全局环境或者局部环境里遇到了这样的function关键字,默认的,它会将它当作是一个函数声明,而不是函数表达式,如果你不明确的告诉圆括号它是一个表达式,它会将其当作没有名字的函数声明并且抛出一个错误,因为函数声明需要一个名字。
问题1:这里我么可以思考一个问题,我们是不是也可以像这样直接调用函数 var foo = function(){console.log(1)}(),答案是可以的。
问题2:同样的,我们还可以思考一个问题,像这样的函数声明在后面加上圆括号被直接调用,又会出现什么情况呢?请看下面的解答。
函数,圆括号,错误
有趣的是,如果你为一个函数指定一个名字并在它后面放一对圆括号,同样的也会抛出错误,但这次是因为另外一个原因。当圆括号放在一个函数表达式后面指明了这是一个被调用的函数,而圆括号放在一个声明后面便意味着完全的和前面的函数声明分开了,此时圆括号只是一个简单的代表一个括号(用来控制运算优先的括号)。
1 | //然而函数声明语法上是无效的,它仍然是一个声明,紧跟着的圆括号是无效的,因为圆括号里需要包含表达式 |
立即执行函数表达式(IIFE)
幸运的是,修正语法错误很简单。最流行的也最被接受的方法是将函数声明包裹在圆括号里来告诉语法分析器去表达一个函数表达式,因为在Javascript里,圆括号不能包含声明。因为这点,当圆括号为了包裹函数碰上了 function关键词,它便知道将它作为一个函数表达式去解析而不是函数声明。注意理解这里的圆括号和上面的圆括号遇到函数时的表现是不一样的,也就是说。
- 当圆括号出现在匿名函数的末尾想要调用函数时,它会默认将函数当成是函数声明。
- 当圆括号包裹函数时,它会默认将函数作为表达式去解析,而不是函数声明。
1 | //这两种模式都可以被用来立即调用一个函数表达式,利用函数的执行来创造私有变量 |
关于括号的重要笔记
在一些情况下,当额外的带着歧义的括号围绕在函数表达式周围是没有必要的(因为这时候的括号已经将其作为一个表达式去表达),但当括号用于调用函数表达式时,这仍然是一个好主意。
这样的括号指明函数表达式将会被立即调用,并且变量将会储存函数的结果,而不是函数本身。当这是一个非常长的函数表达式时,这可以节约比人阅读你代码的时间,不用滚到页面底部去看这个函数是否被调用。
作为规则,当你书写清楚明晰的代码时,有必要阻止 JavaScript 抛出错误的,同样也有必要阻止其他开发者对你抛出错误 WTFError!
保存闭包的状态
就像当函数通过他们的名字被调用时,参数会被传递,而当函数表达式被立即调用时,参数也会被传递。一个立即调用的函数表达式可以用来锁定值并且有效的保存此时的状态,因为任何定义在一个函数内的函数都可以使用外面函数传递进来的参数和变量(这种关系被叫做闭包)。
1 | // 它的运行原理可能并不像你想的那样,因为`i`的值从来没有被锁定。 |
记住,在这最后两个例子里,lockedInIndex可以没有任何问题的访问i,但是作为函数的参数使用一个不同的命名标识符可以使概念更加容易的被解释。
立即执行函数一个最显著的优势是就算它没有命名或者说是匿名,函数表达式也可以在没有使用标识符的情况下被立即调用,一个闭包也可以在没有当前变量污染的情况下被使用。
自执行匿名函数(“Self-executing anonymous function”)有什么问题呢?
你看到它已经被提到好几次了,但是它仍然不是那么清楚的被解释,我提议将术语改成**”Immediately-Invoked Function Expression”,或者,IIFE**,如果你喜欢缩写的话。
什么是Immediately-Invoked Function Expression呢?它使一个被立即调用的函数表达式。就像引导你去调用的函数表达式。
我想Javascript社区的成员应该可以在他们的文章里或者陈述里接受术语,Immediately-Invoked Function Expression和 IIFE,因为我感觉这样更容易让这个概念被理解,并且术语”self-executing anonymous function”真的也不够精确。
1 | //下面是个自执行函数,递归的调用自己本身 |
希望上面的例子可以让你更加清楚的知道术语’self-executing’是有一些误导的,因为他并不是执行自己的函数,尽管函数已经被执行。同样的,匿名函数也没用必要特别指出,因为,Immediately Invoked Function Expression,既可以是命名函数也可以匿名函数。
最后:模块模式
当我调用函数表达式时,如果我不至少一次的提醒我自己关于模块模式,我便很可能会忽略它。如果你并不属性 JavaScript 里的模块模式,它和我下面的例子很像,但是返回值用对象代替了函数。
1 | var counter = (function(){ |
模块模式方法不仅相当的厉害而且简单。非常少的代码,你可以有效的利用与方法和属性相关的命名,在一个对象里,组织全部的模块代码即最小化了全局变量的污染也创造了使用变量。
8.instanceof 和 typeof 的实现原理
8.1 typeof 实现原理
typeof 一般被用于判断一个变量的类型,我们可以利用 typeof 来判断number, string, object, boolean, function, undefined, symbol 这七种类型,这种判断能帮助我们搞定一些问题,比如在判断不是 object 类型的数据的时候,typeof能比较清楚的告诉我们具体是哪一类的类型。但是,很遗憾的一点是,typeof 在判断一个 object的数据的时候只能告诉我们这个数据是 object, 而不能细致的具体到是哪一种 object, 比如
1 | let s = new String('abc'); |
要想判断一个数据具体是哪一种 object 的时候,我们需要利用 instanceof 这个操作符来判断,这个我们后面会说到。
来谈谈关于 typeof 的原理吧,我们可以先想一个很有意思的问题,js 在底层是怎么存储数据的类型信息呢?或者说,一个 js 的变量,在它的底层实现中,它的类型信息是怎么实现的呢?
其实,js 在底层存储变量的时候,会在变量的机器码的低位1-3位存储其类型信息👉
- 000:对象
- 010:浮点数
- 100:字符串
- 110:布尔
- 1:整数
but, 对于 undefined 和 null 来说,这两个值的信息存储是有点特殊的。
null:所有机器码均为0
undefined:用 −2^30 整数来表示
所以,typeof 在判断 null 的时候就出现问题了,由于 null 的所有机器码均为0,因此直接被当做了对象来看待。
然而用 instanceof 来判断的话
1 | null instanceof null // TypeError: Right-hand side of 'instanceof' is not an object |
null 直接被判断为不是 object,这也是 JavaScript 的历史遗留bug,可以参考typeof。
因此在用 typeof 来判断变量类型的时候,我们需要注意,最好是用 typeof 来判断基本数据类型(包括symbol),避免对 null 的判断。
还有一个不错的判断类型的方法,就是Object.prototype.toString,我们可以利用这个方法来对一个变量的类型来进行比较准确的判断
1 | Object.prototype.toString.call(1) // "[object Number]" |
8.2 instanceof 操作符的实现原理
之前我们提到了 instanceof 来判断对象的具体类型,其实 instanceof 主要的作用就是判断一个实例是否属于某种类型
1 | let person = function () {} |
当然,instanceof 也可以判断一个实例是否是其父类型或者祖先类型的实例。
1 | let person = function () {} |
这是 instanceof 的用法,但是 instanceof 的原理是什么呢?根据 ECMAScript 语言规范,我梳理了一下大概的思路,然后整理了一段代码如下
1 | function new_instance_of(leftVaule, rightVaule) { |
其实 instanceof 主要的实现原理就是只要右边变量的 prototype 在左边变量的原型链上即可。因此,instanceof 在查找的过程中会遍历左边变量的原型链,直到找到右边变量的 prototype,如果查找失败,则会返回 false,告诉我们左边变量并非是右边变量的实例。
看几个很有趣的例子
1 | function Foo() {} |
要想全部理解 instanceof 的原理,除了我们刚刚提到的实现原理,我们还需要知道 JavaScript 的原型继承原理。
关于原型继承的原理,我简单用一张图来表示
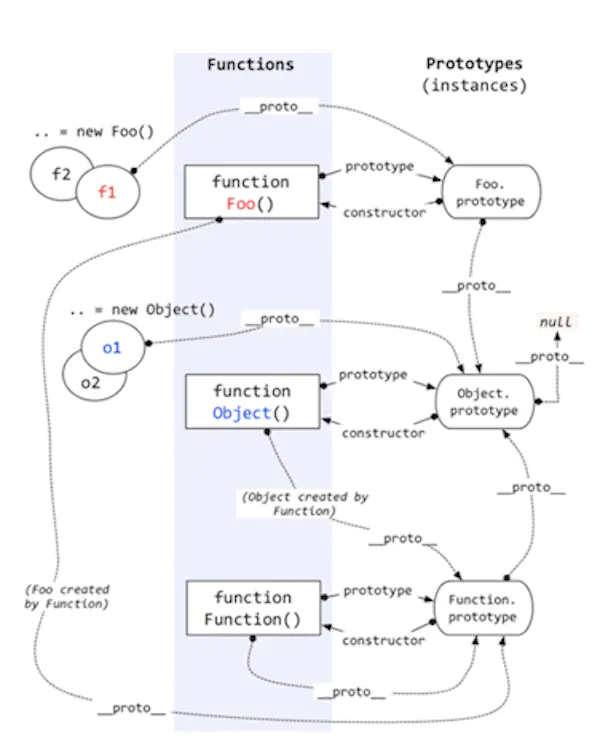
我们知道每个 JavaScript 对象均有一个隐式的 __proto__ 原型属性,而显式的原型属性是 prototype,只有 Object.prototype.__proto__ 属性在未修改的情况下为 null 值。根据图上的原理,我们来梳理上面提到的几个有趣的 instanceof 使用的例子。
Object instanceof Object由图可知,Object 的
prototype属性是Object.prototype, 而由于 Object 本身是一个函数,由 Function 所创建,所以Object.__proto__的值是Function.prototype,而Function.prototype的__proto__属性是Object.prototype,所以我们可以判断出,Object instanceof Object的结果是 true 。用代码简单的表示一下1
2
3
4
5
6
7
8leftValue = Object.__proto__ = Function.prototype;
rightValue = Object.prototype;
// 第一次判断
leftValue != rightValue
leftValue = Function.prototype.__proto__ = Object.prototype
// 第二次判断
leftValue === rightValue
// 返回 trueFunction instanceof Function和Function instanceof Object的运行过程与Object instanceof Object类似,故不再详说。Foo instanceof FooFoo 函数的
prototype属性是Foo.prototype,而 Foo 的__proto__属性是Function.prototype,由图可知,Foo 的原型链上并没有Foo.prototype,因此Foo instanceof Foo也就返回 false 。我们用代码简单的表示一下
1
2
3
4
5
6
7
8
9
10
11
12leftValue = Foo, rightValue = Foo
leftValue = Foo.__proto = Function.prototype
rightValue = Foo.prototype
// 第一次判断
leftValue != rightValue
leftValue = Function.prototype.__proto__ = Object.prototype
// 第二次判断
leftValue != rightValue
leftValue = Object.prototype = null
// 第三次判断
leftValue === null
// 返回 falseFoo instanceof Object1
2
3
4
5
6
7
8
9leftValue = Foo, rightValue = Object
leftValue = Foo.__proto__ = Function.prototype
rightValue = Object.prototype
// 第一次判断
leftValue != rightValue
leftValue = Function.prototype.__proto__ = Object.prototype
// 第二次判断
leftValue === rightValue
// 返回 trueFoo instanceof Function1
2
3
4
5
6leftValue = Foo, rightValue = Function
leftValue = Foo.__proto__ = Function.prototype
rightValue = Function.prototype
// 第一次判断
leftValue === rightValue
// 返回 true
8.3 总结
简单来说,我们使用 typeof 来判断基本数据类型是 ok 的,不过需要注意当用 typeof 来判断 null 类型时的问题,如果想要判断一个对象的具体类型可以考虑用 instanceof,但是 instanceof 也可能判断不准确,比如一个数组,他可以被 instanceof 判断为 Object。所以我们要想比较准确的判断对象实例的类型时,可以采取 Object.prototype.toString.call 方法。
9.bind实现
定义
一句话介绍 bind:
bind() 方法会创建一个新函数。当这个新函数被调用时,bind() 的第一个参数将作为它运行时的 this,之后的一序列参数将会在传递的实参前传入作为它的参数。(来自于 MDN )
由此我们可以首先得出 bind 函数的两个特点:
- 返回一个函数
- 可以传入参数
返回函数的模拟实现
从第一个特点开始,我们举个例子:
1 | var foo = { |
关于指定 this 的指向,我们可以使用 call 或者 apply 实现,来写第一版的代码:
1 | // 第一版 |
此外,之所以 return self.apply(context),是考虑到绑定函数可能是有返回值的,依然是这个例子:
1 | var foo = { |
传参的模拟实现
接下来看第二点,可以传入参数。这个就有点让人费解了,我在 bind 的时候,是否可以传参呢?我在执行 bind 返回的函数的时候,可不可以传参呢?让我们看个例子:
1 | var foo = { |
函数需要传 name 和 age 两个参数,竟然还可以在 bind 的时候,只传一个 name,在执行返回的函数的时候,再传另一个参数 age!
这可咋办?不急,我们用 arguments 进行处理:
1 | // 第二版 |
构造函数效果的模拟实现
完成了这两点,最难的部分到啦!因为 bind 还有一个特点,就是
一个绑定函数也能使用new操作符创建对象:这种行为就像把原函数当成构造器。提供的 this 值被忽略,同时调用时的参数被提供给模拟函数。
也就是说当 bind 返回的函数作为构造函数的时候,bind 时指定的 this 值会失效,但传入的参数依然生效。举个例子:
1 | var value = 2; |
注意:尽管在全局和 foo 中都声明了 value 值,最后依然返回了 undefind,说明绑定的 this 失效了,如果大家了解 new 的模拟实现,就会知道这个时候的 this 已经指向了 obj。
所以我们可以通过修改返回的函数的原型来实现,让我们写一下:
1 | // 第三版 |
构造函数效果的优化实现
但是在这个写法中,我们直接将 fBound.prototype = this.prototype,我们直接修改 fBound.prototype 的时候,也会直接修改绑定函数的 prototype。这个时候,我们可以通过一个空函数来进行中转:
1 | // 第四版 |
到此为止,大的问题都已经解决,给自己一个赞!o( ̄▽ ̄)d
三个小问题
接下来处理些小问题:
1.apply 这段代码跟 MDN 上的稍有不同
在 MDN 中文版讲 bind 的模拟实现时,apply 这里的代码是:
1 | self.apply(this instanceof self ? this : context || this, args.concat(bindArgs)) |
多了一个关于 context 是否存在的判断,然而这个是错误的!
举个例子:
1 | var value = 2; |
以上代码正常情况下会打印 2,如果换成了 context || this,这段代码就会打印 1!
所以这里不应该进行 context 的判断,大家查看 MDN 同样内容的英文版,就不存在这个判断!
2.调用 bind 的不是函数咋办?
不行,我们要报错!
1 | if (typeof this !== "function") { |
3.我要在线上用
那别忘了做个兼容:
1 | Function.prototype.bind = Function.prototype.bind || function () { |
当然最好是用 es5-shim 啦。
最终代码
所以最最后的代码就是:
1 | Function.prototype.bind2 = function (context) { |
面试够用版
1 | Function.prototype.myBind = function (context, ...args) { |
10.call和apply
call 和 apply 的共同点
它们的共同点是,都能够改变函数执行时的上下文,将一个对象的方法交给另一个对象来执行,并且是立即执行的。
为何要改变执行上下文?举一个生活中的小例子:平时没时间做饭的我,周末想给孩子炖个腌笃鲜尝尝。但是没有适合的锅,而我又不想出去买。所以就问邻居借了一个锅来用,这样既达到了目的,又节省了开支,一举两得。
改变执行上下文也是一样的,A 对象有一个方法,而 B 对象因为某种原因,也需要用到同样的方法,那么这时候我们是单独为 B 对象扩展一个方法呢,还是借用一下 A 对象的方法呢?当然是借用 A 对象的啦,既完成了需求,又减少了内存的占用。
另外,它们的写法也很类似,调用 call 和 apply 的对象,必须是一个函数 Function。接下来,就会说到具体的写法,那也是它们区别的主要体现。
call 和 apply 的区别
它们的区别,主要体现在参数的写法上。先来看一下它们各自的具体写法。
call 的写法
1 | Function.call(obj,[param1[,param2[,…[,paramN]]]]) |
需要注意以下几点:
- 调用 call 的对象,必须是个函数 Function。
- call 的第一个参数,是一个对象。 Function 的调用者,将会指向这个对象。如果不传,则默认为全局对象 window。
- 第二个参数开始,可以接收任意个参数。每个参数会映射到相应位置的 Function 的参数上。但是如果将所有的参数作为数组传入,它们会作为一个整体映射到 Function 对应的第一个参数上,之后参数都为空。
1 | function func (a,b,c) {} |
apply 的写法
1 | Function.apply(obj[,argArray]) |
需要注意的是:
- 它的调用者必须是函数 Function,并且只接收两个参数,第一个参数的规则与 call 一致。
- 第二个参数,必须是数组或者类数组,它们会被转换成类数组,传入 Function 中,并且会被映射到 Function 对应的参数上。这也是 call 和 apply 之间,很重要的一个区别。
1 | func.apply(obj, [1,2,3]) |
什么是类数组?
先说数组,这我们都熟悉。它的特征有:可以通过角标调用,如 array[0];具有长度属性length;可以通过 for 循环或forEach方法,进行遍历。
那么,类数组是什么呢?顾名思义,就是具备与数组特征类似的对象。比如,下面的这个对象,就是一个类数组。
1 | let arrayLike = { |
类数组 arrayLike 可以通过角标进行调用,具有length属性,同时也可以通过 for 循环进行遍历。
类数组,还是比较常用的,只是我们平时可能没注意到。比如,我们获取 DOM 节点的方法,返回的就是一个类数组。再比如,在一个方法中使用 arguments 获取到的所有参数,也是一个类数组。
但是需要注意的是:类数组无法使用 forEach、splice、push 等数组原型链上的方法,毕竟它不是真正的数组。
call 和 apply 的用途
下面会分别列举 call 和 apply 的一些使用场景。声明:例子中没有哪个场景是必须用 call 或者必须用 apply 的,只是个人习惯这么用而已。
call 的使用场景
1、对象的继承。如下面这个例子:
1 | function superClass () { |
subClass 通过 call 方法,继承了 superClass 的 print 方法和 a 变量。此外,subClass 还可以扩展自己的其他方法。
2、借用方法。还记得刚才的类数组么?如果它想使用 Array 原型链上的方法,可以这样:
1 | let domNodes = Array.prototype.slice.call(document.getElementsByTagName("*")); |
这样,domNodes 就可以应用 Array 下的所有方法了。
apply 的一些妙用
1、Math.max。用它来获取数组中最大的一项。
1 | let max = Math.max.apply(null, array); |
同理,要获取数组中最小的一项,可以这样:
1 | let min = Math.min.apply(null, array); |
2、实现两个数组合并。在 ES6 的扩展运算符出现之前,我们可以用 Array.prototype.push来实现。
1 | let arr1 = [1, 2, 3]; |
手写apply和bind
call的手写
1 | // call |
apply的手写
1 | // apply |
11.函数柯里化
定义
维基百科中对柯里化 (Currying) 的定义为:
In mathematics and computer science, currying is the technique of translating the evaluation of a function that takes multiple arguments (or a tuple of arguments) into evaluating a sequence of functions, each with a single argument.
翻译成中文:
在数学和计算机科学中,柯里化是一种将使用多个参数的一个函数转换成一系列使用一个参数的函数的技术。
举个例子:
1 | function add(a, b) { |
用途
我们会讲到如何写出这个 curry 函数,并且会将这个 curry 函数写的很强大,但是在编写之前,我们需要知道柯里化到底有什么用?
举个例子:
1 | // 示意而已 |
想想 jQuery 虽然有 $.ajax 这样通用的方法,但是也有 $.get 和 $.post 的语法糖。
curry 的这种用途可以理解为:参数复用。本质上是降低通用性,提高适用性。
可是即便如此,是不是依然感觉没什么用呢?
如果我们仅仅是把参数一个一个传进去,意义可能不大,但是如果我们是把柯里化后的函数传给其他函数比如 map 呢?
举个例子:
比如我们有这样一段数据:
1 | var person = [{name: 'kevin'}, {name: 'daisy'}] |
如果我们要获取所有的 name 值,我们可以这样做:
1 | var name = person.map(function (item) { |
不过如果我们有 curry 函数:
1 | var prop = curry(function (key, obj) { |
我们为了获取 name 属性还要再编写一个 prop 函数,是不是又麻烦了些?
但是要注意,prop 函数编写一次后,以后可以多次使用,实际上代码从原本的三行精简成了一行,而且你看代码是不是更加易懂了?
person.map(prop('name')) 就好像直白的告诉你:person 对象遍历(map)获取(prop) name 属性。
是不是感觉有点意思了呢?
第一版
未来我们会接触到更多有关柯里化的应用,不过那是未来的事情了,现在我们该编写这个 curry 函数了。
一个经常会看到的 curry 函数的实现为:
1 | // 第一版 |
我们可以这样使用:
1 | function add(a, b) { |
已经有柯里化的感觉了,但是还没有达到要求,不过我们可以把这个函数用作辅助函数,帮助我们写真正的 curry 函数。
第二版
1 | // 第二版 |
我们验证下这个函数:
1 | var fn = curry(function(a, b, c) { |
效果已经达到我们的预期,然而这个 curry 函数的实现好难理解呐……
为了让大家更好的理解这个 curry 函数,我给大家写个极简版的代码:
1 | function sub_curry(fn){ |
大家先从理解这个 curry 函数开始。
当执行 fn1() 时,函数返回:
1 | curry(sub_curry(fn0)) |
当执行 fn1()() 时,函数返回:
1 | curry(sub_curry(function(){ |
当执行 fn1()()() 时,函数返回:
1 | // 跟 fn1()() 的分析过程一样 |
当执行 fn1()()()() 时,因为此时 length > 2 为 false,所以执行 fn():
1 | fn() |
再回到真正的 curry 函数,我们以下面的例子为例:
1 | var fn0 = function(a, b, c, d) { |
当执行 fn1(“a”, “b”) 时:
1 | fn1("a", "b") |
当执行 fn1(“a”, “b”)(“c”) 时,函数返回:
1 | curry(sub_curry(function(...){ |
当执行 fn1(“a”, “b”)(“c”)(“d”) 时,此时 arguments.length < length 为 false ,执行 fn(arguments),相当于:
1 | (function(...){ |
函数执行结束。
所以,其实整段代码又很好理解:
sub_curry 的作用就是用函数包裹原函数,然后给原函数传入之前的参数,当执行 fn0(…)(…) 的时候,执行包裹函数,返回原函数,然后再调用 sub_curry 再包裹原函数,然后将新的参数混合旧的参数再传入原函数,直到函数参数的数目达到要求为止。
如果要明白 curry 函数的运行原理,大家还是要动手写一遍,尝试着分析执行步骤。
更易懂的实现
当然了,如果你觉得还是无法理解,你可以选择下面这种实现方式,可以实现同样的效果:
1 | function curry(fn, args) { |
或许大家觉得这种方式更好理解,又能实现一样的效果,为什么不直接就讲这种呢?
因为想给大家介绍各种实现的方法嘛,不能因为难以理解就不给大家介绍呐~
第三版
curry 函数写到这里其实已经很完善了,但是注意这个函数的传参顺序必须是从左到右,根据形参的顺序依次传入,如果我不想根据这个顺序传呢?
我们可以创建一个占位符,比如这样:
1 | var fn = curry(function(a, b, c) { |
我们直接看第三版的代码:
1 | // 第三版 |
面试够用版
就是第二版
1 | // 第一版 |
12.V8引擎的垃圾回收
引言
作为目前最流行的JavaScript引擎,V8引擎从出现的那一刻起便广泛受到人们的关注,我们知道,JavaScript可以高效地运行在浏览器和Nodejs这两大宿主环境中,也是因为背后有强大的V8引擎在为其保驾护航,甚至成就了Chrome在浏览器中的霸主地位。不得不说,V8引擎为了追求极致的性能和更好的用户体验,为我们做了太多太多,从原始的Full-codegen和Crankshaft编译器升级为Ignition解释器和TurboFan编译器的强强组合,到隐藏类,内联缓存和HotSpot热点代码收集等一系列强有力的优化策略,V8引擎正在努力降低整体的内存占用和提升到更高的运行性能。
本篇主要是从V8引擎的垃圾回收机制入手,讲解一下在JavaScript代码执行的整个生命周期中V8引擎是采取怎样的垃圾回收策略来减少内存占比的,当然这部分的知识并不太影响我们写代码的流程,毕竟在一般情况下我们很少会遇到浏览器端出现内存溢出而导致程序崩溃的情况,但是至少我们对这方面有一定的了解之后,能增强我们在写代码过程中对减少内存占用,避免内存泄漏的主观意识,也许能够帮助你写出更加健壮和对V8引擎更加友好的代码。本文也是笔者在查阅资料巩固复习的过程中慢慢总结和整理出来的,若文中有错误的地方,还请指正。
1、为何需要垃圾回收
我们知道,在V8引擎逐行执行JavaScript代码的过程中,当遇到函数的情况时,会为其创建一个函数执行上下文(Context)环境并添加到调用堆栈的栈顶,函数的作用域(handleScope)中包含了该函数中声明的所有变量,当该函数执行完毕后,对应的执行上下文从栈顶弹出,函数的作用域会随之销毁,其包含的所有变量也会统一释放并被自动回收。试想如果在这个作用域被销毁的过程中,其中的变量不被回收,即持久占用内存,那么必然会导致内存暴增,从而引发内存泄漏导致程序的性能直线下降甚至崩溃,因此内存在使用完毕之后理当归还给操作系统以保证内存的重复利用。
这个过程就好比你向亲戚朋友借钱,借得多了却不按时归还,那么你再下次借钱的时候肯定没有那么顺利了,或者说你的亲戚朋友不愿意再借你了,导致你的手头有点儿紧(内存泄漏,性能下降),所以说有借有还,再借不难嘛,毕竟出来混都是要还的。
但是JavaScript作为一门高级编程语言,并不像C语言或C++语言中需要手动地申请分配和释放内存,V8引擎已经帮我们自动进行了内存的分配和管理,好让我们有更多的精力去专注于业务层面的复杂逻辑,这对于我们前端开发人员来说是一项福利,但是随之带来的问题也是显而易见的,那就是由于不用去手动管理内存,导致写代码的过程中不够严谨从而容易引发内存泄漏(毕竟这是别人对你的好,你没有付出过,又怎能体会得到?)。
2、V8引擎的内存限制
虽然V8引擎帮助我们实现了自动的垃圾回收管理,解放了我们勤劳的双手,但V8引擎中的内存使用也并不是无限制的。具体来说,默认情况下,V8引擎在64位系统下最多只能使用约1.4GB的内存,在32位系统下最多只能使用约0.7GB的内存,在这样的限制下,必然会导致在node中无法直接操作大内存对象,比如将一个2GB大小的文件全部读入内存进行字符串分析处理,即使物理内存高达32GB也无法充分利用计算机的内存资源,那么为什么会有这种限制呢?这个要回到V8引擎的设计之初,起初只是作为浏览器端JavaScript的执行环境,在浏览器端我们其实很少会遇到使用大量内存的场景,因此也就没有必要将最大内存设置得过高。但这只是一方面,其实还有另外两个主要的原因:
JS单线程机制:作为浏览器的脚本语言,JS的主要用途是与用户交互以及操作DOM,那么这也决定了其作为单线程的本质,单线程意味着执行的代码必须按顺序执行,在同一时间只能处理一个任务。试想如果JS是多线程的,一个线程在删除DOM元素的同时,另一个线程对该元素进行修改操作,那么必然会导致复杂的同步问题。既然JS是单线程的,那么也就意味着在V8执行垃圾回收时,程序中的其他各种逻辑都要进入暂停等待阶段,直到垃圾回收结束后才会再次重新执行JS逻辑。因此,由于JS的单线程机制,垃圾回收的过程阻碍了主线程逻辑的执行。
虽然JS是单线程的,但是为了能够充分利用操作系统的多核CPU计算能力,在HTML5中引入了新的Web Worker标准,其作用就是为JS创造多线程环境,允许主线程创建Worker线程,将一些任务分配给后者运行。在主线程运行的同时,Worker在后台运行,两者互不干扰。等到Worker线程完成计算任务,再把结果返回给主线程。这样的好处是, 一些计算密集型或高延迟的任务,被Worker线程负担,主线程(通常负责UI交互)就会很流畅,不会被阻塞或者拖慢。Web Worker不是JS的一部分,而是通过JS访问的浏览器特性,其虽然创造了一个多线程的执行环境,但是子线程完全受主线程控制,不能访问浏览器特定的API,例如操作DOM,因此这个新标准并没有改变JS单线程的本质。
垃圾回收机制:垃圾回收本身也是一件非常耗时的操作,假设V8的堆内存为1.5G,那么V8做一次小的垃圾回收需要50ms以上,而做一次非增量式回收甚至需要1s以上,可见其耗时之久,而在这1s的时间内,浏览器一直处于等待的状态,同时会失去对用户的响应,如果有动画正在运行,也会造成动画卡顿掉帧的情况,严重影响应用程序的性能。因此如果内存使用过高,那么必然会导致垃圾回收的过程缓慢,也就会导致主线程的等待时间越长,浏览器也就越长时间得不到响应。
基于以上两点,V8引擎为了减少对应用的性能造成的影响,采用了一种比较粗暴的手段,那就是直接限制堆内存的大小,毕竟在浏览器端一般也不会遇到需要操作几个G内存这样的场景。但是在node端,涉及到的I/O操作可能会比浏览器端更加复杂多样,因此更有可能出现内存溢出的情况。不过也没关系,V8为我们提供了可配置项来让我们手动地调整内存大小,但是需要在node初始化的时候进行配置,我们可以通过如下方式来手动设置。
我们尝试在node命令行中输入以下命令:
笔者本地安装的node版本为
v10.14.2,可通过node -v查看本地node的版本号,不同版本可能会导致下面的命令会有所差异。
1 | // 该命令可以用来查看node中可用的V8引擎的选项及其含义 |
然后我们会在命令行窗口中看到大量关于V8的选项,这里我们暂且只关注图中红色选框中的几个选项:
1 | // 设置新生代内存中单个半空间的内存最小值,单位MB |
通过以上方法便可以手动放宽V8引擎所使用的内存限制,同时node也为我们提供了process.memoryUsage()方法来让我们可以查看当前node进程所占用的实际内存大小。
在上图中,包含的几个字段的含义分别如下所示,单位均为字节:
heapTotal:表示V8当前申请到的堆内存总大小。heapUsed:表示当前内存使用量。external:表示V8内部的C++对象所占用的内存。rss(resident set size):表示驻留集大小,是给这个node进程分配了多少物理内存,这些物理内存中包含堆,栈和代码片段。对象,闭包等存于堆内存,变量存于栈内存,实际的JavaScript源代码存于代码段内存。使用Worker线程时,rss将会是一个对整个进程有效的值,而其他字段则只针对当前线程。
在JS中声明对象时,该对象的内存就分配在堆中,如果当前已申请的堆内存已经不够分配新的对象,则会继续申请堆内存直到堆的大小超过V8的限制为止。
3、V8的垃圾回收策略
V8的垃圾回收策略主要是基于分代式垃圾回收机制,其根据对象的存活时间将内存的垃圾回收进行不同的分代,然后对不同的分代采用不同的垃圾回收算法。
3.1 V8的内存结构
在V8引擎的堆结构组成中,其实除了新生代和老生代外,还包含其他几个部分,但是垃圾回收的过程主要出现在新生代和老生代,所以对于其他的部分我们没必要做太多的深入,有兴趣的小伙伴儿可以查阅下相关资料,V8的内存结构主要由以下几个部分组成:
新生代(new_space):大多数的对象开始都会被分配在这里,这个区域相对较小但是垃圾回收特别频繁,该区域被分为两半,一半用来分配内存,另一半用于在垃圾回收时将需要保留的对象复制过来。老生代(old_space):新生代中的对象在存活一段时间后就会被转移到老生代内存区,相对于新生代该内存区域的垃圾回收频率较低。老生代又分为老生代指针区和老生代数据区,前者包含大多数可能存在指向其他对象的指针的对象,后者只保存原始数据对象,这些对象没有指向其他对象的指针。大对象区(large_object_space):存放体积超越其他区域大小的对象,每个对象都会有自己的内存,垃圾回收不会移动大对象区。代码区(code_space):代码对象,会被分配在这里,唯一拥有执行权限的内存区域。map区(map_space):存放Cell和Map,每个区域都是存放相同大小的元素,结构简单(这里没有做具体深入的了解,有清楚的小伙伴儿还麻烦解释下)。
内存结构图如下所示:
上图中的带斜纹的区域代表暂未使用的内存,新生代(new_space)被划分为了两个部分,其中一部分叫做inactive new space,表示暂未激活的内存区域,另一部分为激活状态,为什么会划分为两个部分呢,在下一小节我们会讲到。
3.2 新生代
在V8引擎的内存结构中,新生代主要用于存放存活时间较短的对象。新生代内存是由两个semispace(半空间)构成的,内存最大值在64位系统和32位系统上分别为32MB和16MB,在新生代的垃圾回收过程中主要采用了Scavenge算法。
Scavenge算法是一种典型的牺牲空间换取时间的算法,对于老生代内存来说,可能会存储大量对象,如果在老生代中使用这种算法,势必会造成内存资源的浪费,但是在新生代内存中,大部分对象的生命周期较短,在时间效率上表现可观,所以还是比较适合这种算法。
在
Scavenge算法的具体实现中,主要采用了Cheney算法,它将新生代内存一分为二,每一个部分的空间称为semispace,也就是我们在上图中看见的new_space中划分的两个区域,其中处于激活状态的区域我们称为From空间,未激活(inactive new space)的区域我们称为To空间。这两个空间中,始终只有一个处于使用状态,另一个处于闲置状态。我们的程序中声明的对象首先会被分配到From空间,当进行垃圾回收时,如果From空间中尚有存活对象,则会被复制到To空间进行保存,非存活的对象会被自动回收。当复制完成后,From空间和To空间完成一次角色互换,To空间会变为新的From空间,原来的From空间则变为To空间。
基于以上算法,我们可以画出如下的流程图:
- 假设我们在
From空间中分配了三个对象A、B、C
- 当程序主线程任务第一次执行完毕后进入垃圾回收时,发现对象A已经没有其他引用,则表示可以对其进行回收
- 对象B和对象C此时依旧处于活跃状态,因此会被复制到
To空间中进行保存
- 接下来将
From空间中的所有非存活对象全部清除
- 此时
From空间中的内存已经清空,开始和To空间完成一次角色互换
- 当程序主线程在执行第二个任务时,在
From空间中分配了一个新对象D
- 任务执行完毕后再次进入垃圾回收,发现对象D已经没有其他引用,表示可以对其进行回收
- 对象B和对象C此时依旧处于活跃状态,再次被复制到
To空间中进行保存
- 再次将
From空间中的所有非存活对象全部清除
From空间和To空间继续完成一次角色互换
通过以上的流程图,我们可以很清楚地看到,Scavenge算法的垃圾回收过程主要就是将存活对象在From空间和To空间之间进行复制,同时完成两个空间之间的角色互换,因此该算法的缺点也比较明显,浪费了一半的内存用于复制。
3.3 对象晋升
当一个对象在经过多次复制之后依旧存活,那么它会被认为是一个生命周期较长的对象,在下一次进行垃圾回收时,该对象会被直接转移到老生代中,这种对象从新生代转移到老生代的过程我们称之为晋升。
对象晋升的条件主要有以下两个:
- 对象是否经历过一次
Scavenge算法 To空间的内存占比是否已经超过25%
默认情况下,我们创建的对象都会分配在From空间中,当进行垃圾回收时,在将对象从From空间复制到To空间之前,会先检查该对象的内存地址来判断是否已经经历过一次Scavenge算法,如果地址已经发生变动则会将该对象转移到老生代中,不会再被复制到To空间,可以用以下的流程图来表示:
如果对象没有经历过Scavenge算法,会被复制到To空间,但是如果此时To空间的内存占比已经超过25%,则该对象依旧会被转移到老生代,如下图所示:
之所以有25%的内存限制是因为To空间在经历过一次Scavenge算法后会和From空间完成角色互换,会变为From空间,后续的内存分配都是在From空间中进行的,如果内存使用过高甚至溢出,则会影响后续对象的分配,因此超过这个限制之后对象会被直接转移到老生代来进行管理。
3.4 老生代
在老生代中,因为管理着大量的存活对象,如果依旧使用Scavenge算法的话,很明显会浪费一半的内存,因此已经不再使用Scavenge算法,而是采用新的算法Mark-Sweep(标记清除)和Mark-Compact(标记整理)来进行管理。
在早前我们可能听说过一种算法叫做引用计数,该算法的原理比较简单,就是看对象是否还有其他引用指向它,如果没有指向该对象的引用,则该对象会被视为垃圾并被垃圾回收器回收,示例如下:
1 | // 创建了两个对象obj1和obj2,其中obj2作为obj1的属性被obj1引用,因此不会被垃圾回收 |
上述例子在经过一系列操作后最终对象会被垃圾回收,但是一旦我们碰到循环引用的场景,就会出现问题,我们看下面的例子:
1 | function foo() { |
这个例子中我们将对象a的a1属性指向对象b,将对象b的b1属性指向对象a,形成两个对象相互引用,在foo函数执行完毕后,函数的作用域已经被销毁,作用域中包含的变量a和b本应该可以被回收,但是因为采用了引用计数的算法,两个变量均存在指向自身的引用,因此依旧无法被回收,导致内存泄漏。
因此为了避免循环引用导致的内存泄漏问题,截至2012年所有的现代浏览器均放弃了这种算法,转而采用新的Mark-Sweep(标记清除)和Mark-Compact(标记整理)算法。在上面循环引用的例子中,因为变量a和变量b无法从window全局对象访问到,因此无法对其进行标记,所以最终会被回收。
Mark-Sweep(标记清除)分为标记和清除两个阶段,在标记阶段会遍历堆中的所有对象,然后标记活着的对象,在清除阶段中,会将死亡的对象进行清除。Mark-Sweep算法主要是通过判断某个对象是否可以被访问到,从而知道该对象是否应该被回收,具体步骤如下:
- 垃圾回收器会在内部构建一个
根列表,用于从根节点出发去寻找那些可以被访问到的变量。比如在JavaScript中,window全局对象可以看成一个根节点。 - 然后,垃圾回收器从所有根节点出发,遍历其可以访问到的子节点,并将其标记为活动的,根节点不能到达的地方即为非活动的,将会被视为垃圾。
- 最后,垃圾回收器将会释放所有非活动的内存块,并将其归还给操作系统。
以下几种情况都可以作为根节点:
- 全局对象
- 本地函数的局部变量和参数
- 当前嵌套调用链上的其他函数的变量和参数
但是Mark-Sweep算法存在一个问题,就是在经历过一次标记清除后,内存空间可能会出现不连续的状态,因为我们所清理的对象的内存地址可能不是连续的,所以就会出现内存碎片的问题,导致后面如果需要分配一个大对象而空闲内存不足以分配,就会提前触发垃圾回收,而这次垃圾回收其实是没必要的,因为我们确实有很多空闲内存,只不过是不连续的。
为了解决这种内存碎片的问题,Mark-Compact(标记整理)算法被提了出来,该算法主要就是用来解决内存的碎片化问题的,回收过程中将死亡对象清除后,在整理的过程中,会将活动的对象往堆内存的一端进行移动,移动完成后再清理掉边界外的全部内存,我们可以用如下流程图来表示:
- 假设在老生代中有A、B、C、D四个对象
- 在垃圾回收的
标记阶段,将对象A和对象C标记为活动的
- 在垃圾回收的
整理阶段,将活动的对象往堆内存的一端移动
- 在垃圾回收的
清除阶段,将活动对象左侧的内存全部回收
至此就完成了一次老生代垃圾回收的全部过程,我们在前文中说过,由于JS的单线程机制,垃圾回收的过程会阻碍主线程同步任务的执行,待执行完垃圾回收后才会再次恢复执行主任务的逻辑,这种行为被称为全停顿(stop-the-world)。在标记阶段同样会阻碍主线程的执行,一般来说,老生代会保存大量存活的对象,如果在标记阶段将整个堆内存遍历一遍,那么势必会造成严重的卡顿。
因此,为了减少垃圾回收带来的停顿时间,V8引擎又引入了Incremental Marking(增量标记)的概念,即将原本需要一次性遍历堆内存的操作改为增量标记的方式,先标记堆内存中的一部分对象,然后暂停,将执行权重新交给JS主线程,待主线程任务执行完毕后再从原来暂停标记的地方继续标记,直到标记完整个堆内存。这个理念其实有点像React框架中的Fiber架构,只有在浏览器的空闲时间才会去遍历Fiber Tree执行对应的任务,否则延迟执行,尽可能少地影响主线程的任务,避免应用卡顿,提升应用性能。
得益于增量标记的好处,V8引擎后续继续引入了延迟清理(lazy sweeping)和增量式整理(incremental compaction),让清理和整理的过程也变成增量式的。同时为了充分利用多核CPU的性能,也将引入并行标记和并行清理,进一步地减少垃圾回收对主线程的影响,为应用提升更多的性能。
4、如何避免内存泄漏
在我们写代码的过程中,基本上都不太会关注写出怎样的代码才能有效地避免内存泄漏,或者说浏览器和大部分的前端框架在底层已经帮助我们处理了常见的内存泄漏问题,但是我们还是有必要了解一下常见的几种避免内存泄漏的方式,毕竟在面试过程中也是经常考察的要点。
4.1 尽可能少地创建全局变量
在ES5中以var声明的方式在全局作用域中创建一个变量时,或者在函数作用域中不以任何声明的方式创建一个变量时,都会无形地挂载到window全局对象上,如下所示:
1 | var a = 1; // 等价于 window.a = 1; |
等价于
1 | function foo() { |
我们在foo函数中创建了一个变量a但是忘记使用var来声明,此时会意想不到地创建一个全局变量并挂载到window对象上,另外还有一种比较隐蔽的方式来创建全局变量:
1 | function foo() { |
当foo函数在调用时,它所指向的运行上下文环境为window全局对象,因此函数中的this指向的其实是window,也就无意创建了一个全局变量。当进行垃圾回收时,在标记阶段因为window对象可以作为根节点,在window上挂载的属性均可以被访问到,并将其标记为活动的从而常驻内存,因此也就不会被垃圾回收,只有在整个进程退出时全局作用域才会被销毁。如果你遇到需要必须使用全局变量的场景,那么请保证一定要在全局变量使用完毕后将其设置为null从而触发回收机制。
4.2 手动清除定时器
在我们的应用中经常会有使用setTimeout或者setInterval等定时器的场景,定时器本身是一个非常有用的功能,但是如果我们稍不注意,忘记在适当的时间手动清除定时器,那么很有可能就会导致内存泄漏,示例如下:
1 | const numbers = []; |
在这个示例中,由于我们没有手动清除定时器,导致回调任务会不断地执行下去,回调中所引用的numbers变量也不会被垃圾回收,最终导致numbers数组长度无限递增,从而引发内存泄漏。
4.3 少用闭包
闭包是JS中的一个高级特性,巧妙地利用闭包可以帮助我们实现很多高级功能。一般来说,我们在查找变量时,在本地作用域中查找不到就会沿着作用域链从内向外单向查找,但是闭包的特性可以让我们在外部作用域访问内部作用域中的变量,示例如下:
1 | function foo() { |
在这个示例中,foo函数执行完毕后会返回一个匿名函数,该函数内部引用了foo函数中的局部变量local,并且通过变量bar来引用这个匿名的函数定义,通过这种闭包的方式我们就可以在foo函数的外部作用域中访问到它的局部变量local。一般情况下,当foo函数执行完毕后,它的作用域会被销毁,但是由于存在变量引用其返回的匿名函数,导致作用域无法得到释放,也就导致local变量无法回收,只有当我们取消掉对匿名函数的引用才会进入垃圾回收阶段。
4.4 清除DOM引用
以往我们在操作DOM元素时,为了避免多次获取DOM元素,我们会将DOM元素存储在一个数据字典中,示例如下:
1 | const elements = { |
在这个示例中,我们想调用removeButton方法来清除button元素,但是由于在elements字典中存在对button元素的引用,所以即使我们通过removeChild方法移除了button元素,它其实还是依旧存储在内存中无法得到释放,只有我们手动清除对button元素的引用才会被垃圾回收。
4.5 弱引用
通过前几个示例我们会发现如果我们一旦疏忽,就会容易地引发内存泄漏的问题,为此,在ES6中为我们新增了两个有效的数据结构WeakMap和WeakSet,就是为了解决内存泄漏的问题而诞生的。其表示弱引用,它的键名所引用的对象均是弱引用,弱引用是指垃圾回收的过程中不会将键名对该对象的引用考虑进去,只要所引用的对象没有其他的引用了,垃圾回收机制就会释放该对象所占用的内存。这也就意味着我们不需要关心WeakMap中键名对其他对象的引用,也不需要手动地进行引用清除,我们尝试在node中演示一下过程(参考阮一峰ES6标准入门中的示例,自己手动实现了一遍)。
首先打开node命令行,输入以下命令:
1 | node --expose-gc // --expose-gc 表示允许手动执行垃圾回收机制 |
然后我们执行下面的代码。
1 | // 手动执行一次垃圾回收保证内存数据准确 |
在上述示例中,我们发现虽然我们没有手动清除WeakMap中的键名对数组的引用,但是内存依旧已经回到原始的大小,说明该数组已经被回收,那么这个也就是弱引用的具体含义了。
5、总结
本文中主要讲解了一下V8引擎的垃圾回收机制,并分别从新生代和老生代讲述了不同分代中的垃圾回收策略以及对应的回收算法,之后列出了几种常见的避免内存泄漏的方式来帮助我们写出更加优雅的代码。如果你已经了解过垃圾回收相关的内容,那么这篇文章可以帮助你简单复习加深印象,如果没有了解过,那么笔者也希望这篇文章能够帮助到你了解一些代码层面之外的底层知识点,由于V8引擎的源码是用C++实现的,所以笔者也就没有做这方面的深入了,有兴趣的小伙伴儿可以自行探究,文中有错误的地方,还希望能够在评论区指正。
13.浮点数精度
前言
0.1 + 0.2 是否等于 0.3 作为一道经典的面试题,已经广外熟知,说起原因,大家能回答出这是浮点数精度问题导致,也能辩证的看待这并非是 ECMAScript 这门语言的问题,今天就是具体看一下背后的原因。
数字类型
ECMAScript 中的 Number 类型使用 IEEE754 标准来表示整数和浮点数值。所谓 IEEE754 标准,全称 IEEE 二进制浮点数算术标准,这个标准定义了表示浮点数的格式等内容。
在 IEEE754 中,规定了四种表示浮点数值的方式:单精确度(32位)、双精确度(64位)、延伸单精确度、与延伸双精确度。像 ECMAScript 采用的就是双精确度,也就是说,会用 64 位字节来储存一个浮点数。
浮点数转二进制
我们来看下 1020 用十进制的表示:
1020 = 1 * 10^3 + 0 * 10^2 + 2 * 10^1 + 0 * 10^0
所以 1020 用十进制表示就是 1020……(哈哈)
如果 1020 用二进制来表示呢?
1020 = 1 * 2^9 + 1 * 2^8 + 1 * 2^7 + 1 * 2^6 + 1 * 2^5 + 1 * 2^4 + 1 * 2^3 + 1 * 2^2 + 0 * 2^1 + 0 * 2^0
所以 1020 的二进制为 1111111100
那如果是 0.75 用二进制表示呢?同理应该是:
0.75 = a * 2^-1 + b * 2^-2 + c * 2^-3 + d * 2^-4 + …
因为使用的是二进制,这里的 abcd……的值的要么是 0 要么是 1。
那怎么算出 abcd…… 的值呢,我们可以两边不停的乘以 2 算出来,解法如下:
0.75 = a * 2^-1 + b * 2^-2 + c * 2^-3 + d * 2^-4…
两边同时乘以 2
1 + 0.5 = a * 2^0 + b * 2^-1 + c * 2^-2 + d * 2^-3… (所以 a = 1)
剩下的:
0.5 = b * 2^-1 + c * 2^-2 + d * 2^-3…
再同时乘以 2
1 + 0 = b * 2^0 + c * 2^-2 + d * 2^-3… (所以 b = 1)
所以 0.75 用二进制表示就是 0.ab,也就是 0.11
然而不是所有的数都像 0.75 这么好算,我们来算下 0.1:
1 | 0.1 = a * 2^-1 + b * 2^-2 + c * 2^-3 + d * 2^-4 + ... |
然后你就会发现,这个计算在不停的循环,所以 0.1 用二进制表示就是 0.00011001100110011……
浮点数的存储
虽然 0.1 转成二进制时是一个无限循环的数,但计算机总要储存吧,我们知道 ECMAScript 使用 64 位字节来储存一个浮点数,那具体是怎么储存的呢?这就要说回 IEEE754 这个标准了,毕竟是这个标准规定了存储的方式。
这个标准认为,一个浮点数 (Value) 可以这样表示:
Value = sign * exponent * fraction
看起来很抽象的样子,简单理解就是科学计数法……
比如 -1020,用科学计数法表示就是:
-1 * 10^3 * 1.02
sign 就是 -1,exponent 就是 10^3,fraction 就是 1.02
对于二进制也是一样,以 0.1 的二进制 0.00011001100110011…… 这个数来说:
可以表示为:
1 * 2^-4 * 1.1001100110011……
其中 sign 就是 1,exponent 就是 2^-4,fraction 就是 1.1001100110011……
而当只做二进制科学计数法的表示时,这个 Value 的表示可以再具体一点变成:
V = (-1)^S * (1 + Fraction) * 2^E
(如果所有的浮点数都可以这样表示,那么我们存储的时候就把这其中会变化的一些值存储起来就好了)
我们来一点点看:
(-1)^S 表示符号位,当 S = 0,V 为正数;当 S = 1,V 为负数。
再看 (1 + Fraction),这是因为所有的浮点数都可以表示为 1.xxxx * 2^xxx 的形式,前面的一定是 1.xxx,那干脆我们就不存储这个 1 了,直接存后面的 xxxxx 好了,这也就是 Fraction 的部分。
最后再看 2^E
如果是 1020.75,对应二进制数就是 1111111100.11,对应二进制科学计数法就是 1 * 1.11111110011 * 2^9,E 的值就是 9,而如果是 0.1 ,对应二进制是 1 * 1.1001100110011…… * 2^-4, E 的值就是 -4,也就是说,E 既可能是负数,又可能是正数,那问题就来了,那我们该怎么储存这个 E 呢?
我们这样解决,假如我们用 8 位字节来存储 E 这个数,如果只有正数的话,储存的值的范围是 0 ~ 254,而如果要储存正负数的话,值的范围就是 -127~127,我们在存储的时候,把要存储的数字加上 127,这样当我们存 -127 的时候,我们存 0,当存 127 的时候,存 254,这样就解决了存负数的问题。对应的,当取值的时候,我们再减去 127。
所以呢,真到实际存储的时候,我们并不会直接存储 E,而是会存储 E + bias,当用 8 个字节的时候,这个 bias 就是 127。
所以,如果要存储一个浮点数,我们存 S 和 Fraction 和 E + bias 这三个值就好了,那具体要分配多少个字节位来存储这些数呢?IEEE754 给出了标准:
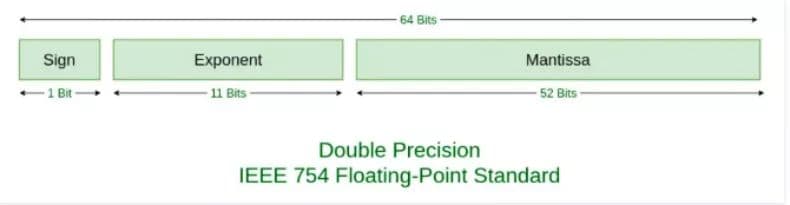
在这个标准下:
我们会用 1 位存储 S,0 表示正数,1 表示负数。
用 11 位存储 E + bias,对于 11 位来说,bias 的值是 2^(11-1) - 1,也就是 1023。
用 52 位存储 Fraction。
举个例子,就拿 0.1 来看,对应二进制是 1 * 1.1001100110011…… * 2^-4, Sign 是 0,E + bias 是 -4 + 1023 = 1019,1019 用二进制表示是 1111111011,Fraction 是 1001100110011……
对应 64 个字节位的完整表示就是:
0 01111111011 1001100110011001100110011001100110011001100110011010
同理, 0.2 表示的完整表示是:
0 01111111100 1001100110011001100110011001100110011001100110011010
所以当 0.1 存下来的时候,就已经发生了精度丢失,当我们用浮点数进行运算的时候,使用的其实是精度丢失后的数。
浮点数的运算
关于浮点数的运算,一般由以下五个步骤完成:对阶、尾数运算、规格化、舍入处理、溢出判断。我们来简单看一下 0.1 和 0.2 的计算。
首先是对阶,所谓对阶,就是把阶码调整为相同,比如 0.1 是 1.1001100110011…… * 2^-4,阶码是 -4,而 0.2 就是 1.10011001100110...* 2^-3,阶码是 -3,两个阶码不同,所以先调整为相同的阶码再进行计算,调整原则是小阶对大阶,也就是 0.1 的 -4 调整为 -3,对应变成 0.11001100110011…… * 2^-3
接下来是尾数计算:
1 | 0.1100110011001100110011001100110011001100110011001101 |
我们得到结果为 10.0110011001100110011001100110011001100110011001100111 * 2^-3
将这个结果处理一下,即结果规格化,变成 1.0011001100110011001100110011001100110011001100110011(1) * 2^-2
括号里的 1 意思是说计算后这个 1 超出了范围,所以要被舍弃了。
再然后是舍入,四舍五入对应到二进制中,就是 0 舍 1 入,因为我们要把括号里的 1 丢了,所以这里会进一,结果变成
1 | 1.0011001100110011001100110011001100110011001100110100 * 2^-2 |
本来还有一个溢出判断,因为这里不涉及,就不讲了。
所以最终的结果存成 64 位就是
0 01111111101 0011001100110011001100110011001100110011001100110100
将它转换为10进制数就得到 0.30000000000000004440892098500626
因为两次存储时的精度丢失加上一次运算时的精度丢失,最终导致了 0.1 + 0.2 !== 0.3
其他
1 | // 十进制转二进制 |
14.new
定义
一句话介绍 new:
new 运算符创建一个用户定义的对象类型的实例或具有构造函数的内置对象类型之一
也许有点难懂,我们在模拟 new 之前,先看看 new 实现了哪些功能。
举个例子:
1 | // Otaku 御宅族,简称宅 |
从这个例子中,我们可以看到,实例 person 可以:
- 访问到 Otaku 构造函数里的属性
- 访问到 Otaku.prototype 中的属性
接下来,我们可以尝试着模拟一下了。
因为 new 是关键字,所以无法像 bind 函数一样直接覆盖,所以我们写一个函数,命名为 objectFactory,来模拟 new 的效果。用的时候是这样的:
1 | function Otaku () { |
初步实现
分析:
因为 new 的结果是一个新对象,所以在模拟实现的时候,我们也要建立一个新对象,假设这个对象叫 obj,因为 obj 会具有 Otaku 构造函数里的属性,想想经典继承的例子,我们可以使用 Otaku.apply(obj, arguments)来给 obj 添加新的属性。
在 JavaScript 深入系列第一篇中,我们便讲了原型与原型链,我们知道实例的 proto 属性会指向构造函数的 prototype,也正是因为建立起这样的关系,实例可以访问原型上的属性。
现在,我们可以尝试着写第一版了:
1 | // 第一版代码 |
在这一版中,我们:
- 用new Object() 的方式新建了一个对象 obj
- 取出第一个参数,就是我们要传入的构造函数。此外因为 shift 会修改原数组,所以 arguments 会被去除第一个参数
- 将 obj 的原型指向构造函数,这样 obj 就可以访问到构造函数原型中的属性
- 使用 apply,改变构造函数 this 的指向到新建的对象,这样 obj 就可以访问到构造函数中的属性
- 返回 obj
https://github.com/mqyqingfeng/Blog/issues/16)
复制以下的代码,到浏览器中,我们可以做一下测试:
1 | function Otaku (name, age) { |
返回值效果实现
接下来我们再来看一种情况,假如构造函数有返回值,举个例子:
1 | function Otaku (name, age) { |
在这个例子中,构造函数返回了一个对象,在实例 person 中只能访问返回的对象中的属性。
而且还要注意一点,在这里我们是返回了一个对象,假如我们只是返回一个基本类型的值呢?
再举个例子:
1 | function Otaku (name, age) { |
结果完全颠倒过来,这次尽管有返回值,但是相当于没有返回值进行处理。
所以我们还需要判断返回的值是不是一个对象,如果是一个对象,我们就返回这个对象,如果没有,我们该返回什么就返回什么。
再来看第二版的代码,也是最后一版的代码:
1 | // 第二版的代码 |
15.Event Loop(事件循环)机制
前言
我们都知道,javascript从诞生之日起就是一门单线程的非阻塞的脚本语言。这是由其最初的用途来决定的:与浏览器交互。
单线程意味着,javascript代码在执行的任何时候,都只有一个主线程来处理所有的任务。
而非阻塞则是当代码需要进行一项异步任务(无法立刻返回结果,需要花一定时间才能返回的任务,如I/O事件)的时候,主线程会挂起(pending)这个任务,然后在异步任务返回结果的时候再根据一定规则去执行相应的回调。
单线程是必要的,也是javascript这门语言的基石,原因之一在其最初也是最主要的执行环境——浏览器中,我们需要进行各种各样的dom操作。试想一下 如果javascript是多线程的,那么当两个线程同时对dom进行一项操作,例如一个向其添加事件,而另一个删除了这个dom,此时该如何处理呢?因此,为了保证不会 发生类似于这个例子中的情景,javascript选择只用一个主线程来执行代码,这样就保证了程序执行的一致性。
当然,现如今人们也意识到,单线程在保证了执行顺序的同时也限制了javascript的效率,因此开发出了web worker技术。这项技术号称让javascript成为一门多线程语言。
然而,使用web worker技术开的多线程有着诸多限制,例如:所有新线程都受主线程的完全控制,不能独立执行。这意味着这些“线程” 实际上应属于主线程的子线程。另外,这些子线程并没有执行I/O操作的权限,只能为主线程分担一些诸如计算等任务。所以严格来讲这些线程并没有完整的功能,也因此这项技术并非改变了javascript语言的单线程本质。
可以预见,未来的javascript也会一直是一门单线程的语言。
话说回来,前面提到javascript的另一个特点是“非阻塞”,那么javascript引擎到底是如何实现的这一点呢?答案就是今天这篇文章的主角——event loop(事件循环)。
注:虽然nodejs中的也存在与传统浏览器环境下的相似的事件循环。然而两者间却有着诸多不同,故把两者分开,单独解释。
正文
浏览器环境下js引擎的事件循环机制
1.执行栈与事件队列
当javascript代码执行的时候会将不同的变量存于内存中的不同位置:堆(heap)和栈(stack)中来加以区分。其中,堆里存放着一些对象。而栈中则存放着一些基础类型变量以及对象的指针。 但是我们这里说的执行栈和上面这个栈的意义却有些不同。
我们知道,当我们调用一个方法的时候,js会生成一个与这个方法对应的执行环境(context),又叫执行上下文。这个执行环境中存在着这个方法的私有作用域,上层作用域的指向,方法的参数,这个作用域中定义的变量以及这个作用域的this对象。 而当一系列方法被依次调用的时候,因为js是单线程的,同一时间只能执行一个方法,于是这些方法被排队在一个单独的地方。这个地方被称为执行栈。
当一个脚本第一次执行的时候,js引擎会解析这段代码,并将其中的同步代码按照执行顺序加入执行栈中,然后从头开始执行。如果当前执行的是一个方法,那么js会向执行栈中添加这个方法的执行环境,然后进入这个执行环境继续执行其中的代码。当这个执行环境中的代码 执行完毕并返回结果后,js会退出这个执行环境并把这个执行环境销毁,回到上一个方法的执行环境。。这个过程反复进行,直到执行栈中的代码全部执行完毕。
下面这个图片非常直观的展示了这个过程,其中的global就是初次运行脚本时向执行栈中加入的代码:
从图片可知,一个方法执行会向执行栈中加入这个方法的执行环境,在这个执行环境中还可以调用其他方法,甚至是自己,其结果不过是在执行栈中再添加一个执行环境。这个过程可以是无限进行下去的,除非发生了栈溢出,即超过了所能使用内存的最大值。
以上的过程说的都是同步代码的执行。那么当一个异步代码(如发送ajax请求数据)执行后会如何呢?前文提过,js的另一大特点是非阻塞,实现这一点的关键在于下面要说的这项机制——事件队列(Task Queue)。
js引擎遇到一个异步事件后并不会一直等待其返回结果,而是会将这个事件挂起,继续执行执行栈中的其他任务。当一个异步事件返回结果后,js会将这个事件加入与当前执行栈不同的另一个队列,我们称之为事件队列。被放入事件队列不会立刻执行其回调,而是等待当前执行栈中的所有任务都执行完毕, 主线程处于闲置状态时,主线程会去查找事件队列是否有任务。如果有,那么主线程会从中取出排在第一位的事件,并把这个事件对应的回调放入执行栈中,然后执行其中的同步代码…,如此反复,这样就形成了一个无限的循环。这就是这个过程被称为“事件循环(Event Loop)”的原因。
这里还有一张图来展示这个过程:
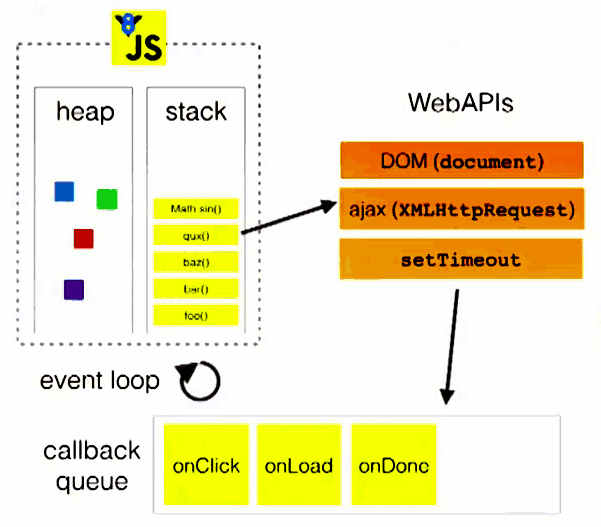
图中的stack表示我们所说的执行栈,web apis则是代表一些异步事件,而callback queue即事件队列。
2.macro task与micro task
以上的事件循环过程是一个宏观的表述,实际上因为异步任务之间并不相同,因此他们的执行优先级也有区别。不同的异步任务被分为两类:微任务(micro task)和宏任务(macro task)。
以下事件属于宏任务:
setInterval()setTimeout()
以下事件属于微任务
new Promise()new MutaionObserver()
前面我们介绍过,在一个事件循环中,异步事件返回结果后会被放到一个任务队列中。然而,根据这个异步事件的类型,这个事件实际上会被对应的宏任务队列或者微任务队列中去。并且在当前执行栈为空的时候,主线程会 查看微任务队列是否有事件存在。如果不存在,那么再去宏任务队列中取出一个事件并把对应的回到加入当前执行栈;如果存在,则会依次执行队列中事件对应的回调,直到微任务队列为空,然后去宏任务队列中取出最前面的一个事件,把对应的回调加入当前执行栈…如此反复,进入循环。
我们只需记住当当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件,然后再去宏任务队列中取出一个事件。同一次事件循环中,微任务永远在宏任务之前执行。
这样就能解释下面这段代码的结果:
1 | setTimeout(function () { |
结果为:
1 | 2 |
node环境下的事件循环机制
1.与浏览器环境有何不同?
在node中,事件循环表现出的状态与浏览器中大致相同。不同的是node中有一套自己的模型。node中事件循环的实现是依靠的libuv引擎。我们知道node选择chrome v8引擎作为js解释器,v8引擎将js代码分析后去调用对应的node api,而这些api最后则由libuv引擎驱动,执行对应的任务,并把不同的事件放在不同的队列中等待主线程执行。 因此实际上node中的事件循环存在于libuv引擎中。
2.事件循环模型
下面是一个libuv引擎中的事件循环的模型:
1 | ┌───────────────────────┐ |
注:模型中的每一个方块代表事件循环的一个阶段
这个模型是node官网上的一篇文章中给出的,我下面的解释也都来源于这篇文章。我会在文末把文章地址贴出来,有兴趣的朋友可以亲自与看看原文。
3.事件循环各阶段详解
从上面这个模型中,我们可以大致分析出node中的事件循环的顺序:
外部输入数据–>轮询阶段(poll)–>检查阶段(check)–>关闭事件回调阶段(close callback)–>定时器检测阶段(timer)–>I/O事件回调阶段(I/O callbacks)–>闲置阶段(idle, prepare)–>轮询阶段…
以上各阶段的名称是根据我个人理解的翻译,为了避免错误和歧义,下面解释的时候会用英文来表示这些阶段。
这些阶段大致的功能如下:
- timers: 这个阶段执行定时器队列中的回调如
setTimeout()和setInterval()。 - I/O callbacks: 这个阶段执行几乎所有的回调。但是不包括close事件,定时器和
setImmediate()的回调。 - idle, prepare: 这个阶段仅在内部使用,可以不必理会。
- poll: 等待新的I/O事件,node在一些特殊情况下会阻塞在这里。
- check:
setImmediate()的回调会在这个阶段执行。 - close callbacks: 例如
socket.on('close', ...)这种close事件的回调。
下面我们来按照代码第一次进入libuv引擎后的顺序来详细解说这些阶段:
poll阶段
当个v8引擎将js代码解析后传入libuv引擎后,循环首先进入poll阶段。poll阶段的执行逻辑如下: 先查看poll queue中是否有事件,有任务就按先进先出的顺序依次执行回调。 当queue为空时,会检查是否有setImmediate()的callback,如果有就进入check阶段执行这些callback。但同时也会检查是否有到期的timer,如果有,就把这些到期的timer的callback按照调用顺序放到timer queue中,之后循环会进入timer阶段执行queue中的 callback。 这两者的顺序是不固定的,收到代码运行的环境的影响。如果两者的queue都是空的,那么loop会在poll阶段停留,直到有一个i/o事件返回,循环会进入i/o callback阶段并立即执行这个事件的callback。
值得注意的是,poll阶段在执行poll queue中的回调时实际上不会无限的执行下去。有两种情况poll阶段会终止执行poll queue中的下一个回调:1.所有回调执行完毕。2.执行数超过了node的限制。
check阶段
check阶段专门用来执行setImmediate()方法的回调,当poll阶段进入空闲状态,并且setImmediate queue中有callback时,事件循环进入这个阶段。
close阶段
当一个socket连接或者一个handle被突然关闭时(例如调用了socket.destroy()方法),close事件会被发送到这个阶段执行回调。否则事件会用process.nextTick()方法发送出去。
timer阶段
这个阶段以先进先出的方式执行所有到期的timer加入timer队列里的callback,一个timer callback指得是一个通过setTimeout或者setInterval函数设置的回调函数。
I/O callback阶段
如上文所言,这个阶段主要执行大部分I/O事件的回调,包括一些为操作系统执行的回调。例如一个TCP连接生错误时,系统需要执行回调来获得这个错误的报告。
4.process.nextTick,setTimeout与setImmediate的区别与使用场景
在node中有三个常用的用来推迟任务执行的方法:process.nextTick,setTimeout(setInterval与之相同)与setImmediate
这三者间存在着一些非常不同的区别:
process.nextTick()
尽管没有提及,但是实际上node中存在着一个特殊的队列,即nextTick queue。这个队列中的回调执行虽然没有被表示为一个阶段,当时这些事件却会在每一个阶段执行完毕准备进入下一个阶段时优先执行。当事件循环准备进入下一个阶段之前,会先检查nextTick queue中是否有任务,如果有,那么会先清空这个队列。与执行poll queue中的任务不同的是,这个操作在队列清空前是不会停止的。这也就意味着,错误的使用process.nextTick()方法会导致node进入一个死循环。。直到内存泄漏。
那么合适使用这个方法比较合适呢?下面有一个例子:
1 | const server = net.createServer(() => {}).listen(8080); |
这个例子中当,当listen方法被调用时,除非端口被占用,否则会立刻绑定在对应的端口上。这意味着此时这个端口可以立刻触发listening事件并执行其回调。然而,这时候on('listening)还没有将callback设置好,自然没有callback可以执行。为了避免出现这种情况,node会在listen事件中使用process.nextTick()方法,确保事件在回调函数绑定后被触发。
setTimeout()和setImmediate()
在三个方法中,这两个方法最容易被弄混。实际上,某些情况下这两个方法的表现也非常相似。然而实际上,这两个方法的意义却大为不同。
setTimeout()方法是定义一个回调,并且希望这个回调在我们所指定的时间间隔后第一时间去执行。注意这个“第一时间执行”,这意味着,受到操作系统和当前执行任务的诸多影响,该回调并不会在我们预期的时间间隔后精准的执行。执行的时间存在一定的延迟和误差,这是不可避免的。node会在可以执行timer回调的第一时间去执行你所设定的任务。
setImmediate()方法从意义上将是立刻执行的意思,但是实际上它却是在一个固定的阶段才会执行回调,即poll阶段之后。有趣的是,这个名字的意义和之前提到过的process.nextTick()方法才是最匹配的。node的开发者们也清楚这两个方法的命名上存在一定的混淆,他们表示不会把这两个方法的名字调换过来—因为有大量的node程序使用着这两个方法,调换命名所带来的好处与它的影响相比不值一提。
setTimeout()和不设置时间间隔的setImmediate()表现上及其相似。猜猜下面这段代码的结果是什么?
1 | setTimeout(() => { |
实际上,答案是不一定。没错,就连node的开发者都无法准确的判断这两者的顺序谁前谁后。这取决于这段代码的运行环境。运行环境中的各种复杂的情况会导致在同步队列里两个方法的顺序随机决定。但是,在一种情况下可以准确判断两个方法回调的执行顺序,那就是在一个I/O事件的回调中。下面这段代码的顺序永远是固定的:
1 | const fs = require('fs'); |
答案永远是:
1 | immediate |
因为在I/O事件的回调中,setImmediate方法的回调永远在timer的回调前执行。
尾声
javascrit的事件循环是这门语言中非常重要且基础的概念。清楚的了解了事件循环的执行顺序和每一个阶段的特点,可以使我们对一段异步代码的执行顺序有一个清晰的认识,从而减少代码运行的不确定性。合理的使用各种延迟事件的方法,有助于代码更好的按照其优先级去执行。这篇文章期望用最易理解的方式和语言准确描述事件循环这个复杂过程,但由于作者自己水平有限,文章中难免出现疏漏。如果您发现了文章中的一些问题,欢迎在留言中提出,我会尽量回复这些评论,把错误更正。
16.Promise 原理
Promise 必须为以下三种状态之一:等待态(Pending)、执行态(Fulfilled)和拒绝态(Rejected)。一旦Promise 被 resolve 或 reject,不能再迁移至其他任何状态(即状态 immutable)。
基本过程:
- 初始化 Promise 状态(pending)
- 立即执行 Promise 中传入的 fn 函数,将Promise 内部 resolve、reject 函数作为参数传递给 fn ,按事件机制时机处理
- 执行 then(..) 注册回调处理数组(then 方法可被同一个 promise 调用多次)
- Promise里的关键是要保证,then方法传入的参数 onFulfilled 和 onRejected,必须在then方法被调用的那一轮事件循环之后的新执行栈中执行。
真正的链式Promise是指在当前promise达到fulfilled状态后,即开始进行下一个promise.
链式调用
先从 Promise 执行结果看一下,有如下一段代码:
1 | new Promise((resolve, reject) => { |
显然这里输出了不同的 data。由此可以看出几点:
- 可进行链式调用,且每次 then 返回了新的 Promise(2次打印结果不一致,如果是同一个实例,打印结果应该一致。
- 只输出第一次 resolve 的内容,reject 的内容没有输出,即 Promise 是有状态且状态只可以由pending -> fulfilled或 pending-> rejected,是不可逆的。
- then 中返回了新的 Promise,但是then中注册的回调仍然是属于上一个 Promise 的。
基于以上几点,我们先写个基于 PromiseA+ 规范的只含 resolve 方法的 Promise 模型:
1 | function Promise(fn){ |
这个模型简单易懂,这里最关键的点就是在 then 中新创建的 Promise,它的状态变为 fulfilled 的节点是在上一个 Promise的回调执行完毕的时候。也就是说当一个 Promise 的状态被 fulfilled 之后,会执行其回调函数,而回调函数返回的结果会被当作 value,返回给下一个 Promise(也就是then 中产生的 Promise),同时下一个 Promise的状态也会被改变(执行 resolve 或 reject),然后再去执行其回调,以此类推下去…链式调用的效应就出来了。
但是如果仅仅是例子中的情况,我们可以这样写:
1 | new Promise((resolve, reject) => { |
实际上,我们常用的链式调用,是用在异步回调中,以解决”回调地狱”的问题。如下例子:
1 | new Promise((resolve, reject) => { |
用上面的 Promise 模型,得到的结果显然不是我们想要的。认真看上面的模型,执行 callback.resolve 时,传入的参数是 callback.onFulfilled 执行完成的返回,显然这个测试例子返回的就是一个 Promise,而我们的 Promise 模型中的 resolve 方法并没有特殊处理。那么我们将 resolve 改一下:
1 | function Promise(fn){ |
用这个模型,再测试我们的例子,就得到了正确的结果:
1 | new Promise((resolve, reject) => { |
显然,新增的逻辑就是针对 resolve 入参为 Promise 的时候的处理。我们观察一下 test 里面创建的 Promise,它是没有调用 then方法的。从上面的分析我们已经知道 Promise 的回调函数就是通过调用其 then 方法注册的,因此 test 里面创建的 Promise 其回调函数为空。
显然如果没有回调函数,执行 resolve 的时候,是没办法链式下去的。因此,我们需要主动为其注入回调函数。
我们只要把第一个 then 中产生的 Promise 的 resolve 函数的执行,延迟到 test 里面的 Promise 的状态为 onFulfilled 的时候再执行,那么链式就可以继续了。所以,当 resolve 入参为 Promise 的时候,调用其 then 方法为其注入回调函数,而注入的是前一个 Promise 的 resolve 方法,所以要用 call 来绑定 this 的指向。
基于新的 Promise 模型,上面的执行过程产生的 Promise 实例及其回调函数,可以用看下表:
| Promise | callback |
|---|---|
| P1 | [{onFulfilled:c1(第一个then中的fn),resolve:p2resolve}] |
| P2 (P1 调用 then 时产生) | [{onFulfilled:c2(第二个then中的fn),resolve:p3resolve}] |
| P3 (P2 调用 then 时产生) | [] |
| P4 (执行c1中产生[调用 test ]) | [{onFulfilled:p2resolve,resolve:p5resolve}] |
| P5 (调用p2resolve 时,进入 then.call 逻辑中产生) | [] |
有了这个表格,我们就可以清晰知道各个实例中 callback 执行的顺序是:
c1 -> p2resolve -> c2 -> p3resolve -> [] -> p5resolve -> []
以上就是链式调用的原理了。
reject
下面我们再来补全 reject 的逻辑。只需要在注册回调、状态改变时加上 reject 的逻辑即可。
完整代码如下:
1 | function Promise(fn){ |
异常处理
异常通常是指在执行成功/失败回调时代码出错产生的错误,对于这类异常,我们使用 try-catch 来捕获错误,并将 Promise 设为 rejected 状态即可。
handle代码改造如下:
1 | function handle(callback){ |
我们实际使用时,常习惯注册 catch 方法来处理错误,例:
1 | new Promise((resolve, reject) => { |
实际上,错误也好,异常也罢,最终都是通过reject实现的。也就是说可以通过 then 中的错误回调来处理。所以我们可以增加这样的一个 catch 方法:
1 | function Promise(fn){ |
Finally方法
在实际应用的时候,我们很容易会碰到这样的场景,不管Promise最后的状态如何,都要执行一些最后的操作。我们把这些操作放到 finally 中,也就是说 finally 注册的函数是与 Promise 的状态无关的,不依赖 Promise 的执行结果。所以我们可以这样写 finally 的逻辑:
1 | function Promise(fn){ |
resolve 方法和 reject 方法
实际应用中,我们可以使用 Promise.resolve 和 Promise.reject 方法,用于将于将非 Promise 实例包装为 Promise 实例。如下例子:
1 | Promise.resolve({name:'winty'}) |
这些情况下,Promise.resolve 的入参可能有以下几种情况:
- 无参数 [直接返回一个resolved状态的 Promise 对象]
- 普通数据对象 [直接返回一个resolved状态的 Promise 对象]
- 一个Promise实例 [直接返回当前实例]
- 一个thenable对象(thenable对象指的是具有then方法的对象) [转为 Promise 对象,并立即执行thenable对象的then方法。]
基于以上几点,我们可以实现一个 Promise.resolve 方法如下:
1 | function Promise(fn){ |
Promise.reject与Promise.resolve类似,区别在于Promise.reject始终返回一个状态的rejected的Promise实例,而Promise.resolve的参数如果是一个Promise实例的话,返回的是参数对应的Promise实例,所以状态不一 定。 因此,reject 的实现就简单多了,如下:
1 | function Promise(fn){ |
Promise.all
入参是一个 Promise 的实例数组,然后注册一个 then 方法,然后是数组中的 Promise 实例的状态都转为 fulfilled 之后则执行 then 方法。这里主要就是一个计数逻辑,每当一个 Promise 的状态变为 fulfilled 之后就保存该实例返回的数据,然后将计数减一,当计数器变为 0 时,代表数组中所有 Promise 实例都执行完毕。
1 | function Promise(fn){ |
Promise.race
有了 Promise.all 的理解,Promise.race 理解起来就更容易了。它的入参也是一个 Promise 实例数组,然后其 then 注册的回调方法是数组中的某一个 Promise 的状态变为 fulfilled 的时候就执行。因为 Promise 的状态只能改变一次,那么我们只需要把 Promise.race 中产生的 Promise 对象的 resolve 方法,注入到数组中的每一个 Promise 实例中的回调函数中即可。
1 | function Promise(fn){ |
总结
Promise 源码不过几百行,我们可以从执行结果出发,分析每一步的执行过程,然后思考其作用即可。其中最关键的点就是要理解 then 函数是负责注册回调的,真正的执行是在 Promise 的状态被改变之后。而当 resolve 的入参是一个 Promise 时,要想链式调用起来,就必须调用其 then 方法(then.call),将上一个 Promise 的 resolve 方法注入其回调数组中。
补充说明
虽然 then 普遍认为是微任务。但是浏览器没办法模拟微任务,目前要么用 setImmediate ,这个也是宏任务,且不兼容的情况下还是用 setTimeout 打底的。还有,promise 的 polyfill (es6-promise) 里用的也是 setTimeout。因此这里就直接用 setTimeout,以宏任务来代替微任务了。
参考资料
完整 Promise 模型
1 | function Promise(fn) { |
17.Generators原理
随着 Javascript 语言的发展,ES6 规范为我们带来了许多新的内容,其中生成器 Generators 是一项重要的特性。利用这一特性,我们可以简化迭代器的创建,更加令人兴奋的,是 Generators 允许我们在函数执行过程中暂停、并在将来某一时刻恢复执行。这一特性改变了以往函数必须执行完成才返回的特点,将这一特性应用到异步代码编写中,可以有效的简化异步方法的写法,同时避免陷入回调地狱。
本重点探讨 Generators 运行机制及在 ES5 的实现原理。
1.Generators 简单介绍
一个简单的 Generator 函数示例
1 | function* example() { |
上述代码中定义了一个生成器函数,当调用生成器函数 example() 时,并非立即执行该函数,而是返回一个生成器对象。每当调用生成器对象的.next() 方法时,函数将运行到下一个 yield 表达式,返回表达式结果并暂停自身。当抵达生成器函数的末尾时,返回结果中 done 的值为 true,value 的值为 undefined。我们将上述 example() 函数称之为生成器函数,与普通函数相比二者有如下区别
- 普通函数使用 function 声明,生成器函数用 function*声明
- 普通函数使用 return 返回值,生成器函数使用 yield 返回值
- 普通函数是 run to completion 模式,即普通函数开始执行后,会一直执行到该函数所有语句完成,在此期间别的代码语句是不会被执行的;生成器函数是 run-pause-run 模式,即生成器函数可以在函数运行中被暂停一次或多次,并且在后面再恢复执行,在暂停期间允许其他代码语句被执行
2.Generators in C#
生成器不是一个新的概念,我最初接触这一概念是在学习使用 C#时。C#从 2.0 版本便引入了 yield 关键字,使得我们可以更简单的创建枚举数和可枚举类型。不同的是 C#中未将其命名为生成器 Generators,而将其称之为迭代器。
本文不会介绍 C#中可枚举类 IEnumerable 和枚举数 IEnumerator 内容,如需了解推荐阅读《C#4.0 图解教程》相关章节。
2.1 C#迭代器介绍
让我们先看一个示例,下面方法声明实现了一个产生和返回枚举数的迭代器
1 | public IEnumerable <int> Example() |
方法定义与 ES6 Generators 定义很接近,定义中声明返回了一个 int 类型的泛型可枚举类型,方法体内通过 yield return 语句返回值并将自身暂停执行。
使用迭代器来创建可枚举类型的类
1 | class YieldClass |
上述代码会产生如下输入
1 | 1 |
2.2 C#迭代器原理
在.Net 中,yield 并不是.Net runtime 的特性,而是一个语法糖,代码编译时,这一语法糖会被 C#编译器编译成简单的 IL 代码。
继续研究上述示例,通过 Reflector 反编译工具可以看到,编译器为我们生成了一个带有如下声明的内部类
1 | [CompilerGenerated] |
原始的 Example() 方法仅返回一个 YieldEnumerator 的实例,并将初始状态-2 传递给它自身和其引用者,每一个迭代器保存一个状态指示
- -2:初始化为可迭代类 Enumerable
- -1: 迭代结束
- 0: 初始化为迭代器 Enumerator
- 1-n: 原始 Example() 方法中的 yield return 索引值
Example() 方法中代码被转换为 YieldingEnumerator.MoveNext(),在我们的示例中转换后代码如下
1 | bool MoveNext() |
利用上述的代码转换,编译器为我们生成了一个状态机,正是基于这一状态机模型,实现了 yield 关键字的特性。
迭代器状态机模型可如下图所示

- Before 为迭代器初始状态
- Running 为调用 MoveNext 后进入这个状态。在这个状态,枚举数检测并设置下一项的位置。遇到 yield return、yield break 或者迭代结束时,退出该状态
- Suspended 为状态机等待下次调用 MoveNext 的状态
- After 为迭代结束的状态
3.Generators in Javascript
通过阅读上文,我们了解了 Generator 在 C#中的使用,并且通过查看编译器生成的 IL 代码,得知编译器会生成一个内部类来保存上下文信息,然后将 yield return 表达式转换成 switch case,通过状态机模式实现 yield 关键字的特性。
3.1 Javascript Generators 原理浅析
yield 关键字在 Javascript 中如何实现呢?
首先,生成器不是线程。支持线程的语言中,多段不同的代码可以在同一时候运行,这经常会导致资源竞争,使用得当会有不错的性能提升。生成器则完全不同,Javascript 执行引擎仍然是一个基于事件循环的单线程环境,当生成器运行的时候,它会在叫做 caller 的同一个线程中运行。执行的顺序是有序、确定的,并且永远不会产生并发。不同于系统的线程,生成器只会在其内部用到 yield 的时候才会被挂起。
既然生成器并非由引擎从底层提供额外的支持,我们可以沿用上文在 C#中对 yield 特性的原理探究的经验,将生成器视为一个语法糖,用一个辅助工具将生成器函数转换为普通的 Javascript 代码,在经过转换的代码中,有两个关键点,一是要保存函数的上下文信息,二是实现一个完善的迭代方法,使得多个 yield 表达式按序执行,从而实现生成器的特性。
3.2 How Generators work in ES5
Regenerator 工具已经实现了上述思路,借助 Regenerator 工具,我们已经可以在原生 ES5 中使用生成器函数,本节我们来分析 Regenerator 实现方式以深入理解 Generators 运行原理。
通过这个在线地址可以方便的查看经过转换后的代码,仍然以文章初始为例
1 | function* example() { |
经过转换后为
1 | var marked0$0 = [example].map(regeneratorRuntime.mark); |
从转换后的代码中可以看到,与 C#编译器对 yield return 表达式的转换相似,Regenerator 将生成器函数中的 yield 表达式重写为 switch case,同时,在每个 case 中使用 context$1$0 来保存函数当前的上下文状态。
switch case 之外,迭代器函数 example 被 regeneratorRuntime.mark 包装,返回一个被 regeneratorRuntime.wrap 包装的迭代器对象。
1 | runtime.mark = function(genFun) { |
通过 mark 包装,将 example 包装成如下对象
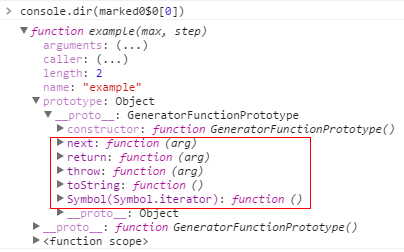
当调用生成器函数 example() 时,返回一个被 wrap 函数包装后的迭代器对象
1 | runtime.wrap=function (innerFn, outerFn, self, tryLocsList) { |
返回的迭代器对象如下所示
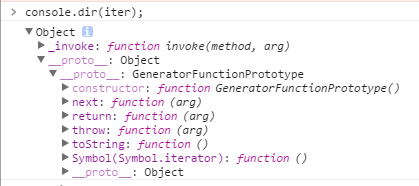
当调用迭代器对象 iter.next() 方法时,因为有如下代码,所以会执行_invoke 方法,而根据前面 wrap 方法代码可知,最终是调用了迭代器对象的 makeInvokeMethod (innerFn, self, context); 方法
1 | // Helper for defining the .next, .throw, and .return methods of the |
makeInvokeMethod 方法内容较多,这里选取部分分析。首先,我们发现生成器将自身状态初始化为“Suspended Start”
1 | function makeInvokeMethod(innerFn, self, context) { |
makeInvokeMethod 返回 invoke 函数,当我们执行.next 方法时,实际调用的是 invoke 方法中的下面语句
1 | var record = tryCatch(innerFn, self, context); |
这里 tryCatch 方法中 fn 为经过转换后的 example$方法,arg 为上下文对象 context, 因为 invoke 函数内部对 context 的引用形成闭包引用,所以 context 上下文得以在迭代期间一直保持。
1 | function tryCatch(fn, obj, arg) { |
tryCatch 方法会实际调用 example$方法,进入转换后的 switch case, 执行代码逻辑。如果得到的结果是一个普通类型的值,我们将它包装成一个可迭代对象格式,并且更新生成器状态至 GenStateCompleted 或者 GenStateSuspendedYield
1 | var record = tryCatch(innerFn, self, context); |
4. 总结
通过对 Regenerator 转换后的生成器代码及工具源码分析,我们探究了生成器的运行原理。Regenerator 通过工具函数将生成器函数包装,为其添加如 next/return 等方法。同时也对返回的生成器对象进行包装,使得对 next 等方法的调用,最终进入由 switch case 组成的状态机模型中。除此之外,利用闭包技巧,保存生成器函数上下文信息。
上述过程与 C#中 yield 关键字的实现原理基本一致,都采用了编译转换思路,运用状态机模型,同时保存函数上下文信息,最终实现了新的 yield 关键字带来的新的语言特性。
参考文章
1.ES6 Generators:Complete Series 系列文章
3.《深入掌握 ECMAScript 6 异步编程》系列文章